
During the early computer era of the 1960s, it was thought there would only be the need for a few dozen computers. By the 1970s, there were just over 50,000 computers in the world.
Computers have grown in power by orders of magnitude since. They have become more intelligent in the way they interact with humans, starting with switches and buttons then punch cards and on to the keyboard. Along the way, we added joysticks, the mouse, track pads and the touch screen.

Newspaper image projecting the number of computers in the world in 1967
As each paradigm replaced the last, productivity and utility. In some cases, we cling on to the prior generation’s system to such a degree we think the replacement is little more than a novelty or a toy. For example, when the punch card was the fundamental input system to computers, many computer engineers thought a direct keyboard connection to a computer was “redundant” and pointless because punch cards could move through the chute guides 10 times faster than the best typists at the time [1]. The issue is we see the future through the eyes of the prior paradigms.

Punch card stack of customer data
We Had To Become More Like The Computer Than The Computer had to Become More Like Us
All prior computer interaction systems have one central point in common. They force humans to be more like the computer by forcing the operator to think through arcane commands and procedures. We take it for granted and forget the ground rules we all had to learn and continue to learn to use our computers and devices. I equate this to learning any arcane language that requires new vocabularies as new operating systems are released and new or updated applications are available.
Is typing and gesturing the most efficient way to interact with a computer or device for the vastly most common uses most people have? All of the cognitive (mental energy) and mechanical (physical energy) loads we must induce for even trivial daily routines is disproportionately high for what can be distilled to a yes or no answer. When seen for what it truly is, these old ways are inefficient and ineffective for many of the common things we do with devices and computers.

IBM Keypunch station to encode Punch Cards
What if we didn’t need to learn arcane commands? What if you could use the most effective and powerful communication tool ever invented? This tool evolved over millions of years and allows you to express complex ideas in very compact and data dense ways yet can be nuanced to the width of a hair [2]. What is this tool? It is our voice.
The fundamental reason humans have been reduced to tapping on keyboards made of glass is simply because the computer was not powerful enough to understand our words let alone even begin to decode our intent.
It’s been a long road to get computers to understand humans. It started in the summer of 1952 at Bell Laboratories with Audrey (Automatic Digit Recognizer), the first speaker independent voice recognition system that decoded the phone number digits spoken over a telephone for automated operator assisted calls [3].
At the Seattle World’s Fair in 1962, IBM demonstrated its “Shoebox“ machine. It could understand 16 English words and was designed to be primarily a voice calculator. In the ensuing years there were hundreds of advancements [3].

IBM Shoebox voice recognition calculator
Most of the history of speech recognition was mired in speaker dependent systems that required the user to read a very long story or grouping of words. Even with this training, accuracy was quite poor. There were many reasons for this, much of it was based on the power of the software algorithms and processor power. But in the last 10 years, there have been more advancement than in the last 50. Additionally, continuous speech recognition, where you just talk naturally, has only been refined in the last 5 years.
The Rise Of The Voice First World
Voice based interactions have three advantages over current systems:
Voice is an ambient medium rather than an intentional one (typing, clicking, etc). Visual activity requires singular focused attention (a cognitive load) while speech allows us to do something else.
Voice is descriptive rather than referential. When we speak, we describe objects in terms of their roles and attributes. Most of our interactions with computers are referential.
Voice requires more modest physical resources. Voice based interaction can be scaled down to much smaller and much cheaper form-factors than visual or manual modalities.
The power of voice-based systems has grown powerful with the addition of always-on systems combined with machine learning (Artificial Intelligence), cloud-based computing power and highly optimized algorithms.
Modern speech recognition systems have combined with almost pristine Text-to-Speech voices that so closely resemble human speech, many trained dogs will take commands from the best systems. Viv, Apple’s Siri, Google Voice, Microsoft’s Cortana, Amazon’s Echo/Alexa, Facebook’s M and a few others are the best consumer examples of the combination of Speech Recognition and Text-to-Speech products today. This concept is central to a thesis I have been working on for over 30 years. I call it “Voice First” and it is part of an 800+ page manifesto I have built based around this concept. The Amazon Echo is the first clear Voice First device.
The Voice First paradigm will allow us to eliminate many, if not all, of these steps with just a simple question. This process can be broken out to 3 basic conceptual modes of voice interface operations:
Does Things For You – Task completion:
– Multiple Criteria Vertical and Horizontal searches
– On the fly combining of multiple information sources
– Real-time editing of information based on dynamic criteria
– Integrated endpoints, like ticket purchases, etc.
Understands What You Say – Conversational intent:
– Location context
– Time context
– Task context
– Dialog context
Understands To Know You – Learns and acts on personal information:
– Who are your friends
– Where do you live
– What is your age
– What do you like
In the cloud, there is quite a bit of heavy lifting working at producing an acceptable result. This encompasses:
- Location Awareness
- Time Awareness
- Task Awareness
- Semantic Data
- Out Bound Cloud API Connections
- Task And Domain Models
- Conversational Interface
- Text To Intent
- Speech To Text
- Text To Speech
- Dialog Flow
- Access To Personal Information And Demographics
- Social Graph
- Social Data
The current generation of voice-based computers have limits on what can be accomplished because you and I have become accustomed to doing all of the mechanical work of typing, viewing, distilling, discerning and understanding. When one truly analyzes the exact results we are looking for, most can be answered by a “Yes” or “No”. When the back-end systems correctly analyze your volition and intent, countless steps of mechanical and cognitive load is eliminated. We have recently entered into an epoch where all elements converged to make the full promise of an advanced voice interface truly arrive. W. Edwards Deming [4] quantified the many steps humans need to complete to achieve any task, This was made popular by his thesis of The Shewhart Cycles and PDSA (Plan-Do-Study-Act) Cycles we have become trained to follow when using any computer or software.
The Shorter Path: “Alexa, whats’s my commute look like?”
A Voice First system would operate on the question and calculate the route from the current location to the location that may be implied by time of day and typical destination.
An app system would require you to open your device, select the appropriate app, perhaps a map, localize your current location, pinch and zoom to the destination, scan the colors or icons that represent traffic and then estimate an acceptable insight based on taking in all the information viably present and determine the arrival time.
The implicit and explicit: From Siri And Alexa To Viv
Voice First systems fundamentally change the process by decoding volition and intent using self learning artificial intelligence. The first example of this technology was with Siri [5]. Prior to Siri, systems like Nuance [6] were limited to listening to audio and creating text. Nuance’s technology has roots in optical character recognition and table arrays. The core technology of Siri was not focused just on speech recognition but rather focused primarily on three functions that complement speech recognition:
- Understanding the intent (meaning) of spoken words and generating a dialog with the user in a way that maintains context over time, similar to how people have a dialog
- Once Siri understands what the user is asking for, it reasons how to delegate requests to a dynamic community of web services, prioritizing and blending results and actions from all of them
- Siri learns over time (new words, new partner services, new domains, new user preferences, etc.)
Siri was the result of over 40 years of research funded by DARPA. Siri Inc. was a spin off of SRI Intentional and was a standalone app before Apple acquired the company in 2011 [5].
Dag Kittlaus and Adam Cheyer were cofounders of Siri Inc. and originally planned to stay on and guide their vision on a Voice First system that motivated Steve Jobs to personally start negotiations with Siri Inc.
Siri has not lived up to the grand vision originally imagined by Steve. Although improving, there has yet to be a full API and skills performed by Siri have not yet matched the abilities of the original Siri app.
This set the stage for Amazon and the Echo product [7]. Amazon surprised just about everyone in technology when it was announced on November 6, 2014. This was an outgrowth of a Kindle e-book reader project that began in 2010 and the acquisition of voice platforms it acquired from Yap, Evi, and IVONA.

Amazon Echo circa 2015
The original premise of Echo was to be a portable book reader built around 7 powerful omni-directional microphones and a surprisingly good WiFi/Bluetooth speaker (with separate woofer and tweeter). This humble mission soon morphed into a far more robust solution that is just now taking form for most people.
Beyond the the power of the Echo hardware is the power of Amazon Web Services (AWS) [8]. AWS is one of the largest virtual computer platforms in the world. Echo simply would not work without this platform. The electronics in Echo are not powerful enough to parse and respond to voice commands without the millions of processors AWS has at its disposal. In fact, the digital electronics in Echo are centered around 5 chips and perform little more than recording a live stream to AWS servers and sending the resulting audio stream back to be played through the analog electronics and speakers on Echo.

Amazon Echo digital electronics board
Today with a run away hit on their hands, Amazon recently opened up the system for developers with the ASK program [10]. Amazon also has APIs that connect to an array of home automation systems. Yet simple things like building a shopping list and converting it to an order on Amazon is nearly impossible to do.

Sample of Alexa ASK skills flowchart
Echo is a step forward from the current incarnation of Siri, not so much for the sophistication of the technology or the open APIs, but for the single purpose dedicated Voice First design. This can be experienced after a few weeks of regular use. The always on, always ready low latency response creates a personality and a sense of reliance as you enter the space.
Voice First devices will span the simple to the complex to the reasonably sized to a form factor not much larger than a Lima beam.

Hypothetical Voice First device with all electronics in ear including microphone, speaker, computer, WiFi/Bluetooth and battery
The founders of Siri spent a few years thinking about the direction of Voice First software after they left Apple. The results of this thinking will begin with the first public demonstrate of Viv this spring. Viv [11] is the next generation from Dag and Adam picking up where Siri left off. Viv was developed at SixFive Labs, Inc (the stealth name of the company) with the inside “easter egg” element that the roman numerals are VI V gave a connection to the Viv name.
Viv is orders of magnitude more sophisticated in the way it will act on the dialog you create with it. The more advanced models of Ontological Recipes and self learning will make interactions with Viv more natural and intelligent. This is based upon a new paradigm the Viv team has created called “Exponential Programming”. They have filed many patents central to this concept. As Viv is used by thousand to millions of users, asking perhaps thousands of questions per second, the learning will grow exponentially in short order. Siri and the current voice platforms currently can’t do anything that coders haven’t explicitly programmed it for. Viv solves this problem with the “Dynamically Evolving Systems” architecture that operates directly on the nouns, pronouns, adjectives and verbs.
Viv flow chart example first appearing in Wired Magazine in 2015
Viv is an order of magnitude more useful than currently fashionable Chat Bots. Bots will co-exist as a subset to the more advanced and robust interactive paradigms. Many users will first be exposed to Chat Bots through the anticipated release of a complete Bot platform and Bot store by Facebook.
Viv’s power comes from how it models the lexicon of each sentence with each word in the dialog and acts on it in parallel to produce a response almost instantaneous. These responses will come in the form of a chained dialog that will allow for branching based on your answers.
Viv is built around three principles or “pillars”:
It will be taught by the world
it will know more than it is taught
it will learn something every day.
The experience with Viv will be far more fluid and interactive than any system publicly available. The results will be a system that will ultimately predict your needs and allow you to almost communicate in the shorthand dialogs found common in close relationships.
In The Voice First World, Advertising And Payments Will Not Exist As They Do Today
In the Voice First world many things change. Advertising and payments will particularly be changed and, in themselves, become new paradigms for both merchants and consumers. Advertising as we know it will not exist primarily because we would not tolerate commercial intrusions and interruptions in our dialogs. It would be equivalent to having a friend break into an advertisement about a new gasoline.
Payments will change in profound ways. Many consumer dialogs will have implicit and explicit layered Voice Payments with multiple payment type. Voice First systems will mediate and manage these situations based on a host of factors. Payments companies are not currently prepared for this tectonic shift. In fact, some notable companies are going in the opposite direction. The companies that prevail will have identified the Ontological Recipe technology to connect merchants to customers.
This new advertising and payments paradigm actually form a convergence. Voice Commerce will become the primary replacement for advertising and Voice Payments are the foundation to Voice Commerce. Ontologies [12] and taxonomies [13] will play an important part of Voice Payments. The shift will impact what we today call online, in-app and retail purchases. The least thought through of the changes is the impact on face to face retail when the consumer and the merchant interact with Voice First devices.
Of course Visa, MasterCard and American Express will play an important part of this future and all the payment companies between them and the merchant will need to rapidly change or truly be disrupted. The rate of change will be more massive and pervasive than anything that has come before.
This new advertising and payments paradigm will impact every element of how we interact with Voice First devices. Without human mediated searches on Google, there is no pay-per click. Without a scan of the headlines at your favorite news site, there is no banner advertising.
The Intelligent Agents
A major part of the Voice First paradigm is a modern Intelligent Agent (also known as Intelligent Assistant). Over time, all of us will have many, perhaps dozens, interacting with each other and acting on our behalf. These Intelligent Agents will be the “ghost in the machine” in Voice First devices. They will be dispatched independently of the fundamental software and form a secondary layer that can fluidly connect between a spectrum of services and systems.
Voice First Enhances The Keyboard And Display
Voice First devices will not eliminate display screens as they will still need to be present. However, they will be ephemeral and situational. The Voice Commerce system will present images, video and information for you to consider or evaluate on any available screen. Much like AirPlay but with locational intelligence.
There is also no doubt keyboards and touch screens will still exist. We will just use them less. Still, I predict in the next ten years, your voice is not going to navigate your device, it is going to replace your device in most cases.
The release of Viv will influence the Voice First revolution. Software and hardware will start arriving at an accelerated rate and existing companies will be challenged by startups toiling away in garages and on kitchen tables around the world. If Apple were so inclined, with about a month’s work and a simple WiFi/Bluetooth Speaker with a multi-axis microphone extension, the current Apple TV [14] could offer a wonderful Voice First platform. In fact, I have been experimenting with this combination with great success on a food ordering system. I have also been experimenting on the Amazon Echo platform and built over 45 projects, one of which is a commercial grade hotel room service application complete with food ordering and a virtual store and mini bar along with thermostat setting and light controls for a boutique luxury hotel chain.
I am in a unique position to see the Voice First road ahead because of my years as a voice researcher and payments expert. As a coder and data scientist for the last few months, I have built 100s of simple working demos in the top portion of the Voice First use cases.
A Company You Never Heard Of May Become The Apple Of Voice First
The future of Voice First is not really an Apple vs. Amazon vs. Viv situation. The market is huge and encompasses the entire computer industry. In fact, I assert many existing hardware and software companies will have a Voice First system in the next 24 months. In addition to companies like Amazon and Viv, the first wave already have a strong cloud and AI development background. However, the next wave, like much of the Voice First shift, will likely come from companies that have not yet started or are in the early stages today.
With the Apple TV, Apple has an obvious platform for the next Voice First system. The current system is significantly hindered as it does not typically talk back in the current TV-centered use case. There is also the Apple Watch with a similar impediment of its limitation in the voice interface — it doesn’t have any ability to talk back. I can see a next version with a useable speaker but centered around a Bluetooth headset for voice playback.
Amazon has a robust head start and has already activated the drive and creativity of the developer community. This inertia will continue and spread across non-Amazon devices. This has already started with Alexa on Raspberry PI [15], the $35 devices originally designed for students to learn to code but have now become the center of many products. Alexa is truly a Voice First system not tied to any hardware. I have developed many applications and hardware solutions using less than $30 worth of hardware on the Raspberry PI Zero platform.

One of My Raspberry PI Alexa + Echo experimentations with Voice Payments
Viv will, at the onset, be a software only product. Initially it will be accessed via apps that have licensed the technology. I also predict a deep linking into some operating systems. Ultimately if not acquired, Viv is likely to create reference grade devices that may rapidly gain popularity.
The first wave of Voice First devices will likely come from these companies with consumer grade and enterprise grade systems and devices:
- Apple
- Microsoft
- IBM
- Oracle
- Salesforce
- Samsung
- Sony
Emotional Interfaces
Voice is not the only element of the human experience making a comeback. In my 800 page voice manifesto I assert that emotional intent facial recognition, along with hand and body gestures, will become a critical addition to the integration of the Voice First future. Although just like voice, facial expression decoding sounds like a novelty. Our voices, combined with a decoding in real-time of the 43 muscles that form an array of expressions, can communicate not only deeper meaning but deeper understanding of volition and intent.

