In this column/analysis, The Semiconductor Golden Era I wrote in January, I outlined how the next decade would yield more creative and innovative semiconductor designs than anything we saw in the race for performance era of the past few decades. We have enough CPU performance, and we will still see innovation in GPU design, but the overall trend is moving to efficiency around new use cases. Machine learning at the forefront.
In early February, Arm did something interesting that I have a hunch will set a new trend in silicon designs. Arm announced something called Project Trillium. One I find most interesting about Arm’s newest architecture, is how it has been designed from the ground up with machine learning in mind.
Companies like Apple, Qualcomm, and Intel have been adding tweaks to their existing architectures to support machine learning. This is because the base architectures of the designs have legacy (pre-machine learning) elements. Arm is setting the trend for new architecture designs that are built from the ground up around machine learning. Machine learning use cases will touch every aspect of our computing lives so it makes sense that all semiconductor designs going forward will heavily leverage machine learning.
Arm’s new processor includes new efficient designs for things like computer vision (object recognition) and a Neural Network for on-device training and inference. It is worth noting that both those things are being done today by computers. However, they are being done with pre-machine learning silicon architectures. Which means we could see multiples in performance in the same tasks done today with these new designs built for machine learning tasks.
The observation that today’s chips were not architected from the ground up with machine learning in mind is the point that stands out the most to me. Especially with how much machine learning is part of nearly every conversation about the future of technology and computing. This is why I’m convinced we will see everyone designing semiconductors do so with machine learning optimization and focus in mind.
If you know how Arm works, you know that companies can take these designs they release, license them and use the base designs for their implementations of silicon. Notably, Apple and Qualcomm benefit from new efficiency and innovations from Arm and take those base designs and customize them for their vision of where computing is going. This is the main reason why I feel it is safe to assume we will see machine learning focused semiconductor designs start to infiltrate all our computing devices.
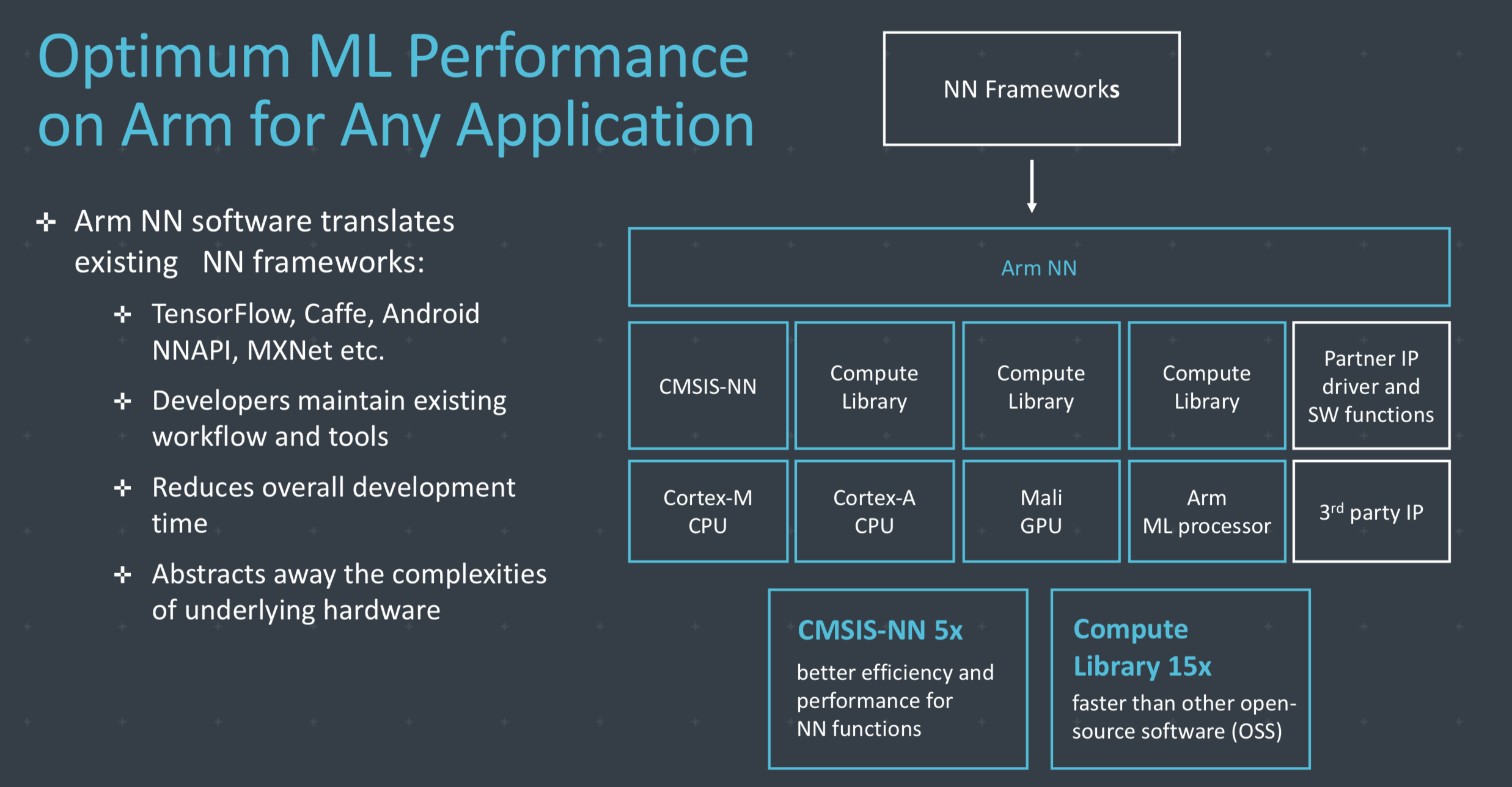
Arm’s commitment to open standards is a big reason their licensees will benefit from this. The chart below gives a good example of what they are enabling around machine learning focused silicon designs and open standards.

When you look at this overly simplified block diagram of the components of these Project Trillium designs you see the modularity options of this new architecture. Companies like Apple, Qualcomm, even Samsung, etc., can take this entire design and add their custom bits to it. For example, Apple can swap out their customized A series processors and their in-house GPU design and still use the other parts they choose and still support all the open standards in machine learning programming languages and libraries. Qualcomm can do the same as can Samsung and other licensees. These architectures are entirely flexible to be customized as needed for the implementation desires of the licensee.
Of course, Apple and Qualcomm can simply do their ground-up designs of silicon with a machine learning focus if they so choose. My hunch is they will leverage some of this work by Arm and keep customizing the bits most important to them vs. an entirely new architecture of their own using basic Arm IP. Either way, if this does indeed happen, my point remains intact that we will see machine learning influence new semiconductor designs going forward.
This trend will not be limited to just the Arm ecosystem. I fully expect Intel, and AMD, to start to weave machine learning efficient designs and innovations into their x86 designs as well. While everyone will still use some companion processor designs, like Apple does today, I think we will see the main CPU core and GPU core start to be designed in conjunction with any dedicated machine learning co-processor for added efficiency.
The goal here is speed in machine learning training data and the interpretation/results of that data. In 10 years or so, we will look back at where we are today with computational speed for machine learning, and it will feel like the days of the Internet being 24/56k–meaning we are in archaic days of machine learning computational capabilities. I have no doubt we will look back at this point as the inflection when machine learning focused designs were implemented into silicon as the reason we move point A to point B in machine learning computational efficiency and speed.