Microsoft Emotion API showing facial scoring
Microsoft’s Cognitive Services has a number of APIs centered around facial recognition. In particular, the Emotion API [15] is most useful. It is currently limited to a pallet of 8 basic emotions with a scoring system that allows weighting in each category in real-time. I have seen far more advanced systems in development that will track nuanced micro-movements to better understand emotional intent.
The Disappearing Computer And Device
Some argue voice systems will become an appendage to our current devices. These systems are currently present on many devices but they have failed to captivate on a mass scale. Amazon’s Echo captivates because of the dynamics present when Voice First defines a physical space. The room feels occupied by an intelligent presence. It is certain that existing devices will evolve. But it is also certain Voice First will enhance these devices and, in many cases, replace them.
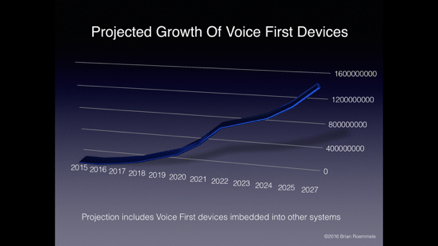
The growth of Voice First devices in 10 years will rival the growth of tablet sales
What becomes of the device, visual operating system, the app when there is little or no need to touch it? You can see just how disrupted the future is for just about every element of technology and business.
The Accelerating Rate Of Change
We have all rapidly acclimated to the accelerating rate of change this epoch has presented as exampled in the monumental shift from mechanical keyboards of cell phones, as typified by the Blackberry device of 2007 at the apex of its popularity and then shift to typing on a glass touch screen brought about with the iPhone release. All quarters, from the technological sophisticates to the common business user to the typical consumer, said they would never give up the world of the mechanical keyboard [16]. Yet, they did. By 2012, the shift had become so cemented in the direction of glass touch screens and simulated keyboards, no one was going backwards. In ten years, few will remember the tremendous amount of cognitive and mechanical steps we went through just to glean simple answers.

Typical iPhone vs. Blackberry comparisons in 2008
One Big Computer As One Big Brain
In many ways we have come full circle to the predictions made in the 1960s that there will be no need for more than a few dozen computers in the world. The huge AI self-learning systems like Viv will use the “hive mind” of the crowd. Some predict it will render our local computers little more than “dumb pipes” with a conduit to one or a few very smart computers in the cloud. We will all face the positive and the negative aspects this will bring.
In 2016, we are at the precipice of something grand and historic. Each improvement in the way we interact with computers brought about long term effects nearly impossible to calculate. Each improvement of computer interaction lowered the bar for access to a larger group. Each improvement in the way we interact with computers stripped away the priesthoods, from the 1960s computer scientists on through to today’s data science engineers. Each improvement democratized access to vast storehouses of information and potentially knowledge.
The last 60 years of computing humans were adapting to the computer. The next 60 years the computer will adapt to us. It will be our voices that will lead the way; it will be a revolution.
______
[1] http://www.columbia.edu/cu/computinghistory/fisk.pdf
[2] https://en.wikipedia.org/wiki/Origin_of_speech
[3] http://en.citizendium.org/wiki/Speech_Recognition
[4] https://en.wikipedia.org/wiki/W._Edwards_Deming
[5] http://qr.ae/RUWZH7
[6] https://en.wikipedia.org/wiki/Nuance_Communications
[7] http://qr.ae/RUWSGC
[8] https://en.wikipedia.org/wiki/Amazon_Web_Services
[9] https://en.wikipedia.org/wiki/Amazon.com#Amazon_Prime
[10] https://developer.amazon.com/appsandservices/solutions/alexa/alexa-skills-kit
[11] http://viv.ai
[12] https://en.wikipedia.org/wiki/Ontology_%28information_science%29
[13] https://en.wikipedia.org/wiki/Taxonomy_(general)
[14] https://en.wikipedia.org/wiki/Apple_TV
[15] https://www.microsoft.com/cognitive-services/en-us/emotion-api
[16] http://crackberry.com/top-10-reasons-why-iphone-still-no-blackberry
Why not make Alexa hands free? Voice first devices seem problematic.
Hi Vadim, great point. Alexa and the Voice First devices I predict will be hands-free and always on.
A voice based interface would be useful in some situations, but worse than useless in others.
In an office environment, you don’t want to distract other people trying to work by saying “open the spreadsheet, go to column 80, change 4 to 8, recalculate.” Unless the office environment abandons cubicles in favour of offices with doors that close (yeah, right), dictation based UI is not going to go over well.
In public, you don’t want to let anyone nearby who stops to listen to hear you dictating your private messages to the machine. Actually, you don’t want your friends or family members to hear you dictating your IMs, either. So make that “anywhere you aren’t completely alone, you don’t want this.”
There’s also the problem that talking is a more wooly and vague form of communication than typing. Because we can see the words we have written, it helps guide and channel the flow of thoughts, whereas talking is a lot more free wheeling and less cogent. I can say from experience that dictating an email that reads in a clear and professional manner is quite a bit more difficult than just typing the damn thing.
Finally, speech first or speech only is a foolish goal because there are so many things we ask computers to do that are hard to put into words, but easy to put into gestures — it’s a lot easier to mouse or tap to indicate what part of the image needs to be zoomed in on than to say “zoom in on the lower two thirds left hand quadrant, no more to the left,” and so on.
I understand your point. The part that may be overlooked is the AI. You will not really be replacing typing with dictation. The AI will parse what you are doing via Intelligent Agents, that already exist today and formulate a response. The example of typing a letter would be the similar path that is part of all high end CRM systems where the context of the message is analyzed and a grouping of responses are presented for response. Some are so well done that almost no human interaction is required and the messages are far more responsive and personalized then a distracted and perhaps uninterested worker would compose. This is already here adding voice to make it more efficient is the big part.
As for navigation. We navigate to get at information to draw a conclusion. Ask yourself in a vast majority of cases is the conclusion really just a binary yes or no? A spread sheet example you present, you ask “Did we lose money in August?” “What sales groups are doing best?’ etc. This is not voice just replacing a manual process it is voice directing AI.
In the case of navigation of information on the screen, the context would be relevant. The system would understand the context and anticipate what should be branched from each situation.
As for an office environment, people are known to talk on a phone in these environments and have constant conversations with fellow workers. This is 99% of office environments. There is little difference talking to a very intelligent and anticipating Voice First system.
Finally screens do not disappear, even manual entry does not disappear. Air gestures would guide some of the responses as screens will be present to review information that needs to be displayed.
In the end what changes is AI makes all things more anticipating removing humans from manual processes using a compact and efficient millions of year old interface, the human voice.
My parents are getting on in age, to the point were eyesight and touch are failing. I figured Google Voice would be nice for them: no more typing, dialing, looking for icons.. it works fine for me.
Total failure., 3 main reasons
1- it gets confused by other voices. Even a male voice on the TV at the other end of the room messes up its recog of my mom’s voice.
2- Real People ™ stutter, mumble, hesitate, interject. “Google, when is the next HEY, GET SOME MILK TOO PLEASE, hum, next showing of Boyhood ?”
3- it needs online
“There will be no need for more than a few dozen computers in the world.”
The statement will only be true if you claim the phones everybody uses – with their ever-increasing power – are not computers. Brian Roemmele, the author of an “800 page voice manifesto” should try saying that to Tim Cook.
That statement was one made in history predicting how many PCs would be the world. Brian was not saying that he was referencing a quote from history.
Sounds like Skynet is getting closer.
Fascinating article. Thank you.
It seems to me as that ‘always on,’ ‘always listening’ technology streaming my life’s details into the web is incredibly invasive. I am not, and I hope the world is not, ready to hand all personal information to some hive computer in the sky.
And voice-based payments… What could possibly go wrong with that? How many thousands of ways could that be hacked?
Technology for technology’s sake is a foolish idea.
There are many great things that may come from advancements in voice recognition. But to project that all device-based interactions will someday have a cloud component is insane.
This is a solution to a non-existent problem that creates more problems than it solves.
I hear ya. Turns out this is exactly what Amazon Echo does. It is also one of the reasons it became an astounding success over the last year. Indeed I have many doubts about what happens with the information that become exformation. Thus far Amazon has a number of tools to show you what was heard and to have it removed from the short term cache. Voice payments like any modern payment system will have a number of rather robust safeguards. Some will be obvious and some will be less obvious. As it stands today, there are 3 stealth startups that are working on voice print identity with some variations. Amazon has tested voice print identity and has a discrimination of 99%. Also can detect if you are actually in the room or a recording is being played back. No for of payments is 100% secure, even Blockchain to some degree.
The cloud component is the only way currently that all the modern voice recognition devices operate. For example Echo has no local voice synthesizer nor does it decode the speech. From this stand point it is little more than a conduit for the club computer that creates an audio file on the file to respond to the audio file assembled locally and parsed in the cloud. Moore’s law will meet this at some point but that will be in the later part of 10 years.
I think this whole program of trying to make computers think more like humans is ill-conceived and headed totally in the wrong direction.
The tedium and fussiness of having to use arcane, finicky, and precisely defined commands to get the computer to do what we want it to do, i.e. solve some problem, has a benefit that most people overlook: it forces the programmer to meticulously break down and analyse the problem being solved. That is, it enforces mental discipline and clear thinking leading to in depth understanding of the problem being solved. This in turn forces us to jettison preconceived notions, intellectual prejudices, and errors arising from logical shortcuts.
If computers somehow are made to think like humans (which I think will never happen, at best they can be made to appear as if they think like humans.), won’t they make the same mental mistakes that humans make? For example, intuition is an amazing mental process. It enables us to come up with completely unexpected but highly effective solutions to problems. But it can also lead to horrendous blunders. Do we really want computers to be making such blunders? Instead of computers being a machine that forces us to be disciplined thinkers, it becomes a machine that commits the same mental errors that humans are prone to.
I understand. The thing is as you stated:
“precisely defined commands to get the computer to do what we want it to do, i.e. solve some problem, has a benefit that most people overlook: it forces the programmer to meticulously break down and analyse the problem being solved”
In the Voice First world driven by AI and dynamic learning, it is precisely the computer that “meticulously break down and analyse the problem being solved” the computer has far more discipline,less distractions and dynamic notions with no intellectual prejudices.
We can drag a garden hoe through a field or we can sit atop a combine in a cubicle that computer controls the lines being cut with GPS+ accuracy based on 10 data points like exact elevation and 100 year flood plains. We are moving from the field and to the top of the combine with Voice First + AI.
Computers are not being made to think like humans, as you stated this will likely and hopefully never happen. Computers will learn to understand us, rather then like I stated in the last 60 years we were forced to think like them. Just like the farmer, we can remove ourselves from the manual labor of typing and and viewing to stating what we need and letting the computer decode volition and intent. Over time this understanding grows. We get about the business of hopefully doing better things.
“Over time this understanding grows.” And in the meantime we allow the computer to make mistakes as it “learns”? Language evolves, and even if the computer learns the current meaning of words and phrases, what if a word meaning shifts and the user is using the new meaning while the computer understands it to be the old? “Hook up” is an example of a phrase whose meaning has shifted a non-trivial way. (Although it’s probably not relevant in the context of interfacing with a computer. At least I hope so.)
What if the mistake resulting from the computer misunderstanding the user has severe consequences? The precaution to take, of course. is not to issue any command using the word in it’s new meaning because the computer will misunderstand you. But then that’s back to us “thinking like computers rather than computers thinking like us.” The old way though, we probably have a clearer idea of whether or not the computer precisely understands the commands we issued, the new way being proposed, which I presume, perhaps mistakenly, is all about natural language commands, we’ll always wonder whether a new command we issue will be precisely understood.
This statement “stating what we need and letting the computer decode volition and intent” is, I think, not truly attainable. At best we can only make a very good simulation of it.
I appreciate your insights.
You and I use the same system Al uses. In fact, the hardest task humans overcome with no “intelligence” is the profoundly almost impossible task of learning to walk. It is pure try and fail and try on a unprecedented scale that many will never achieve again in their lives. Learning to walk is extremely dangerous and unfortunately costs 1000s of lives each year. Yet each of us born with functioning brains and legs indeed over came the odds and obstacles and learned to walk. Ask anyone who lost the ability to remember how to walk just how monumental the task is later in life. Learning is and always will be limited scope trial and error.
I do not advise any Intelligent Agent using AI let wild without any guidelines lose in any environment other then simple learning. This means the human becomes comfortable with the scope of what the Intelligent Agent and AI is doing. In any system one can speculate about the worse case, the doom and gloom. In fact this very argument has been used against computers since the dawn of the computer age. We hear about “human” error on the misplacement of a comma in a bank account, about how dates are handled after the year 2000. Books have been written both science fact and science faction on how the simple computer could get a “bug’ (literally) and cause havoc. You and I ignore this nonsense today.
We will not be making new commands in the Voice First world, the Intelligent Agents will 24/7 learn about us and our volition and intent. This is not trivial nor is it insurmountable. It is not 20 years away but in many ways here and now in the garages of many inventors I know today. Commands are a vestige of us learning to be like the machine and in time will become like the punch card and mag tape drives of the past. You in I will talk about what we want to get done or what we want to know, we will not reach for an adjustable wrench and open up the hood of the metaphorical car engine and adjust the carburetor.
As per your assertion: “This statement “stating what we need and letting the computer decode volition and intent” is, I think, not truly attainable. At best we can only make a very good simulation of it.”
Indeed this is correct, my thesis is not about a “Singularity”. Of course it is a simulation of the human. I feel strongly that humans will define the future for a very long time. The computer will aspire to be more like us.
“As each paradigm replaced the last, productivity and utility. In some cases…”
I feel like there is a word or words missing there. Admittedly, it could be my reading comprehension that’s missing.
Joe
Indeed, it was short a word. Should be: “As each paradigm replaced the last, productivity and utility increases”
Interesting, thank you.
I’m not sure what to think of the probability of rapid technical and business success of that stuff. I’m not a huge AI/bot fan, nor a huge speech-as-a-UI fan, but that’s maybe colored by experiences with early AI/bots and speech recog/synth. It’d be fun to see those actually become competent, 20 years on, but I still can’t bear the “read aloud” function of my PC and ebook reader.
What about privacy with voice first payment ?
Awesome! Its genuinely remarkable post, I have got much clear idea regarding from this post.
Great information shared.. really enjoyed reading this post thank you author for sharing this post .. appreciated
Good post! We will be linking to this particularly great post on our site. Keep up the great writing
For the reason that the admin of this site is working, no uncertainty very quickly it will be renowned, due to its quality contents.
very informative articles or reviews at this time.
naturally like your web site however you need to take a look at the spelling on several of your posts. A number of them are rife with spelling problems and I find it very bothersome to tell the truth on the other hand I will surely come again again.
That’s good, but I still don’t understand the purpose of this page posting, no or what and where do they get material like this.
This is my first time pay a quick visit at here and i am really happy to read everthing at one place
Great information shared.. really enjoyed reading this post thank you author for sharing this post .. appreciated
Nice post. I learn something totally new and challenging on websites
Pretty! This has been a really wonderful post. Many thanks for providing these details.
Nice post. I learn something totally new and challenging on websites
I do not even understand how I ended up here, but I assumed this publish used to be great
I just like the helpful information you provide in your articles
Cool that really helps, thank you.
Nice post. I learn something totally new and challenging on websites
very informative articles or reviews at this time.
This was beautiful Admin. Thank you for your reflections.
This is my first time pay a quick visit at here and i am really happy to read everthing at one place
Awesome! Its genuinely remarkable post, I have got much clear idea regarding from this post.
I do not even understand how I ended up here, but I assumed this publish used to be great
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
This was beautiful Admin. Thank you for your reflections.
You’re so awesome! I don’t believe I have read a single thing like that before. So great to find someone with some original thoughts on this topic. Really.. thank you for starting this up. This website is something that is needed on the internet, someone with a little originality!
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.
Pretty! This has been a really wonderful post. Many thanks for providing these details.
Pretty! This has been a really wonderful post. Many thanks for providing these details.
I am truly thankful to the owner of this web site who has shared this fantastic piece of writing at at this place.
Nice post. I learn something totally new and challenging on websites
I truly appreciate your technique of writing a blog. I added it to my bookmark site list and will
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.
I just like the helpful information you provide in your articles
Awesome! Its genuinely remarkable post, I have got much clear idea regarding from this post
I very delighted to find this internet site on bing, just what I was searching for as well saved to fav
Nice post. I learn something totally new and challenging on websites
Try to slowly read the articles on this website, don’t just comment, I think the posts on this page are very helpful, because I understand the intent of the author of this article.
This was beautiful Admin. Thank you for your reflections.
https://www.google.rs/url?sa=j&url=https://bambu4d.com
I very delighted to find this internet site on bing, just what I was searching for as well saved to fav
I really like reading through a post that can make men and women think. Also, thank you for allowing me to comment!
Awesome! Its genuinely remarkable post, I have got much clear idea regarding from this post.
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
naturally like your web site however you need to take a look at the spelling on several of your posts. A number of them are rife with spelling problems and I find it very bothersome to tell the truth on the other hand I will surely come again again.
I think the content you share is interesting, but for me there is still something missing, because the things discussed above are not important to talk about today.
I just like the helpful information you provide in your articles
This was beautiful Admin. Thank you for your reflections.
Pretty! This has been a really wonderful post. Many thanks for providing these details.
Cool that really helps, thank you.
I’m often to blogging and i really appreciate your content. The article has actually peaks my interest. I’m going to bookmark your web site and maintain checking for brand spanking new information.
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
Hello colleagues, how is everything, and what you want
That’s good, but I still don’t understand the purpose of this page posting, no or what and where do they get material like this.
naturally like your web site however you need to take a look at the spelling on several of your posts. A number of them are rife with spelling problems and I find it very bothersome to tell the truth on the other hand I will surely come again again.
This is my first time pay a quick visit at here and i am really happy to read everthing at one place
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
I think this post makes sense and really helps me, so far I’m still confused, after reading the posts on this website I understand.
It’s really a nice and useful piece of info. I’m glad that you shared this useful info with us. Please keep us informed like this. Thanks for sharing.
Pretty! This has been a really wonderful post. Many thanks for providing these details.
Very helpful, Don’t forget to visit my website Bambu4d
Don’t forget to watch videos on the YouTube channel Bambu4d
Try to slowly read the articles on this website, don’t just comment, I think the posts on this page are very helpful, because I understand the intent of the author of this article.
I think the content you share is interesting, but for me there is still something missing, because the things discussed above are not important to talk about today.
You’re so awesome! I don’t believe I have read a single thing like that before. So great to find someone with some original thoughts on this topic. Really.. thank you for starting this up. This website is something that is needed on the internet, someone with a little originality!
Pretty! This has been a really wonderful post. Many thanks for providing these details.
Hi! I just wanted to ask if you ever have any issues with hackers? My last blog (wordpress) was hacked and I ended up losing months of hard work due to no back up. Do you have any solutions to stop hackers?
In the great scheme of things you’ll receive a B- just for effort and hard work. Where exactly you confused me was first in the details. As they say, the devil is in the details… And that couldn’t be much more true in this article. Having said that, permit me inform you exactly what did work. The text is definitely highly powerful and that is possibly why I am taking an effort in order to comment. I do not really make it a regular habit of doing that. Next, even though I can certainly see a leaps in reason you come up with, I am not necessarily confident of how you appear to unite the details which inturn produce your conclusion. For now I will yield to your point but hope in the future you actually connect your dots much better.
Yet another issue is really that video gaming has become one of the all-time greatest forms of fun for people of nearly every age. Kids participate in video games, plus adults do, too. The actual XBox 360 has become the favorite video games systems for individuals that love to have a huge variety of video games available to them, in addition to who like to experiment with live with other folks all over the world. Thank you for sharing your opinions.
This was beautiful Admin. Thank you for your reflections.
It?s really a great and helpful piece of information. I?m glad that you shared this useful information with us. Please keep us informed like this. Thanks for sharing.
There is definately a lot to find out about this subject. I like all the points you made
I?m impressed, I have to say. Actually hardly ever do I encounter a blog that?s both educative and entertaining, and let me inform you, you have hit the nail on the head. Your concept is outstanding; the issue is something that not sufficient persons are talking intelligently about. I’m very completely happy that I stumbled across this in my seek for something referring to this.
I’m often to blogging and i really appreciate your content. The article has actually peaks my interest. I’m going to bookmark your web site and maintain checking for brand spanking new information.
of course like your website but you need to check the spelling on quite a few of your posts. Several of them are rife with spelling issues and I find it very troublesome to tell the truth nevertheless I?ll definitely come back again.
I like the efforts you have put in this, regards for all the great content.
Hey very cool website!! Man .. Beautiful .. Amazing .. I will bookmark your blog and take the feeds also?I’m happy to find so many useful information here in the post, we need develop more strategies in this regard, thanks for sharing. . . . . .
Thanks for your article. One other thing is that individual American states have their own personal laws of which affect home owners, which makes it extremely tough for the Congress to come up with a fresh set of rules concerning property foreclosures on people. The problem is that a state provides own legal guidelines which may have impact in a damaging manner with regards to foreclosure plans.
I was just seeking this info for a while. After 6 hours of continuous Googleing, finally I got it in your website. I wonder what’s the lack of Google strategy that do not rank this kind of informative sites in top of the list. Normally the top web sites are full of garbage.
I do like the manner in which you have presented this specific situation plus it really does give me a lot of fodder for thought. On the other hand, from everything that I have observed, I only trust as the comments pile on that people today continue to be on point and in no way embark on a soap box involving the news du jour. Yet, thank you for this fantastic piece and whilst I can not really go along with this in totality, I respect your perspective.
This will be a terrific web site, could you be involved in doing an interview regarding how you designed it? If so e-mail me!
Good post! We will be linking to this particularly great post on our site. Keep up the great writing
Thanks for another informative site. Where else may just I am getting that kind of info written in such an ideal method? I’ve a mission that I’m just now operating on, and I’ve been at the glance out for such info.
There is definately a lot to find out about this subject. I like all the points you made
Thanks for your post on the traveling industry. I would also like to add that if you are one senior thinking of traveling, it is absolutely vital that you buy travel cover for retirees. When traveling, older persons are at greatest risk of getting a healthcare emergency. Having the right insurance cover package on your age group can protect your health and provide you with peace of mind.
it’s awesome article. I look forward to the continuation.
Thank you for the good writeup. It in fact was a amusement account it. Look advanced to more added agreeable from you! By the way, how can we communicate?
F*ckin? remarkable things here. I?m very glad to see your post. Thanks a lot and i am looking forward to contact you. Will you kindly drop me a mail?
I have observed that costs for on-line degree pros tend to be a fantastic value. Like a full Bachelor’s Degree in Communication with the University of Phoenix Online consists of 60 credits with $515/credit or $30,900. Also American Intercontinental University Online comes with a Bachelors of Business Administration with a entire course requirement of 180 units and a price of $30,560. Online degree learning has made taking your higher education degree much simpler because you can earn your degree through the comfort of your abode and when you finish working. Thanks for all your other tips I have really learned through the web site.
I just wanted to construct a small message so as to thank you for the amazing tactics you are giving out on this website. My time intensive internet look up has finally been honored with beneficial know-how to exchange with my contacts. I ‘d state that that we readers are rather lucky to exist in a magnificent website with so many brilliant individuals with useful guidelines. I feel quite happy to have used the web page and look forward to plenty of more entertaining minutes reading here. Thanks again for everything.
Try to slowly read the articles on this website, don’t just comment, I think the posts on this page are very helpful, because I understand the intent of the author of this article.
I?ve been exploring for a little for any high quality articles or blog posts on this sort of area . Exploring in Yahoo I at last stumbled upon this website. Reading this info So i am happy to convey that I’ve a very good uncanny feeling I discovered exactly what I needed. I most certainly will make sure to do not forget this website and give it a look on a constant basis.
After research just a few of the weblog posts in your web site now, and I really like your way of blogging. I bookmarked it to my bookmark website record and will be checking again soon. Pls try my web site as effectively and let me know what you think.
Interesting post here. One thing I would like to say is the fact most professional career fields consider the Bachelor’s Degree as the entry level requirement for an online college diploma. Even though Associate Certification are a great way to begin, completing your own Bachelors uncovers many good opportunities to various occupations, there are numerous internet Bachelor Diploma Programs available via institutions like The University of Phoenix, Intercontinental University Online and Kaplan. Another concern is that many brick and mortar institutions present Online variants of their college diplomas but typically for a drastically higher fee than the institutions that specialize in online qualification plans.
Thanks for a marvelous posting! I genuinely enjoyed reading it, you are a great author.I will always bookmark your blog and will often come back down the road. I want to encourage continue your great job, have a nice weekend!
Cool that really helps, thank you.
I have seen that right now, more and more people are now being attracted to surveillance cameras and the field of images. However, as a photographer, you will need to first devote so much of your time deciding the exact model of camera to buy in addition to moving via store to store just so you might buy the most affordable camera of the trademark you have decided to decide on. But it isn’t going to end generally there. You also have to take into consideration whether you can purchase a digital digital camera extended warranty. Thanks a bunch for the good suggestions I accumulated from your weblog.
it’s awesome article. I look forward to the continuation.
I just like the helpful information you provide in your articles
Nice blog right here! Additionally your website so much up fast! What web host are you the use of? Can I get your affiliate link in your host? I want my website loaded up as fast as yours lol
I can’t express how much I appreciate the effort the author has put into producing this outstanding piece of content. The clarity of the writing, the depth of analysis, and the abundance of information presented are simply impressive. Her enthusiasm for the subject is obvious, and it has certainly made an impact with me. Thank you, author, for sharing your wisdom and enriching our lives with this exceptional article!
Hey there are using WordPress for your blog platform? I’m new to the blog world but I’m trying to get started and create my own. Do you need any html coding expertise to make your own blog? Any help would be really appreciated!
Just desire to say your article is as amazing. The clarity to your publish is just spectacular and i can think you’re a professional on this subject. Fine along with your permission let me to grasp your RSS feed to stay up to date with imminent post. Thank you 1,000,000 and please continue the enjoyable work.
plate suculente
I gotta favorite this web site it seems very helpful invaluable
A powerful share, I simply given this onto a colleague who was doing somewhat evaluation on this. And he in reality bought me breakfast because I discovered it for him.. smile. So let me reword that: Thnx for the deal with! But yeah Thnkx for spending the time to discuss this, I feel strongly about it and love reading extra on this topic. If possible, as you develop into experience, would you thoughts updating your weblog with extra details? It is highly useful for me. Big thumb up for this weblog post!
Generally I do not learn article on blogs, but I wish to say that this write-up very compelled me to take a look at and do it! Your writing taste has been surprised me. Thanks, quite great post.
I’m often to blogging and i really appreciate your content. The article has actually peaks my interest. I’m going to bookmark your web site and maintain checking for brand spanking new information.
This is really interesting, You’re a very skilled blogger. I’ve joined your feed and look forward to seeking more of your magnificent post. Also, I’ve shared your site in my social networks!
I like what you guys tend to be up too. This kind of clever work and reporting! Keep up the fantastic works guys I’ve you guys to our blogroll.
whoah this blog is excellent i love reading your posts. Keep up the good work! You know, lots of people are hunting around for this info, you could help them greatly.
Its like you learn my mind! You appear to understand a lot approximately this, such as you wrote the book in it or something. I feel that you simply can do with a few p.c. to pressure the message home a bit, however instead of that, this is magnificent blog. An excellent read. I will definitely be back.
I am very happy to read this. This is the kind of manual that needs to be given and not the random misinformation that is at the other blogs. Appreciate your sharing this best doc.
As I website owner I believe the content material here is really good appreciate it for your efforts.
actually awesome in support of me.
бриллкс
Brillx
Но если вы готовы испытать настоящий азарт и почувствовать вкус победы, то регистрация на Brillx Казино откроет вам доступ к захватывающему миру игр на деньги. Сделайте свои ставки, и каждый спин превратится в захватывающее приключение, где удача и мастерство сплетаются в уникальную симфонию успеха!Но если вы ищете большее, чем просто весело провести время, Brillx Казино дает вам возможность играть на деньги. Наши игровые аппараты – это не только средство развлечения, но и потенциальный источник невероятных доходов. Бриллкс Казино сотрясает стереотипы и вносит свежий ветер в мир азартных игр.
Good post! We will be linking to this particularly great post on our site. Keep up the great writing
There is definately a lot to find out about this subject. I like all the points you made
Some truly quality articles on this website , saved to favorites.
Mybudgetart.com.au is Australia’s Trusted Online Wall Art Canvas Prints Store. We are selling art online since 2008. We offer 1000+ artwork designs, up-to 50 OFF store-wide, FREE Delivery Australia & New Zealand, and World-wide shipping.
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
Hi! I’m at work surfing around your blog from my new iphone 4! Just wanted to say I love reading your blog and look forward to all your posts! Keep up the fantastic work!
Dead indited articles, Really enjoyed looking through.
Simply wish to say your article is as surprising. The clarity on your put up is just spectacular and i could suppose you’re a professional in this subject. Fine along with your permission allow me to clutch your feed to keep updated with impending post. Thanks one million and please carry on the rewarding work.
Great information shared.. really enjoyed reading this post thank you author for sharing this post .. appreciated
You actually make it seem so easy with your presentation but I find this matter to be actually something which I think I would never understand. It seems too complex and very broad for me. I’m looking forward for your next post, I?ll try to get the hang of it!
I¦ve read some just right stuff here. Definitely worth bookmarking for revisiting. I surprise how a lot attempt you put to create such a fantastic informative site.
Hey! Do you know if they make any plugins to protect against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any suggestions?
Thanks a lot for the helpful article. It is also my opinion that mesothelioma has an incredibly long latency period of time, which means that warning signs of the disease may not emerge right until 30 to 50 years after the initial exposure to asbestos fiber. Pleural mesothelioma, which can be the most common sort and influences the area throughout the lungs, might cause shortness of breath, upper body pains, and a persistent cough, which may lead to coughing up our blood.
Keep working ,terrific job!
Thanks for the sensible critique. Me and my neighbor were just preparing to do some research on this. We got a grab a book from our local library but I think I learned more clear from this post. I’m very glad to see such great information being shared freely out there.
You are my inspiration , I possess few web logs and rarely run out from to post : (.
Good post! We will be linking to this particularly great post on our site. Keep up the great writing
Wow, marvelous blog structure! How lengthy have you been running a blog for? you make running a blog look easy. The overall glance of your website is great, let alone the content!
I think this is among the most vital information for me. And i’m glad reading your article. But want to remark on few general things, The web site style is perfect, the articles is really nice : D. Good job, cheers
Howdy! This post could not be written any better! Reading this post reminds me of my old room mate! He always kept chatting about this. I will forward this post to him. Fairly certain he will have a good read. Many thanks for sharing!
I got what you mean , thankyou for posting.Woh I am lucky to find this website through google.
You are my intake, I own few blogs and occasionally run out from post :). “‘Tis the most tender part of love, each other to forgive.” by John Sheffield.
Hey, you used to write magnificent, but the last several posts have been kinda boringK I miss your super writings. Past several posts are just a little bit out of track! come on!
There may be noticeably a bundle to know about this. I assume you made certain good points in options also.
I loved as much as you’ll receive carried out right here. The sketch is attractive, your authored material stylish. nonetheless, you command get bought an edginess over that you wish be delivering the following. unwell unquestionably come more formerly again as exactly the same nearly a lot often inside case you shield this hike.
Some really nice stuff on this site, I like it.
Once I initially commented I clicked the -Notify me when new comments are added- checkbox and now each time a remark is added I get four emails with the identical comment. Is there any manner you possibly can remove me from that service? Thanks!
Thanks for the ideas you have shared here. One more thing I would like to express is that laptop or computer memory demands generally go up along with other innovations in the know-how. For instance, if new generations of processor chips are introduced to the market, there is usually a related increase in the size and style calls for of both pc memory plus hard drive room. This is because the software program operated by means of these cpus will inevitably boost in power to leverage the new engineering.
Hey there! I’ve been reading your weblog for a while now and finally got the courage to go ahead and give you a shout out from Atascocita Texas! Just wanted to say keep up the great work!
It?s really a nice and useful piece of info. I am glad that you shared this helpful information with us. Please keep us up to date like this. Thanks for sharing.
https://hotclubdepiracicaba.com.br/post8/
I appreciate, cause I found just what I was looking for. You have ended my four day long hunt! God Bless you man. Have a nice day. Bye
Good day! I simply would like to give an enormous thumbs up for the great information you’ve here on this post. I will be coming again to your weblog for extra soon.
very informative articles or reviews at this time.
I’ve been surfing online more than three hours nowadays, yet I by no means found any fascinating article like yours. It is lovely price enough for me. Personally, if all site owners and bloggers made excellent content as you probably did, the web will likely be a lot more useful than ever before.
Hello my loved one! I want to say that this post is awesome, nice written and come with almost all vital infos. I?¦d like to look more posts like this .
I’ve been exploring for a bit for any high-quality articles or blog posts on this kind of area . Exploring in Yahoo I at last stumbled upon this website. Reading this information So i am happy to convey that I’ve an incredibly good uncanny feeling I discovered exactly what I needed. I most certainly will make sure to do not forget this web site and give it a glance regularly.
Thanks for sharing excellent informations. Your web site is so cool. I’m impressed by the details that you have on this website. It reveals how nicely you perceive this subject. Bookmarked this web page, will come back for more articles. You, my pal, ROCK! I found simply the info I already searched all over the place and simply could not come across. What a perfect web-site.
I just couldn’t depart your website before suggesting that I really enjoyed the standard info a person provide for your visitors? Is going to be back often in order to check up on new posts
Hi! I’m at work surfing around your blog from my new iphone 4! Just wanted to say I love reading your blog and look forward to all your posts! Carry on the outstanding work!
An attention-grabbing dialogue is price comment. I think that it’s best to write extra on this topic, it won’t be a taboo subject however generally persons are not sufficient to talk on such topics. To the next. Cheers
Keep up the excellent work, I read few content on this web site and I think that your website is rattling interesting and has got circles of superb information.
you’re truly a excellent webmaster. The website loading velocity is amazing. It seems that you are doing any unique trick. Moreover, The contents are masterpiece. you’ve performed a great job in this matter!
After examine just a few of the weblog posts on your web site now, and I truly like your method of blogging. I bookmarked it to my bookmark web site checklist and can be checking again soon. Pls check out my website as well and let me know what you think.
Very fantastic visual appeal on this website , I’d rate it 10 10.
to say concerning this paragraph, in my view its
You really make it appear so easy with your presentation but I find this matter to be actually one thing that I believe I’d never understand. It seems too complicated and very wide for me. I’m taking a look ahead on your next publish, I will try to get the cling of it!
Hi, i think that i saw you visited my blog thus i came to ?return the favor?.I’m trying to find things to enhance my site!I suppose its ok to use some of your ideas!!
Outstanding post however I was wanting to know if you could write a litte more on this subject? I’d be very thankful if you could elaborate a little bit more. Cheers!
Wow, awesome blog layout! How lengthy have you been running a blog for? you make running a blog look easy. The overall look of your site is magnificent, let alone the content!
I do not even understand how I ended up here, but I assumed this publish used to be great
Do you mind if I quote a couple of your posts as long as I provide credit and sources back to your site? My blog site is in the very same niche as yours and my users would genuinely benefit from some of the information you present here. Please let me know if this okay with you. Thanks!
Appreciate it for this post, I am a big big fan of this site would like to proceed updated.
You made some clear points there. I looked on the internet for the topic and found most individuals will go along with with your website.
Hello. splendid job. I did not imagine this. This is a fantastic story. Thanks!
I have been browsing on-line greater than 3 hours lately, yet I never found any fascinating article like yours. It is lovely price enough for me. In my opinion, if all website owners and bloggers made excellent content as you probably did, the internet might be a lot more helpful than ever before.
Sweet blog! I found it while browsing on Yahoo News. Do you have any tips on how to get listed in Yahoo News? I’ve been trying for a while but I never seem to get there! Thanks
Use the 1xBet promo code for registration : VIP888, and you will receive a €/$130 exclusive bonus on your first deposit. Before registering, you should familiarize yourself with the rules of the promotion.
Hi there! Someone in my Facebook group shared this website with us so I came to give it a look. I’m definitely loving the information. I’m bookmarking and will be tweeting this to my followers! Superb blog and brilliant style and design.
You should take part in a contest for one of the best blogs on the web. I will recommend this site!
You have brought up a very fantastic details , regards for the post.
Whats Going down i’m new to this, I stumbled upon this I have found It positively useful and it has aided me out loads. I am hoping to contribute & aid other users like its aided me. Good job.
This is really interesting, You are a very skilled blogger. I’ve joined your rss feed and look forward to seeking more of your fantastic post. Also, I’ve shared your web site in my social networks!
You are a very smart person!
whoah this blog is great i love studying your posts. Keep up the great paintings! You know, a lot of persons are searching round for this info, you could aid them greatly.
Hiya, I am really glad I’ve found this information. Nowadays bloggers publish just about gossips and web and this is actually irritating. A good site with interesting content, that’s what I need. Thank you for keeping this web site, I’ll be visiting it. Do you do newsletters? Can not find it.
You can certainly see your enthusiasm within the work you write. The sector hopes for even more passionate writers like you who aren’t afraid to say how they believe. At all times follow your heart. “The point of quotations is that one can use another’s words to be insulting.” by Amanda Cross.
http://www.thebudgetart.com is trusted worldwide canvas wall art prints & handmade canvas paintings online store. Thebudgetart.com offers budget price & high quality artwork, up-to 50 OFF, FREE Shipping USA, AUS, NZ & Worldwide Delivery.
There is definately a lot to find out about this subject. I like all the points you made
Can I just say what a aid to search out somebody who actually is aware of what theyre speaking about on the internet. You definitely know the best way to bring a problem to gentle and make it important. More people have to read this and perceive this aspect of the story. I cant consider youre no more popular because you positively have the gift.
This is really interesting, You’re a very skilled blogger. I’ve joined your feed and look forward to seeking more of your magnificent post. Also, I’ve shared your site in my social networks!
I’m now not certain the place you’re getting your information, however great topic. I must spend some time studying more or figuring out more. Thank you for great information I was searching for this info for my mission.
Hello! I could have sworn I’ve been to this blog before but after browsing through some of the post I realized it’s new to me. Anyways, I’m definitely happy I found it and I’ll be book-marking and checking back frequently!
Keep working ,terrific job!
Hello! I just would like to give a huge thumbs up for the great info you have here on this post. I will be coming back to your blog for more soon.
Great site. Lots of useful information here. I am sending it to some buddies ans also sharing in delicious. And of course, thanks for your effort!
Awesome! Its genuinely remarkable post, I have got much clear idea regarding from this post
Nice post. I learn something more challenging on different blogs everyday. It will always be stimulating to read content from other writers and practice a little something from their store. I’d prefer to use some with the content on my blog whether you don’t mind. Natually I’ll give you a link on your web blog. Thanks for sharing.
Thanks for the write-up. My spouse and i have continually noticed that almost all people are eager to lose weight when they wish to look slim as well as attractive. However, they do not constantly realize that there are other benefits for losing weight in addition. Doctors assert that overweight people have problems with a variety of ailments that can be perfectely attributed to their own excess weight. The good thing is that people who are overweight along with suffering from different diseases are able to reduce the severity of their illnesses by means of losing weight. It is possible to see a continuous but notable improvement in health while even a negligible amount of weight-loss is realized.
You completed certain fine points there. I did a search on the subject matter and found mainly persons will agree with your blog.
You have noted very interesting points! ps decent web site. “Formal education will make you a living self-education will make you a fortune.” by Jim Rohn.
I gotta favorite this web site it seems very helpful invaluable
he blog was how do i say it… relevant, finally something that helped me. Thanks
Hi there, I found your blog via Google while looking for a related topic, your web site came up, it looks good. I’ve bookmarked it in my google bookmarks.
Hello! I’ve been following your blog for some time now and finally got the courage to go ahead and give you a shout out from Houston Texas! Just wanted to mention keep up the great job!
Of course, what a magnificent blog and enlightening posts, I definitely will bookmark your site.All the Best!
What i don’t understood is in reality how you are no longer actually much more neatly-preferred than you might be right now. You’re so intelligent. You already know thus considerably in terms of this topic, made me in my opinion consider it from numerous various angles. Its like women and men don’t seem to be interested except it?s one thing to do with Lady gaga! Your own stuffs nice. At all times care for it up!
This design is incredible! You certainly know how to keep a reader amused. Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Fantastic job. I really enjoyed what you had to say, and more than that, how you presented it. Too cool!
I gotta bookmark this web site it seems invaluable handy
Some truly superb information, Gladiolus I discovered this.
I like the helpful info you provide to your articles. I will bookmark your weblog and test once more right here frequently. I am fairly certain I?ll be informed plenty of new stuff proper right here! Good luck for the next!
This was beautiful Admin. Thank you for your reflections.
Thanks for the auspicious writeup. It in reality was once a leisure account it. Glance complex to far brought agreeable from you! However, how could we keep in touch?
Hey! Do you use Twitter? I’d like to follow you if that would be ok. I’m undoubtedly enjoying your blog and look forward to new posts.
Magnificent site. Plenty of useful information here. I am sending it to a few friends ans also sharing in delicious. And obviously, thanks for your effort!
Great blog! Do you have any tips and hints for aspiring writers? I’m planning to start my own site soon but I’m a little lost on everything. Would you suggest starting with a free platform like WordPress or go for a paid option? There are so many options out there that I’m totally overwhelmed .. Any suggestions? Appreciate it!
you’re really a excellent webmaster. The website loading velocity is incredible. It seems that you are doing any distinctive trick. In addition, The contents are masterwork. you have done a fantastic task in this topic!
Absolutely indited articles, Really enjoyed reading through.
Throughout this awesome scheme of things you receive an A+ for effort. Exactly where you actually confused us ended up being in the details. You know, they say, details make or break the argument.. And it couldn’t be more accurate here. Having said that, allow me say to you exactly what did work. The writing is actually incredibly powerful which is probably the reason why I am making the effort to comment. I do not really make it a regular habit of doing that. Second, although I can easily see the jumps in reasoning you make, I am not really convinced of just how you seem to connect the ideas which inturn make your conclusion. For now I will yield to your position but trust in the near future you actually connect your facts better.
In the grand pattern of things you secure an A+ just for effort and hard work. Where exactly you confused me was on your particulars. You know, as the maxim goes, details make or break the argument.. And that could not be much more true right here. Having said that, allow me inform you precisely what did deliver the results. The writing can be quite engaging and that is most likely why I am making an effort to opine. I do not really make it a regular habit of doing that. Next, although I can certainly see the leaps in reason you come up with, I am not necessarily convinced of exactly how you appear to connect the ideas which in turn help to make the final result. For the moment I will, no doubt subscribe to your position but trust in the future you actually link the dots better.
You’re so awesome! I don’t believe I have read a single thing like that before. So great to find someone with some original thoughts on this topic. Really.. thank you for starting this up. This website is something that is needed on the internet, someone with a little originality!
naturally like your website however you have to test the spelling on quite a few of your posts. A number of them are rife with spelling problems and I in finding it very troublesome to inform the truth then again I will surely come again again.
Hello there, I found your web site by the use of Google while looking for a similar subject, your site came up, it appears great. I’ve bookmarked it in my google bookmarks.
I think other site proprietors should take this website as an model, very clean and wonderful user friendly style and design, as well as the content. You are an expert in this topic!
Hey there just wanted to give you a quick heads up. The text in your article seem to be running off the screen in Firefox. I’m not sure if this is a formatting issue or something to do with web browser compatibility but I figured I’d post to let you know. The layout look great though! Hope you get the problem fixed soon. Thanks
I have been absent for some time, but now I remember why I used to love this blog. Thank you, I’ll try and check back more often. How frequently you update your web site?
I truly enjoy looking through on this internet site, it contains great posts. “Don’t put too fine a point to your wit for fear it should get blunted.” by Miguel de Cervantes.
There are some interesting cut-off dates on this article but I don?t know if I see all of them middle to heart. There may be some validity but I will take maintain opinion until I look into it further. Good article , thanks and we would like more! Added to FeedBurner as nicely
obviously like your web-site however you need to take a look at the spelling on quite a few of your posts. Several of them are rife with spelling problems and I in finding it very troublesome to inform the reality then again I will certainly come back again.
very informative articles or reviews at this time.
I always was interested in this topic and stock still am, thankyou for posting.
We would also like to say that most people that find themselves with out health insurance are generally students, self-employed and those that are out of work. More than half with the uninsured are under the age of 35. They do not sense they are wanting health insurance since they are young and healthy. Their own income is typically spent on houses, food, as well as entertainment. Many people that do go to work either 100 or part time are not supplied insurance via their jobs so they proceed without because of the rising tariff of health insurance in the United States. Thanks for the ideas you reveal through this blog.
Definitely believe that that you said. Your favourite justification seemed to be on the net the simplest thing to remember of. I say to you, I definitely get annoyed while other folks think about concerns that they just do not know about. You controlled to hit the nail upon the highest as smartly as outlined out the entire thing without having side effect , other people could take a signal. Will probably be again to get more. Thank you
Hiya, I’m really glad I have found this info. Nowadays bloggers publish just about gossips and web and this is actually frustrating. A good website with exciting content, that is what I need. Thank you for keeping this web-site, I’ll be visiting it. Do you do newsletters? Cant find it.
I’ve been exploring for a little bit for any high-quality articles or blog posts on this kind of area . Exploring in Yahoo I at last stumbled upon this site. Reading this info So i am happy to convey that I have a very good uncanny feeling I discovered exactly what I needed. I most certainly will make sure to do not forget this web site and give it a look on a constant basis.
Hello! This is my first visit to your blog! We are a group of volunteers and starting a new initiative in a community in the same niche. Your blog provided us valuable information to work on. You have done a marvellous job!
Thanks for your useful post. As time passes, I have been able to understand that the symptoms of mesothelioma cancer are caused by the particular build up associated fluid between lining on the lung and the chest cavity. The ailment may start in the chest spot and get distributed to other limbs. Other symptoms of pleural mesothelioma include weight loss, severe deep breathing trouble, temperature, difficulty swallowing, and irritation of the neck and face areas. It really should be noted that some people having the disease usually do not experience virtually any serious signs at all.
I truly appreciate your piece of work, Great post.
I like the helpful information you provide for your articles. I’ll bookmark your weblog and test once more right here regularly. I’m rather certain I will learn plenty of new stuff right right here! Good luck for the next!
Perfect work you have done, this internet site is really cool with excellent info .
Wow, marvelous blog layout! How long have you been blogging for? you made blogging look easy. The overall look of your site is great, as well as the content!
whoah this weblog is excellent i like reading your posts. Stay up the great work! You understand, a lot of people are searching round for this information, you could help them greatly.
Merely a smiling visitant here to share the love (:, btw great design and style. “Make the most of your regrets… . To regret deeply is to live afresh.” by Henry David Thoreau.
Some truly excellent info , Gladiolus I noticed this.
My spouse and I stumbled over here from a different web page and thought I might check things out. I like what I see so i am just following you. Look forward to finding out about your web page repeatedly.
great publish, very informative. I ponder why the other specialists of this sector do not understand this. You must proceed your writing. I’m confident, you’ve a great readers’ base already!
Just wanna admit that this is invaluable, Thanks for taking your time to write this.
Great line up. We will be linking to this great article on our site. Keep up the good writing.
Howdy! Do you know if they make any plugins to assist with SEO? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good gains. If you know of any please share. Thank you!
I’m curious to find out what blog platform you have been working with? I’m experiencing some small security problems with my latest site and I would like to find something more safeguarded. Do you have any solutions?
Have you ever thought about adding a little bit more than just your articles? I mean, what you say is important and everything. However imagine if you added some great graphics or videos to give your posts more, “pop”! Your content is excellent but with pics and video clips, this site could undeniably be one of the most beneficial in its field. Wonderful blog!
Абузоустойчивый VPS
Виртуальные серверы VPS/VDS: Путь к Успешному Бизнесу
В мире современных технологий и онлайн-бизнеса важно иметь надежную инфраструктуру для развития проектов и обеспечения безопасности данных. В этой статье мы рассмотрим, почему виртуальные серверы VPS/VDS, предлагаемые по стартовой цене всего 13 рублей, являются ключом к успеху в современном бизнесе
Perfect piece of work you have done, this website is really cool with great information.
Hi, i feel that i saw you visited my website thus i got here to ?return the want?.I am attempting to find things to enhance my website!I guess its good enough to make use of some of your ideas!!
Thanks for a marvelous posting! I genuinely enjoyed reading it, you are a great author.I will always bookmark your blog and will often come back down the road. I want to encourage continue your great job, have a nice weekend!
I think other web-site proprietors should take this site as an model, very clean and excellent user genial style and design, as well as the content. You’re an expert in this topic!
A lot of of what you assert is astonishingly accurate and it makes me ponder why I had not looked at this in this light before. Your article truly did switch the light on for me as far as this subject goes. However there is actually one point I am not really too comfy with so whilst I attempt to reconcile that with the actual core idea of your position, let me see exactly what all the rest of the subscribers have to say.Well done.
https://withoutprescription.guru/# buy prescription drugs from canada cheap
I know this if off topic but I’m looking into starting my own weblog and was wondering what all is required to get set up? I’m assuming having a blog like yours would cost a pretty penny? I’m not very internet smart so I’m not 100 certain. Any suggestions or advice would be greatly appreciated. Cheers
I am really impressed with your writing skills as well as with the layout on your weblog. Is this a paid theme or did you modify it yourself? Either way keep up the nice quality writing, it’s rare to see a great blog like this one today..
Hi, Neat post. There is an issue with your site in web explorer, may test thisK IE still is the market leader and a big element of folks will pass over your fantastic writing because of this problem.
whoah this blog is magnificent i love studying your articles.
Stay up the great work! You understand, a lot of people are looking round for this info,
you could aid them greatly.
https://edpills.icu/# erection pills viagra online
Wonderful site. A lot of useful info here.
I’m sending it to several pals ans also sharing in delicious.
And obviously, thanks for your sweat!
I genuinely enjoy examining on this website , it contains superb blog posts. “Words are, of course, the most powerful drug used by mankind.” by Rudyard Kipling.
how can i get generic clomid without dr prescription: buying generic clomid price – can i order clomid without prescription
https://medium.com/@ShelbyChan82971/дешевый-сервер-на-ubuntu-linux-с-выделенным-хостингом-a78fcfeca45f
VPS SERVER
Высокоскоростной доступ в Интернет: до 1000 Мбит/с
Скорость подключения к Интернету — еще один важный фактор для успеха вашего проекта. Наши VPS/VDS-серверы, адаптированные как под Windows, так и под Linux, обеспечивают доступ в Интернет со скоростью до 1000 Мбит/с, что гарантирует быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
Greetings! Very useful advice within this post!
It is the little changes that produce the most significant changes.
Many thanks for sharing!
https://withoutprescription.guru/# real viagra without a doctor prescription
You have mentioned very interesting details! ps nice web site. “The world is dying for want, not of good preaching, but of good hearing.” by George Dana Boardman.
Very rapidly this web site will be famous amid all blogging viewers, due
to it’s fastidious articles or reviews
hello!,I love your writing very so much! share we keep in touch more approximately your post on AOL? I require a specialist on this house to solve my problem. May be that’s you! Looking ahead to look you.
I keep listening to the reports talk about receiving free online grant applications so I have been looking around for the best site to get one. Could you advise me please, where could i get some?
http://levitra.icu/# buy Levitra over the counter
Great blog here! Also your site loads up very fast!
What web host are you using? Can I get your affiliate link to your host?
I wish my site loaded up as quickly as yours lol
win79
win79
Buy Vardenafil 20mg online: Levitra 10 mg best price – Cheap Levitra online
Vardenafil buy online: Levitra online pharmacy – Cheap Levitra online
Thanks for your article on this site. From my personal experience, many times softening upward a photograph might provide the professional photographer with a little an inspired flare. Often however, that soft blur isn’t exactly what you had under consideration and can quite often spoil a normally good picture, especially if you thinking about enlarging it.
Kamagra 100mg price Kamagra Oral Jelly buy kamagra online usa
I really like your blog.. very nice colors & theme.
Did you design this website yourself or did you hire someone to do it for you?
Plz reply as I’m looking to create my own blog and would like to find
out where u got this from. many thanks
https://tadalafil.trade/# 80 mg tadalafil
Thank you, I have just been looking for info about this subject for ages and yours is the best I have discovered so far. However, what about the bottom line? Are you positive about the supply?
Hello my family member! I wish to say that this article is amazing, nice written and come with approximately all significant infos. I?¦d like to look more posts like this .
Way cool! Some extremely valid points! I appreciate you penning this article and also the rest of
the website is also very good.
to say concerning this paragraph, in my view its
http://edpills.monster/# online ed pills
Howdy, i read your blog occasionally and i own a similar one and i was just curious if you get a lot of spam remarks? If so how do you stop it, any plugin or anything you can advise? I get so much lately it’s driving me mad so any support is very much appreciated.
Vardenafil buy online п»їLevitra price Levitra 10 mg best price
https://kamagra.team/# Kamagra Oral Jelly
VPS SERVER
Высокоскоростной доступ в Интернет: до 1000 Мбит/с
Скорость подключения к Интернету — еще один важный фактор для успеха вашего проекта. Наши VPS/VDS-серверы, адаптированные как под Windows, так и под Linux, обеспечивают доступ в Интернет со скоростью до 1000 Мбит/с, что гарантирует быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
I really like reading through a post that can make men and women think. Also, thank you for allowing me to comment!
Kamagra 100mg price: Kamagra Oral Jelly – super kamagra
http://sildenafil.win/# sildenafil 50mg tablets coupon
https://levitra.icu/# Generic Levitra 20mg
I do not even understand how I ended up here, but I assumed this publish used to be great
can i buy sildenafil online sildenafil cost cost of sildenafil 20 mg
zithromax 500: buy zithromax canada – zithromax z-pak
amoxicillin online pharmacy cheap amoxicillin buy amoxil
https://azithromycin.bar/# where can i buy zithromax medicine
amoxil pharmacy: buy amoxil – amoxicillin buy online canada
buy zithromax online: buy zithromax – zithromax 250mg
cipro pharmacy buy ciprofloxacin over the counter cipro ciprofloxacin
doxycycline 100mg cap price: Buy doxycycline hyclate – order doxycycline 100mg
Dead pent content material, thank you for information. “No human thing is of serious importance.” by Plato.
Thanks for helping out, great information.
amoxicillin 500mg capsules: purchase amoxicillin online – buy amoxicillin 500mg canada
doxycycline 1000 mg best buy: buy doxycycline over the counter – doxycycline prescription
order zithromax without prescription zithromax antibiotic without prescription zithromax z-pak price without insurance
SightCare is a powerful formula that supports healthy eyes the natural way. It is specifically designed for both men and women who are suffering from poor eyesight.
buy cheap amoxicillin: buy amoxil – amoxicillin 500 mg price
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
greg@bighammerwines.com
doxycycline where to get Buy doxycycline for chlamydia cost of doxycycline 100mg in india
http://lisinopril.auction/# 2 lisinopril
buy cipro online canada: Ciprofloxacin online prescription – buy ciprofloxacin over the counter
zithromax capsules price: zithromax z-pak – zithromax 500mg price
Hello there, I found your web site via Google while looking for a related topic, your website got here up, it seems great. I’ve bookmarked it in my google bookmarks.
Boostaro is a natural health formula for men that aims to improve health.
Quietum Plus is a 100% natural supplement designed to address ear ringing and other hearing issues. This formula uses only the best in class and natural ingredients to achieve desired results.
GlucoTrust 75% off for sale. GlucoTrust is a dietary supplement that has been designed to support healthy blood sugar levels and promote weight loss in a natural way.
EndoPeak is a natural energy-boosting formula designed to improve men’s stamina, energy levels, and overall health.
best india pharmacy: indian pharmacies safe – indian pharmacy paypal
Sight Care is all-natural and safe-to-take healthy vision and eye support formula that naturally supports a healthy 20/20 vision.
Introducing Claritox Pro, a natural supplement designed to help you maintain your balance and prevent dizziness.
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
purple pharmacy mexico price list: mexican pharmacy – mexican pharmaceuticals online
Thank you so much for sharing with us. Are you curious about a private profile viewer? If yes then this article is an excellent resource to learn more. Utilize the private profile viewer tool to access photos, videos, and other content. Refer to the article for additional details and share it with your friends.
reputable mexican pharmacies online mexican pharmacy online pharmacies in mexico that ship to usa
canadian pharmacy ltd: international online pharmacy – legit canadian pharmacy online
Cortexi is a natural hearing support aid that has been used by thousands of people around the globe.
Fast Lean Pro tricks your brain into imagining that you’re fasting and helps you maintain a healthy weight no matter when or what you eat.
I just like the helpful information you provide in your articles
Частный дом престарелых в Тульской области. Также мы принимаем пожилых людей с Брянской, Орловской, Липецкой, Рязанской, Калужской и Московской областей. Наш пансионат для пожилых людей является…
Aizen Power is a dietary supplement for male enhancement sexual health that is designed to help enhance men’s performance and improve overall health.
Actiflow is an industry-leading prostate health supplement that maintains men’s health.
Amiclear is a blood sugar support formula that’s perfect for men and women in their 30s, 40s, 50s, and even 70s.
It¦s really a nice and useful piece of information. I am satisfied that you just shared this helpful information with us. Please stay us up to date like this. Thank you for sharing.
ErecPrime is a natural male dietary supsplement designed to enhance performance and overall vitality.
Cortexi – $49/bottle price official website. Cortexi is a natural formulas to support healthy hearing and mental sharpness well into your golden years.
FitSpresso is a special supplement that makes it easier for you to lose weight. It has natural ingredients that help your body burn fat better.
Dentitox Pro™ Is An All Natural Formula That Consists Unique Combination Of Vitamins And Plant Extracts To Support The Health Of Gums
Those are yours alright! . We at least need to get these people stealing images to start blogging! They probably just did a image search and grabbed them. They look good though!
Fast Lean Pro is a herbal supplement that tricks your brain into imagining that you’re fasting and helps you maintain a healthy weight no matter when or what you eat.
Thanks for your beneficial post. Over time, I have come to understand that the actual symptoms of mesothelioma are caused by your build up associated fluid between lining on the lung and the torso cavity. The infection may start inside the chest region and propagate to other parts of the body. Other symptoms of pleural mesothelioma cancer include weight loss, severe breathing trouble, temperature, difficulty swallowing, and puffiness of the neck and face areas. It ought to be noted that some people having the disease do not experience any serious signs or symptoms at all.
GlucoTru Diabetes Supplement is a natural blend of various natural components.
I conceive this site contains very excellent pent subject matter posts.
Hi my friend! I want to say that this article is amazing, great written and come with approximately all vital infos. I’d like to look extra posts like this.
https://paxlovid.club/# buy paxlovid online
I truly enjoy studying on this website , it has fantastic posts. “Beauty in things exist in the mind which contemplates them.” by David Hume.
I’m not sure exactly why but this blog is loading very slow for me.
Is anyone else having this problem or is it a issue on my end?
I’ll check back later on and see if the problem still exists.
Hello, Neat post. There’s an issue along with your site in internet explorer, would check this… IE nonetheless is the market leader and a huge part of other people will miss your great writing because of this problem.
ventolin australia buy: generic ventolin – ventolin prescription discount
I just like the helpful information you provide in your articles
NeuroPure is a breakthrough dietary formula designed to alleviate neuropathy, a condition that affects a significant number of individuals with diabetes.
Nervogen Pro is a dietary formula that contains 100% natural ingredients. The powerful blend of ingredients claims to support a healthy nervous system. Each capsule includes herbs and antioxidants that protect the nerve against damage and nourishes the nerves with the required nutrients. Order Your Nervogen Pro™ Now!
Introducing Neurodrine – the revolutionary solution to maintaining a steel trap memory!
NeuroRise™ is one of the popular and best tinnitus supplements that help you experience 360-degree hearing
paxlovid generic http://paxlovid.club/# paxlovid covid
neurontin brand name in india: buy gabapentin online – neurontin price australia
Prostadine works really well because it’s made from natural things. The people who made it spent a lot of time choosing these natural things to help your mind work better without any bad effects.
ProDentim is an innovative dental health supplement that boasts of a unique blend of 3.5 billion probiotics and essential nutrients
As I site possessor I believe the content matter here is rattling magnificent , appreciate it for your efforts. You should keep it up forever! Best of luck.
Dead indited articles, Really enjoyed looking through.
can i purchase wellbutrin without prescription in canada: Buy Wellbutrin XL 300 mg online – wellbutrin 10mg
https://gabapentin.life/# neurontin capsules 600mg
Achieve real weight loss success with ProvaSlim provides real Weight loss powder, weight gain health benefits, toxin elimination, and helps users better digestion.
SeroLean follows an AM-PM daily routine that boosts serotonin levels. Modulating the synthesis of serotonin aids in mood enhancement
Alpha Tonic daily testosterone booster for energy and performance. Convenient powder form ensures easy blending into drinks for optimal absorption.
Neurozoom is one of the best supplements out on the market for supporting your brain health and, more specifically, memory functions.
I have not checked in here for a while since I thought it was getting boring, but the last few posts are great quality so I guess I will add you back to my daily bloglist. You deserve it my friend 🙂
ProstateFlux™ is a natural supplement designed by experts to protect prostate health without interfering with other body functions.
Pineal XT™ is a dietary supplement crafted from entirely organic ingredients, ensuring a natural formulation.
generic neurontin cost: cheap gabapentin – neurontin 202
SonoFit is a revolutionary hearing support supplement that is designed to offer a natural and effective solution to support hearing.
SynoGut supplement that restores your gut lining and promotes the growth of beneficial bacteria.
SonoVive™ is a 100% natural hearing supplement by Sam Olsen made with powerful ingredients that help heal tinnitus problems and restore your hearing.
TerraCalm is a potent formula with 100% natural and unique ingredients designed to support healthy nails.
TonicGreens is a revolutionary product that can transform your health and strengthen your immune system!
Tropislim, is an all-natural dietary supplement. It promotes healthy weight loss through a proprietary blend of tropical plants and nutrients.
farmacie online sicure: avanafil prezzo – farmacie online sicure
farmacie on line spedizione gratuita: farmacia online spedizione gratuita – acquistare farmaci senza ricetta
https://tadalafilit.store/# farmacia online migliore
For latest news you have to visit the web and on web I found this site as a most excellent site for newest updates.
viagra pfizer 25mg prezzo: viagra consegna in 24 ore pagamento alla consegna – pillole per erezione in farmacia senza ricetta
acquisto farmaci con ricetta: avanafil generico prezzo – farmacie online affidabili
Some truly fantastic info , Gladiola I detected this. “Without discipline, there’s no life at all.” by Katharine Hepburn.
farmacia online più conveniente: Tadalafil generico – farmacia online più conveniente
viagra cosa serve: viagra prezzo – alternativa al viagra senza ricetta in farmacia
MenoRescue™ is a women’s health dietary supplement formulated to assist them in overcoming menopausal symptoms.
farmacia online migliore: avanafil prezzo in farmacia – farmacia online miglior prezzo
BioFit is a natural supplement that balances good gut bacteria, essential for weight loss and overall health.
GlucoBerry is a unique supplement that offers an easy and effective way to support balanced blood sugar levels.
Joint Genesis is a supplement from BioDynamix that helps consumers to improve their joint health to reduce pain.
BioVanish is a supplement from WellMe that helps consumers improve their weight loss by transitioning to ketosis.
Tiêu đề: “B52 Club – Trải nghiệm Game Đánh Bài Trực Tuyến Tuyệt Vời”
B52 Club là một cổng game phổ biến trong cộng đồng trực tuyến, đưa người chơi vào thế giới hấp dẫn với nhiều yếu tố quan trọng đã giúp trò chơi trở nên nổi tiếng và thu hút đông đảo người tham gia.
1. Bảo mật và An toàn
B52 Club đặt sự bảo mật và an toàn lên hàng đầu. Trang web đảm bảo bảo vệ thông tin người dùng, tiền tệ và dữ liệu cá nhân bằng cách sử dụng biện pháp bảo mật mạnh mẽ. Chứng chỉ SSL đảm bảo việc mã hóa thông tin, cùng với việc được cấp phép bởi các tổ chức uy tín, tạo nên một môi trường chơi game đáng tin cậy.
2. Đa dạng về Trò chơi
B52 Play nổi tiếng với sự đa dạng trong danh mục trò chơi. Người chơi có thể thưởng thức nhiều trò chơi đánh bài phổ biến như baccarat, blackjack, poker, và nhiều trò chơi đánh bài cá nhân khác. Điều này tạo ra sự đa dạng và hứng thú cho mọi người chơi.
3. Hỗ trợ Khách hàng Chuyên Nghiệp
B52 Club tự hào với đội ngũ hỗ trợ khách hàng chuyên nghiệp, tận tâm và hiệu quả. Người chơi có thể liên hệ thông qua các kênh như chat trực tuyến, email, điện thoại, hoặc mạng xã hội. Vấn đề kỹ thuật, tài khoản hay bất kỳ thắc mắc nào đều được giải quyết nhanh chóng.
4. Phương Thức Thanh Toán An Toàn
B52 Club cung cấp nhiều phương thức thanh toán để đảm bảo người chơi có thể dễ dàng nạp và rút tiền một cách an toàn và thuận tiện. Quy trình thanh toán được thiết kế để mang lại trải nghiệm đơn giản và hiệu quả cho người chơi.
5. Chính Sách Thưởng và Ưu Đãi Hấp Dẫn
Khi đánh giá một cổng game B52, chính sách thưởng và ưu đãi luôn được chú ý. B52 Club không chỉ mang đến những chính sách thưởng hấp dẫn mà còn cam kết đối xử công bằng và minh bạch đối với người chơi. Điều này giúp thu hút và giữ chân người chơi trên thương trường game đánh bài trực tuyến.
Hướng Dẫn Tải và Cài Đặt
Để tham gia vào B52 Club, người chơi có thể tải file APK cho hệ điều hành Android hoặc iOS theo hướng dẫn chi tiết trên trang web. Quy trình đơn giản và thuận tiện giúp người chơi nhanh chóng trải nghiệm trò chơi.
Với những ưu điểm vượt trội như vậy, B52 Club không chỉ là nơi giải trí tuyệt vời mà còn là điểm đến lý tưởng cho những người yêu thích thách thức và may mắn.
http://kamagrait.club/# farmacie online sicure
migliori farmacie online 2023: avanafil spedra – acquisto farmaci con ricetta
gel per erezione in farmacia: viagra prezzo farmacia – miglior sito per comprare viagra online
farmacie online sicure: avanafil prezzo – farmacie on line spedizione gratuita
kamagra senza ricetta in farmacia: viagra originale in 24 ore contrassegno – viagra ordine telefonico
It’s really a nice and useful piece of info. I’m glad that you shared this useful info with us. Please keep us informed like this. Thanks for sharing.
ortexi is a 360° hearing support designed for men and women who have experienced hearing loss at some point in their lives.
comprare farmaci online con ricetta: cialis generico consegna 48 ore – acquisto farmaci con ricetta
Thanks for your article on the vacation industry. We would also like contribute that if you are a senior thinking about traveling, its absolutely vital that you buy travel insurance for seniors. When traveling, retirees are at high risk of experiencing a health-related emergency. Buying the right insurance policy package in your age group can look after your health and provide you with peace of mind.
viagra pfizer 25mg prezzo: viagra senza ricetta – viagra 100 mg prezzo in farmacia
farmacia online più conveniente: avanafil – farmacia online miglior prezzo
http://farmaciait.pro/# farmacie online affidabili
SharpEar™ is a 100% natural ear care supplement created by Sam Olsen that helps to fix hearing loss
acquistare farmaci senza ricetta farmacia online piu conveniente farmacia online miglior prezzo
esiste il viagra generico in farmacia: viagra prezzo – viagra acquisto in contrassegno in italia
farmacie online sicure: avanafil – farmacia online miglior prezzo
farmacie online affidabili: farmacia online miglior prezzo – comprare farmaci online con ricetta
farmacie on line spedizione gratuita: cialis prezzo – comprare farmaci online con ricetta
Whats up very nice blog!! Man .. Beautiful .. Amazing .. I’ll bookmark your site and take the feeds also?KI am happy to find a lot of helpful info here within the publish, we want work out extra strategies on this regard, thanks for sharing. . . . . .
viagra 100 mg prezzo in farmacia: gel per erezione in farmacia – siti sicuri per comprare viagra online
viagra originale in 24 ore contrassegno: viagra senza ricetta – viagra generico sandoz
viagra 100 mg prezzo in farmacia: viagra senza ricetta – viagra originale in 24 ore contrassegno
http://kamagrait.club/# farmacie on line spedizione gratuita
farmacia online più conveniente: dove acquistare cialis online sicuro – farmacia online migliore
farmacia online più conveniente: comprare avanafil senza ricetta – farmacia online
Your house is valueble for me. Thanks!…
viagra naturale in farmacia senza ricetta: alternativa al viagra senza ricetta in farmacia – viagra cosa serve
comprare farmaci online all’estero: kamagra gold – acquisto farmaci con ricetta
Hey this is kind of of off topic but I was wanting to know if blogs use WYSIWYG editors or if you have
to manually code with HTML. I’m starting a blog soon but have no coding know-how so I wanted to
get guidance from someone with experience. Any help would be enormously appreciated!
farmacie online sicure: Tadalafil generico – farmacia online miglior prezzo
acquisto farmaci con ricetta farmacia online acquisto farmaci con ricetta
top farmacia online: avanafil prezzo in farmacia – farmacia online
http://avanafilit.icu/# farmacie online affidabili
Hello! I could have sworn I’ve been to this website before but after checking through some of the post I realized it’s new to me. Anyways, I’m definitely happy I found it and I’ll be book-marking and checking back frequently!
farmacie online sicure: avanafil – farmacie online sicure
https://b52.name
farmaci senza ricetta elenco: dove acquistare cialis online sicuro – farmaci senza ricetta elenco
Having read this I thought it was very informative. I appreciate you taking the time and effort to put this article together. I once again find myself spending way to much time both reading and commenting. But so what, it was still worth it!
farmacie online sicure: farmacia online miglior prezzo – farmacia online più conveniente
I have seen that service fees for internet degree pros tend to be a great value. For instance a full Bachelors Degree in Communication with the University of Phoenix Online consists of 60 credits from $515/credit or $30,900. Also American Intercontinental University Online makes available Bachelors of Business Administration with a complete school element of 180 units and a price of $30,560. Online learning has made getting your certification so much easier because you can certainly earn your current degree from the comfort of your home and when you finish from office. Thanks for all your other tips I have really learned through your blog.
whoah this blog is wonderful i like studying your articles.
Stay up the good work! You know, many individuals are searching round for this info, you could aid them greatly.
farmacia online miglior prezzo: kamagra gold – farmacia online miglior prezzo
farmacia online migliore: Tadalafil prezzo – acquisto farmaci con ricetta
farmacia online miglior prezzo: dove acquistare cialis online sicuro – farmacia online migliore
Heya! I just wanted to ask if you ever have any trouble with hackers? My last blog (wordpress) was hacked and I ended up losing a few months of hard work due to no data backup. Do you have any methods to stop hackers?
http://sildenafilo.store/# sildenafilo cinfa 25 mg precio
https://kamagraes.site/# farmacias online baratas
https://farmacia.best/# farmacias online seguras en españa
comprar sildenafilo cinfa 100 mg espaГ±a comprar viagra contrareembolso 48 horas sildenafilo 100mg precio espaГ±a
https://vardenafilo.icu/# farmacia online envÃo gratis
http://kamagraes.site/# farmacia barata
http://www.bestartdeals.com.au is Australia’s Trusted Online Canvas Prints Art Gallery. We offer 100 percent high quality budget wall art prints online since 2009. Get 30-70 percent OFF store wide sale, Prints starts $20, FREE Delivery Australia, NZ, USA. We do Worldwide Shipping across 50+ Countries.
https://kamagraes.site/# farmacias online seguras en españa
http://farmacia.best/# farmacia online envÃo gratis
https://tadalafilo.pro/# farmacia online madrid
I haven¦t checked in here for a while because I thought it was getting boring, but the last few posts are good quality so I guess I will add you back to my daily bloglist. You deserve it my friend 🙂
farmacia barata Cialis precio farmacias online seguras en espaГ±a
https://kamagraes.site/# farmacia online internacional
http://sildenafilo.store/# sildenafilo 50 mg comprar online
http://tadalafilo.pro/# farmacias online baratas
Absolutely composed content, Really enjoyed studying.
farmacias online seguras farmacia online barata farmacia online internacional
https://farmacia.best/# farmacia online envÃo gratis
http://farmacia.best/# farmacia online 24 horas
Wonderful blog! I found it while surfing around on Yahoo News. Do you have any suggestions on how to get listed in Yahoo News? I’ve been trying for a while but I never seem to get there! Many thanks
I just like the helpful info you supply in your articles. I’ll bookmark your blog and test again right here frequently. I’m somewhat sure I’ll be told a lot of new stuff proper here! Best of luck for the following!
http://kamagraes.site/# farmacia online madrid
http://vardenafilo.icu/# farmacia 24h
http://farmacia.best/# farmacia online barata
https://farmacia.best/# farmacias online seguras
http://farmacia.best/# farmacia envÃos internacionales
farmacia envГos internacionales mejores farmacias online farmacia 24h
http://kamagraes.site/# farmacia online barata
https://tadalafilo.pro/# farmacia online barata
https://farmacia.best/# farmacias online seguras en españa
http://vardenafilo.icu/# farmacia 24h
very informative articles or reviews at this time.
I have read several good stuff here. Certainly worth bookmarking for revisiting. I surprise how much effort you put to make such a magnificent informative site.
https://vardenafilo.icu/# farmacia online
farmacia online barata farmacia envio gratis farmacias baratas online envГo gratis
https://kamagraes.site/# farmacias online seguras
http://vardenafilo.icu/# farmacias online seguras
http://tadalafilo.pro/# п»їfarmacia online
I very delighted to find this internet site on bing, just what I was searching for as well saved to fav
http://tadalafilo.pro/# farmacias online seguras en españa
Thanks a bunch for sharing this with all of us you actually know what you’re talking about! Bookmarked. Please also visit my site =). We could have a link exchange arrangement between us!
https://vardenafilo.icu/# farmacias baratas online envÃo gratis
http://sildenafilo.store/# comprar viagra en españa envio urgente contrareembolso
http://vardenafilo.icu/# farmacia online barata
farmacia online madrid farmacia online envio gratis murcia farmacias online baratas
Youre so cool! I dont suppose Ive read anything like this before. So nice to seek out somebody with some unique ideas on this subject. realy thank you for beginning this up. this web site is one thing that is wanted on the internet, somebody with a bit of originality. useful job for bringing one thing new to the internet!
https://tadalafilo.pro/# farmacia online
https://kamagraes.site/# farmacia 24h
http://tadalafilo.pro/# farmacias online baratas
http://tadalafilo.pro/# farmacias online seguras en españa
http://tadalafilo.pro/# farmacias online seguras
farmacia 24h Levitra precio farmacia online 24 horas
https://tadalafilo.pro/# farmacia online madrid
http://kamagraes.site/# farmacia online envÃo gratis
I am extremely impressed with your writing skills as well as with the layout on your blog. Is this a paid theme or did you customize it yourself? Either way keep up the excellent quality writing, it’s rare to see a great blog like this one these days..
https://vardenafilo.icu/# farmacia online internacional
I discovered your blog site on google and check a few of your early posts. Continue to keep up the very good operate. I just additional up your RSS feed to my MSN News Reader. Seeking forward to reading more from you later on!…
https://viagrasansordonnance.store/# Le générique de Viagra
http://levitrafr.life/# Pharmacie en ligne livraison rapide
you’re really a good webmaster. The website loading speed is incredible. It seems that you’re doing any unique trick. Furthermore, The contents are masterpiece. you’ve done a excellent job on this topic!
Pharmacie en ligne livraison gratuite: Pharmacie en ligne livraison gratuite – п»їpharmacie en ligne
There are some interesting points in time in this article but I don’t know if I see all of them middle to heart. There’s some validity but I will take maintain opinion until I look into it further. Good article , thanks and we wish more! Added to FeedBurner as nicely
http://pharmacieenligne.guru/# Pharmacie en ligne fiable
I genuinely enjoy examining on this site, it has superb content. “Words are, of course, the most powerful drug used by mankind.” by Rudyard Kipling.
Viagra homme prix en pharmacie Viagra sans ordonnance 24h Acheter Sildenafil 100mg sans ordonnance
https://viagrasansordonnance.store/# Viagra femme ou trouver
http://kamagrafr.icu/# Pharmacie en ligne livraison rapide
http://pharmacieenligne.guru/# Pharmacie en ligne fiable
Pharmacie en ligne sans ordonnance: tadalafil – Pharmacie en ligne France
https://kamagrafr.icu/# acheter medicament a l etranger sans ordonnance
naturally like your web-site however you need to check the spelling on quite a few of your posts. Many of them are rife with spelling issues and I find it very troublesome to inform the reality however I will definitely come back again.
https://kamagrafr.icu/# acheter médicaments à l’étranger
Thanks for the auspicious writeup. It in truth was once a enjoyment account it. Glance complicated to more delivered agreeable from you! By the way, how could we communicate?
http://pharmacieenligne.guru/# Pharmacie en ligne livraison 24h
http://pharmacieenligne.guru/# Pharmacie en ligne livraison 24h
https://cialissansordonnance.pro/# Pharmacie en ligne livraison rapide
acheter medicament a l etranger sans ordonnance: Levitra pharmacie en ligne – Pharmacie en ligne livraison gratuite
https://kamagrafr.icu/# pharmacie en ligne
Acheter mГ©dicaments sans ordonnance sur internet cialis sans ordonnance Pharmacies en ligne certifiГ©es
https://pharmacieenligne.guru/# acheter medicament a l etranger sans ordonnance
https://levitrafr.life/# acheter médicaments à l’étranger
http://levitrafr.life/# Pharmacie en ligne livraison gratuite
https://viagrasansordonnance.store/# Viagra pas cher livraison rapide france
acheter mГ©dicaments Г l’Г©tranger: Pharmacie en ligne sans ordonnance – Pharmacie en ligne pas cher
https://viagrasansordonnance.store/# Sildénafil 100 mg sans ordonnance
Loving the information on this site, you have done great job on the articles.
Very great post. I simply stumbled upon your blog and wished to say that I have truly enjoyed surfing around your blog posts. After all I’ll be subscribing for your rss feed and I’m hoping you write again very soon!
Unquestionably believe that that you stated. Your favorite justification appeared to be at the internet the easiest factor to take into account of. I say to you, I certainly get irked while folks think about issues that they plainly don’t recognise about. You controlled to hit the nail upon the top and defined out the entire thing with no need side effect , people could take a signal. Will probably be again to get more. Thanks
When I originally commented I clicked the -Notify me when new comments are added- checkbox and now each time a comment is added I get four emails with the same comment. Is there any way you can remove me from that service? Thanks!
http://pharmacieenligne.guru/# Pharmacie en ligne livraison rapide
Greetings! I’ve been following your weblog for some time now and finally got the bravery to go ahead and give you a shout out from New Caney Texas! Just wanted to say keep up the excellent work!
п»їpharmacie en ligne Pharmacies en ligne certifiees п»їpharmacie en ligne
https://viagrasansordonnance.store/# Viagra pas cher livraison rapide france
versandapotheke versandkostenfrei Potenzmittel Schneller Besser online-apotheken
This was beautiful Admin. Thank you for your reflections.
https://cialiskaufen.pro/# online apotheke gГјnstig
https://cialiskaufen.pro/# gГјnstige online apotheke
Lovely just what I was looking for.Thanks to the author for taking his clock time on this one.
Can I just say what a relief to find someone who actually knows what theyre talking about on the internet. You definitely know how to bring an issue to light and make it important. More people need to read this and understand this side of the story. I cant believe youre not more popular because you definitely have the gift.
Rattling clean internet site, appreciate it for this post.
I’ve recently started a site, the info you provide on this site has helped me tremendously. Thanks for all of your time & work. “Patriotism is often an arbitrary veneration of real estate above principles.” by George Jean Nathan.
I got this site from my pal who told me concerning this website
and at the moment this time I am browsing this web page and reading very informative articles or reviews at this place.
http://cialiskaufen.pro/# online apotheke deutschland
Sildenafil Preis: viagra bestellen – Viagra diskret bestellen
https://cialiskaufen.pro/# online apotheke gГјnstig
I like the helpful information you supply on your articles. I’ll bookmark your weblog and check once more here regularly. I am slightly sure I will be told plenty of new stuff right right here! Good luck for the next!
Hey there! This post couldn’t be written any better! Reading this post reminds me of my old room mate! He always kept chatting about this. I will forward this article to him. Pretty sure he will have a good read. Thank you for sharing!
http://cialiskaufen.pro/# versandapotheke versandkostenfrei
online-apotheken: kamagra jelly kaufen – п»їonline apotheke
Great post. I was checking constantly this blog and I’m impressed! Extremely useful information particularly the last part 🙂 I care for such info much. I was looking for this certain info for a very long time. Thank you and best of luck.
medicine in mexico pharmacies mexican online pharmacies prescription drugs pharmacies in mexico that ship to usa
best mexican online pharmacies medicine in mexico pharmacies mexican border pharmacies shipping to usa
I have been absent for some time, but now I remember why I used to love this web site. Thanks, I will try and check back more frequently. How frequently you update your web site?
https://mexicanpharmacy.cheap/# reputable mexican pharmacies online
medicine in mexico pharmacies mexico drug stores pharmacies best mexican online pharmacies
I will right away grab your rss feed as I can’t find your e-mail subscription link or newsletter service. Do you’ve any? Kindly let me realize so that I may subscribe. Thanks.
http://mexicanpharmacy.cheap/# mexican rx online
mexico pharmacy buying prescription drugs in mexico pharmacies in mexico that ship to usa
mexican online pharmacies prescription drugs mexican mail order pharmacies buying from online mexican pharmacy
buying prescription drugs in mexico online mexican pharmacy buying prescription drugs in mexico
mexican drugstore online medicine in mexico pharmacies mexican mail order pharmacies
mexican online pharmacies prescription drugs medication from mexico pharmacy buying from online mexican pharmacy
mexican pharmaceuticals online mexican mail order pharmacies buying prescription drugs in mexico online
Super-Duper website! I am loving it!! Will come back again. I am taking your feeds also
best online pharmacies in mexico mexican pharmaceuticals online mexican drugstore online
Thanks for another great post. Where else may anybody get that kind of info in such an ideal means of writing? I have a presentation subsequent week, and I am on the search for such information.
http://mexicanpharmacy.cheap/# mexican pharmaceuticals online
Boostaro increases blood flow to the reproductive organs, leading to stronger and more vibrant erections. It provides a powerful boost that can make you feel like you’ve unlocked the secret to firm erections
ErecPrime is a 100% natural supplement which is designed specifically
Puravive introduced an innovative approach to weight loss and management that set it apart from other supplements.
mexico pharmacy buying prescription drugs in mexico online mexican drugstore online
best online pharmacies in mexico best online pharmacies in mexico buying prescription drugs in mexico online
pharmacies in mexico that ship to usa mexico drug stores pharmacies buying prescription drugs in mexico online
mexico drug stores pharmacies mexican drugstore online mexican border pharmacies shipping to usa
Prostadine™ is a revolutionary new prostate support supplement designed to protect, restore, and enhance male prostate health.
mexican online pharmacies prescription drugs mexican border pharmacies shipping to usa mexican mail order pharmacies
Абузоустойчивый серверы, идеально подходит для работы програмным обеспечением как XRumer так и GSA
Стабильная работа без сбоев, высокая поточность несравнима с провайдерами в квартире или офисе, где есть ограничение.
Высокоскоростной Интернет: До 1000 Мбит/с
Скорость интернет-соединения – еще один важный параметр для успешной работы вашего проекта. Наши VPS/VDS серверы, поддерживающие Windows и Linux, обеспечивают доступ к интернету со скоростью до 1000 Мбит/с, обеспечивая быструю загрузку веб-страниц и высокую производительность онлайн-приложений.
Aizen Power is a dietary supplement for male enhancement
http://mexicanpharmacy.cheap/# reputable mexican pharmacies online
http://mexicanpharmacy.cheap/# mexican mail order pharmacies
buying prescription drugs in mexico reputable mexican pharmacies online mexican mail order pharmacies
Neotonics is a dietary supplement that offers help in retaining glowing skin and maintaining gut health for its users. It is made of the most natural elements that mother nature can offer and also includes 500 million units of beneficial microbiome.
pharmacies in mexico that ship to usa mexican border pharmacies shipping to usa mexico drug stores pharmacies
EndoPeak is a male health supplement with a wide range of natural ingredients that improve blood circulation and vitality.
Glucotrust is one of the best supplements for managing blood sugar levels or managing healthy sugar metabolism.
EyeFortin is a natural vision support formula crafted with a blend of plant-based compounds and essential minerals. It aims to enhance vision clarity, focus, and moisture balance.
medicine in mexico pharmacies purple pharmacy mexico price list mexican mail order pharmacies
Support the health of your ears with 100% natural ingredients, finally being able to enjoy your favorite songs and movies
GlucoBerry is a meticulously crafted supplement designed by doctors to support healthy blood sugar levels by harnessing the power of delphinidin—an essential compound.
best mexican online pharmacies best online pharmacies in mexico mexican pharmaceuticals online
Free Shiping If You Purchase Today!
buying from online mexican pharmacy buying prescription drugs in mexico purple pharmacy mexico price list
Hey, you used to write excellent, but the last few posts have been kinda boring?K I miss your great writings. Past few posts are just a little out of track! come on!
I have been reading out many of your posts and i must say pretty good stuff. I will surely bookmark your website.
https://mexicanpharmacy.company/# mexican pharmacy mexicanpharmacy.company
https://edpills.tech/# best treatment for ed edpills.tech
SonoVive™ is a completely natural hearing support formula made with powerful ingredients that help heal tinnitus problems and restore your hearing
BioFit™ is a Nutritional Supplement That Uses Probiotics To Help You Lose Weight
buy ed pills ed pills online – ed drug prices edpills.tech
http://canadiandrugs.tech/# canadian world pharmacy canadiandrugs.tech
This is really interesting, You’re a very skilled blogger. I’ve joined your feed and look forward to seeking more of your magnificent post. Also, I’ve shared your site in my social networks!
canada pharmacy world legal to buy prescription drugs from canada – canadian pharmacies comparison canadiandrugs.tech
http://edpills.tech/# best ed drug edpills.tech
The ingredients of Endo Pump Male Enhancement are all-natural and safe to use.
Gorilla Flow is a non-toxic supplement that was developed by experts to boost prostate health for men.
オンラインカジノとオンラインギャンブルの現代的展開
オンラインカジノの世界は、技術の進歩と共に急速に進化しています。これらのプラットフォームは、従来の実際のカジノの体験をデジタル空間に移し、プレイヤーに新しい形式の娯楽を提供しています。オンラインカジノは、スロットマシン、ポーカー、ブラックジャック、ルーレットなど、さまざまなゲームを提供しており、実際のカジノの興奮を維持しながら、アクセスの容易さと利便性を提供します。
一方で、オンラインギャンブルは、より広範な概念であり、スポーツベッティング、宝くじ、バーチャルスポーツ、そしてオンラインカジノゲームまでを含んでいます。インターネットとモバイルテクノロジーの普及により、オンラインギャンブルは世界中で大きな人気を博しています。オンラインプラットフォームは、伝統的な賭博施設に比べて、より多様なゲーム選択、便利なアクセス、そしてしばしば魅力的なボーナスやプロモーションを提供しています。
安全性と規制
オンラインカジノとオンラインギャンブルの世界では、安全性と規制が非常に重要です。多くの国々では、オンラインギャンブルを規制する法律があり、安全なプレイ環境を確保するためのライセンスシステムを設けています。これにより、不正行為や詐欺からプレイヤーを守るとともに、責任ある賭博の促進が図られています。
技術の進歩
最新のテクノロジーは、オンラインカジノとオンラインギャンブルの体験を一層豊かにしています。例えば、仮想現実(VR)技術の使用は、プレイヤーに没入型のギャンブル体験を提供し、実際のカジノにいるかのような感覚を生み出しています。また、ブロックチェーン技術の導入は、より透明で安全な取引を可能にし、プレイヤーの信頼を高めています。
未来への展望
オンラインカジノとオンラインギャンブルは、今後も技術の進歩とともに進化し続けるでしょう。人工知能(AI)の更なる統合、モバイル技術の発展、さらには新しいゲームの創造により、この分野は引き続き成長し、世界中のプレイヤーに新しい娯楽の形を提供し続けることでしょう。
この記事では、オンラインカジノとオンラインギャンブルの現状、安全性、技術の影響、そして将来の展望に焦点を当てています。この分野は、技術革新によって絶えず変化し続ける魅力的な領域です。
Tải Hit Club iOS
Tải Hit Club iOSHIT CLUBHit Club đã sáng tạo ra một giao diện game đẹp mắt và hoàn thiện, lấy cảm hứng từ các cổng casino trực tuyến chất lượng từ cổ điển đến hiện đại. Game mang lại sự cân bằng và sự kết hợp hài hòa giữa phong cách sống động của sòng bạc Las Vegas và phong cách chân thực. Tất cả các trò chơi đều được bố trí tinh tế và hấp dẫn với cách bố trí game khoa học và logic giúp cho người chơi có được trải nghiệm chơi game tốt nhất.
Hit Club – Cổng Game Đổi Thưởng
Trên trang chủ của Hit Club, người chơi dễ dàng tìm thấy các game bài, tính năng hỗ trợ và các thao tác để rút/nạp tiền cùng với cổng trò chuyện trực tiếp để được tư vấn. Giao diện game mang lại cho người chơi cảm giác chân thật và thoải mái nhất, giúp người chơi không bị mỏi mắt khi chơi trong thời gian dài.
Hướng Dẫn Tải Game Hit Club
Bạn có thể trải nghiệm Hit Club với 2 phiên bản: Hit Club APK cho thiết bị Android và Hit Club iOS cho thiết bị như iPhone, iPad.
Tải ứng dụng game:
Click nút tải ứng dụng game ở trên (phiên bản APK/Android hoặc iOS tùy theo thiết bị của bạn).
Chờ cho quá trình tải xuống hoàn tất.
Cài đặt ứng dụng:
Khi quá trình tải xuống hoàn tất, mở tệp APK hoặc iOS và cài đặt ứng dụng trên thiết bị của bạn.
Bắt đầu trải nghiệm:
Mở ứng dụng và bắt đầu trải nghiệm Hit Club.
Với Hit Club, bạn sẽ khám phá thế giới game đỉnh cao với giao diện đẹp mắt và trải nghiệm chơi game tuyệt vời. Hãy tải ngay để tham gia vào cuộc phiêu lưu casino độc đáo và đầy hứng khởi!
http://edpills.tech/# best ed drug edpills.tech
https://indiapharmacy.guru/# indian pharmacy paypal indiapharmacy.guru
http://canadiandrugs.tech/# canada pharmacy reviews canadiandrugs.tech
http://canadiandrugs.tech/# canadian pharmacies online canadiandrugs.tech
GlucoCare is a natural and safe supplement for blood sugar support and weight management. It fixes your metabolism and detoxifies your body.
Nervogen Pro, A Cutting-Edge Supplement Dedicated To Enhancing Nerve Health And Providing Natural Relief From Discomfort. Our Mission Is To Empower You To Lead A Life Free From The Limitations Of Nerve-Related Challenges. With A Focus On Premium Ingredients And Scientific Expertise.
http://edpills.tech/# cheap erectile dysfunction edpills.tech
Neurodrine is a fantastic dietary supplement that protects your mind and improves memory performance. It can help you improve your focus and concentration.
reliable canadian pharmacy recommended canadian pharmacies – canadian pharmacy online canadiandrugs.tech
InchaGrow is an advanced male enhancement supplement. The Formula is Easy to Take Each Day, and it Only Uses. Natural Ingredients to Get the Desired Effect
There are actually a lot of particulars like that to take into consideration. That may be a great point to convey up. I supply the ideas above as basic inspiration however clearly there are questions like the one you bring up where crucial factor will be working in sincere good faith. I don?t know if finest practices have emerged round issues like that, but I am certain that your job is clearly recognized as a good game. Both boys and girls feel the affect of just a moment?s pleasure, for the remainder of their lives.
GlucoFlush™ is an all-natural supplement that uses potent ingredients to control your blood sugar.
online canadian drugstore legal to buy prescription drugs from canada – canadian pharmacy in canada canadiandrugs.tech
https://canadiandrugs.tech/# canada rx pharmacy world canadiandrugs.tech
SynoGut is a natural dietary supplement specifically formulated to support digestive function and promote a healthy gut microbiome.
https://indiapharmacy.guru/# top 10 pharmacies in india indiapharmacy.guru
Amiclear is a dietary supplement designed to support healthy blood sugar levels and assist with glucose metabolism. It contains eight proprietary blends of ingredients that have been clinically proven to be effective.
https://indiapharmacy.guru/# indian pharmacy online indiapharmacy.guru
hit club
Tải Hit Club iOS
Tải Hit Club iOSHIT CLUBHit Club đã sáng tạo ra một giao diện game đẹp mắt và hoàn thiện, lấy cảm hứng từ các cổng casino trực tuyến chất lượng từ cổ điển đến hiện đại. Game mang lại sự cân bằng và sự kết hợp hài hòa giữa phong cách sống động của sòng bạc Las Vegas và phong cách chân thực. Tất cả các trò chơi đều được bố trí tinh tế và hấp dẫn với cách bố trí game khoa học và logic giúp cho người chơi có được trải nghiệm chơi game tốt nhất.
Hit Club – Cổng Game Đổi Thưởng
Trên trang chủ của Hit Club, người chơi dễ dàng tìm thấy các game bài, tính năng hỗ trợ và các thao tác để rút/nạp tiền cùng với cổng trò chuyện trực tiếp để được tư vấn. Giao diện game mang lại cho người chơi cảm giác chân thật và thoải mái nhất, giúp người chơi không bị mỏi mắt khi chơi trong thời gian dài.
Hướng Dẫn Tải Game Hit Club
Bạn có thể trải nghiệm Hit Club với 2 phiên bản: Hit Club APK cho thiết bị Android và Hit Club iOS cho thiết bị như iPhone, iPad.
Tải ứng dụng game:
Click nút tải ứng dụng game ở trên (phiên bản APK/Android hoặc iOS tùy theo thiết bị của bạn).
Chờ cho quá trình tải xuống hoàn tất.
Cài đặt ứng dụng:
Khi quá trình tải xuống hoàn tất, mở tệp APK hoặc iOS và cài đặt ứng dụng trên thiết bị của bạn.
Bắt đầu trải nghiệm:
Mở ứng dụng và bắt đầu trải nghiệm Hit Club.
Với Hit Club, bạn sẽ khám phá thế giới game đỉnh cao với giao diện đẹp mắt và trải nghiệm chơi game tuyệt vời. Hãy tải ngay để tham gia vào cuộc phiêu lưu casino độc đáo và đầy hứng khởi!
https://indiapharmacy.guru/# top 10 online pharmacy in india indiapharmacy.guru
https://indiapharmacy.guru/# legitimate online pharmacies india indiapharmacy.guru
erection pills viagra online ed pills for sale – impotence pills edpills.tech
https://indiapharmacy.guru/# india pharmacy indiapharmacy.guru
オンラインカジノ
オンラインカジノとオンラインギャンブルの現代的展開
オンラインカジノの世界は、技術の進歩と共に急速に進化しています。これらのプラットフォームは、従来の実際のカジノの体験をデジタル空間に移し、プレイヤーに新しい形式の娯楽を提供しています。オンラインカジノは、スロットマシン、ポーカー、ブラックジャック、ルーレットなど、さまざまなゲームを提供しており、実際のカジノの興奮を維持しながら、アクセスの容易さと利便性を提供します。
一方で、オンラインギャンブルは、より広範な概念であり、スポーツベッティング、宝くじ、バーチャルスポーツ、そしてオンラインカジノゲームまでを含んでいます。インターネットとモバイルテクノロジーの普及により、オンラインギャンブルは世界中で大きな人気を博しています。オンラインプラットフォームは、伝統的な賭博施設に比べて、より多様なゲーム選択、便利なアクセス、そしてしばしば魅力的なボーナスやプロモーションを提供しています。
安全性と規制
オンラインカジノとオンラインギャンブルの世界では、安全性と規制が非常に重要です。多くの国々では、オンラインギャンブルを規制する法律があり、安全なプレイ環境を確保するためのライセンスシステムを設けています。これにより、不正行為や詐欺からプレイヤーを守るとともに、責任ある賭博の促進が図られています。
技術の進歩
最新のテクノロジーは、オンラインカジノとオンラインギャンブルの体験を一層豊かにしています。例えば、仮想現実(VR)技術の使用は、プレイヤーに没入型のギャンブル体験を提供し、実際のカジノにいるかのような感覚を生み出しています。また、ブロックチェーン技術の導入は、より透明で安全な取引を可能にし、プレイヤーの信頼を高めています。
未来への展望
オンラインカジノとオンラインギャンブルは、今後も技術の進歩とともに進化し続けるでしょう。人工知能(AI)の更なる統合、モバイル技術の発展、さらには新しいゲームの創造により、この分野は引き続き成長し、世界中のプレイヤーに新しい娯楽の形を提供し続けることでしょう。
この記事では、オンラインカジノとオンラインギャンブルの現状、安全性、技術の影響、そして将来の展望に焦点を当てています。この分野は、技術革新によって絶えず変化し続ける魅力的な領域です。
Абузоустойчивый сервер для работы с Хрумером, GSA и всевозможными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Высокоскоростной Интернет: До 1000 Мбит/с
Скорость Интернет-соединения – еще один ключевой фактор для успешной работы вашего проекта. Наши VPS/VDS серверы, поддерживающие Windows и Linux, обеспечивают доступ к интернету со скоростью до 1000 Мбит/с, гарантируя быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
Воспользуйтесь нашим предложением VPS/VDS серверов и обеспечьте стабильность и производительность вашего проекта. Посоветуйте VPS – ваш путь к успешному онлайн-присутствию!
natural remedies for ed over the counter erectile dysfunction pills – best ed medications edpills.tech
https://edpills.tech/# best ed treatment pills edpills.tech
Claritox Pro™ is a natural dietary supplement that is formulated to support brain health and promote a healthy balance system to prevent dizziness, risk injuries, and disability. This formulation is made using naturally sourced and effective ingredients that are mixed in the right way and in the right amounts to deliver effective results.
Metabo Flex is a nutritional formula that enhances metabolic flexibility by awakening the calorie-burning switch in the body. The supplement is designed to target the underlying causes of stubborn weight gain utilizing a special “miracle plant” from Cambodia that can melt fat 24/7.
SynoGut is an all-natural dietary supplement that is designed to support the health of your digestive system, keeping you energized and active.
Manufactured in an FDA-certified facility in the USA, EndoPump is pure, safe, and free from negative side effects. With its strict production standards and natural ingredients, EndoPump is a trusted choice for men looking to improve their sexual performance.
Nervogen Pro is a cutting-edge dietary supplement that takes a holistic approach to nerve health. It is meticulously crafted with a precise selection of natural ingredients known for their beneficial effects on the nervous system. By addressing the root causes of nerve discomfort, Nervogen Pro aims to provide lasting relief and support for overall nerve function.
While Inchagrow is marketed as a dietary supplement, it is important to note that dietary supplements are regulated by the FDA. This means that their safety and effectiveness, and there is 60 money back guarantee that Inchagrow will work for everyone.
Gorilla Flow is a non-toxic supplement that was developed by experts to boost prostate health for men. It’s a blend of all-natural nutrients, including Pumpkin Seed Extract Stinging Nettle Extract, Gorilla Cherry and Saw Palmetto, Boron, and Lycopene.
Herpagreens is a dietary supplement formulated to combat symptoms of herpes by providing the body with high levels of super antioxidants, vitamins
Dentitox Pro is a liquid dietary solution created as a serum to support healthy gums and teeth. Dentitox Pro formula is made in the best natural way with unique, powerful botanical ingredients that can support healthy teeth.
FitSpresso stands out as a remarkable dietary supplement designed to facilitate effective weight loss. Its unique blend incorporates a selection of natural elements including green tea extract, milk thistle, and other components with presumed weight loss benefits.
Introducing FlowForce Max, a solution designed with a single purpose: to provide men with an affordable and safe way to address BPH and other prostate concerns. Unlike many costly supplements or those with risky stimulants, we’ve crafted FlowForce Max with your well-being in mind. Don’t compromise your health or budget – choose FlowForce Max for effective prostate support today!
ProDentim is a nutritional dental health supplement that is formulated to reverse serious dental issues and to help maintain good dental health.
SonoVive is an all-natural supplement made to address the root cause of tinnitus and other inflammatory effects on the brain and promises to reduce tinnitus, improve hearing, and provide peace of mind. SonoVive is is a scientifically verified 10-second hack that allows users to hear crystal-clear at maximum volume. The 100% natural mix recipe improves the ear-brain link with eight natural ingredients. The treatment consists of easy-to-use pills that can be added to one’s daily routine to improve hearing health, reduce tinnitus, and maintain a sharp mind and razor-sharp focus.
https://canadapharmacy.guru/# canada pharmacy canadapharmacy.guru
https://indiapharmacy.guru/# india online pharmacy indiapharmacy.guru
TerraCalm is an antifungal mineral clay that may support the health of your toenails. It is for those who struggle with brittle, weak, and discoloured nails. It has a unique blend of natural ingredients that may work to nourish and strengthen your toenails.
https://edpills.tech/# best ed pills edpills.tech
http://indiapharmacy.guru/# buy medicines online in india indiapharmacy.guru
world pharmacy india world pharmacy india online shopping pharmacy india indiapharmacy.guru
http://edpills.tech/# medicine for impotence edpills.tech
Дедик сервер
Абузоустойчивый сервер для работы с Хрумером, GSA и всевозможными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Виртуальные сервера (VPS/VDS) и Дедик Сервер: Оптимальное Решение для Вашего Проекта
В мире современных вычислений виртуальные сервера (VPS/VDS) и дедик сервера становятся ключевыми элементами успешного бизнеса и онлайн-проектов. Выбор оптимальной операционной системы и типа сервера являются решающими шагами в создании надежной и эффективной инфраструктуры. Наши VPS/VDS серверы Windows и Linux, доступные от 13 рублей, а также дедик серверы, предлагают целый ряд преимуществ, делая их неотъемлемыми инструментами для развития вашего проекта.
http://indiapharmacy.guru/# buy medicines online in india indiapharmacy.guru
safe canadian pharmacies canada ed drugs – ed meds online canada canadiandrugs.tech
Как включить аппаратную виртуализацию
Абузоустойчивый серверов для Хрумера и GSA AMSTERDAM!!!
Оптимальная Настройка: Включение Аппаратной Виртуализации
При обсуждении виртуальных серверов (VPS/VDS) и дедикатед серверов, важно также уделить внимание оптимальной настройке, включая аппаратную виртуализацию. Этот важный аспект может значительно повлиять на производительность вашего сервера.
Высокоскоростной Интернет: До 1000 Мбит/с
This design is incredible! You obviously know how to keep a reader entertained. Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Great job. I really loved what you had to say, and more than that, how you presented it. Too cool!
https://indiapharmacy.guru/# mail order pharmacy india indiapharmacy.guru
Дедикатед Серверы
Абузоустойчивые сервера в Амстердаме, они позволят работать с сайтами которые не открываются в РФ, работая Хрумером и GSA пробив намного выше.
Виртуальные сервера (VPS/VDS) и Дедик Сервер: Оптимальное Решение для Вашего Проекта
В мире современных вычислений виртуальные сервера (VPS/VDS) и дедик сервера становятся ключевыми элементами успешного бизнеса и онлайн-проектов. Выбор оптимальной операционной системы и типа сервера являются решающими шагами в создании надежной и эффективной инфраструктуры. Наши VPS/VDS серверы Windows и Linux, доступные от 13 рублей, а также дедик серверы, предлагают целый ряд преимуществ, делая их неотъемлемыми инструментами для развития вашего проекта.
Высокоскоростной Интернет: До 1000 Мбит/с
canadian pharmacy 365 best canadian pharmacy online – canadian pharmacy meds canadiandrugs.tech
http://indiapharmacy.guru/# top 10 pharmacies in india indiapharmacy.guru
http://canadiandrugs.tech/# canadian pharmacy mall canadiandrugs.tech
https://edpills.tech/# herbal ed treatment edpills.tech
http://indiapharmacy.pro/# indian pharmacy indiapharmacy.pro
https://edpills.tech/# what are ed drugs edpills.tech
https://indiapharmacy.guru/# top 10 pharmacies in india indiapharmacy.guru
best erection pills over the counter erectile dysfunction pills – medication for ed dysfunction edpills.tech
https://edpills.tech/# cheap ed pills edpills.tech
erection pills viagra online best ed drug – best drug for ed edpills.tech
ed medication online ed medications online medicine erectile dysfunction edpills.tech
https://indiapharmacy.guru/# buy medicines online in india indiapharmacy.guru
It’s a shame you don’t have a donate button! I’d most certainly donate to this fantastic blog! I suppose for now i’ll settle for bookmarking and adding your RSS feed to my Google account. I look forward to brand new updates and will share this site with my Facebook group. Chat soon!
where to buy generic clomid no prescription: where to buy clomid pill – can i get cheap clomid without rx
Как включить аппаратную виртуализацию
Абузоустойчивый серверов для Хрумера и GSA AMSTERDAM!!!
Высокоскоростной Интернет: До 1000 Мбит/с
Скорость интернет-соединения играет решающую роль в успешной работе вашего проекта. Наши VPS/VDS серверы, поддерживающие Windows и Linux, обеспечивают доступ к интернету со скоростью до 1000 Мбит/с. Это гарантирует быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
Итак, при выборе виртуального выделенного сервера VPS, обеспечьте своему проекту надежность, высокую производительность и защиту от DDoS. Получите доступ к качественной инфраструктуре с поддержкой Windows и Linux уже от 13 рублей
prednisone in uk: prednisone for sale no prescription – prednisone in mexico
http://prednisone.bid/# price of prednisone 5mg
paxlovid for sale: paxlovid cost without insurance – paxlovid cost without insurance
Very excellent info can be found on web blog.
5 mg prednisone tablets: prednisone in india – prednisone 20mg online without prescription
Аренда виртуального сервера vps
Абузоустойчивые сервера в Амстердаме, они позволят работать с сайтами которые не открываются в РФ, работая Хрумером и GSA пробив намного выше.
Аренда виртуального сервера (VPS): Эффективность, Надежность и Защита от DDoS от 13 рублей
Выбор виртуального сервера – это важный этап в создании успешной инфраструктуры для вашего проекта. Наши VPS серверы предоставляют аренду как под операционные системы Windows, так и Linux, с доступом к накопителям SSD eMLC. Эти накопители гарантируют высокую производительность и надежность, обеспечивая бесперебойную работу ваших приложений независимо от выбранной операционной системы.
Great article! That is the kind of info that should be shared around the net.
Disgrace on Google for now not positioning this post upper!
Come on over and talk over with my web site .
Thanks =)
виртуальный выделенный сервер vps
Абузоустойчивый сервер для работы с Хрумером, GSA и всевозможными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Высокоскоростной Интернет: До 1000 Мбит/с
Скорость интернет-соединения играет решающую роль в успешной работе вашего проекта. Наши VPS/VDS серверы, поддерживающие Windows и Linux, обеспечивают доступ к интернету со скоростью до 1000 Мбит/с. Это гарантирует быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
Итак, при выборе виртуального выделенного сервера VPS, обеспечьте своему проекту надежность, высокую производительность и защиту от DDoS. Получите доступ к качественной инфраструктуре с поддержкой Windows и Linux уже от 13 рублей
paxlovid pharmacy: paxlovid price – paxlovid pharmacy
paxlovid: paxlovid india – paxlovid pharmacy
Hi! Quick question that’s entirely off topic. Do you know how to make your site mobile friendly? My weblog looks weird when browsing from my apple iphone. I’m trying to find a theme or plugin that might be able to correct this problem. If you have any recommendations, please share. Cheers!
Аренда мощного дедика (VPS): Абузоустойчивость, Эффективность, Надежность и Защита от DDoS от 13 рублей
Выбор виртуального сервера – это важный этап в создании успешной инфраструктуры для вашего проекта. Наши VPS серверы предоставляют аренду как под операционные системы Windows, так и Linux, с доступом к накопителям SSD eMLC. Эти накопители гарантируют высокую производительность и надежность, обеспечивая бесперебойную работу ваших приложений независимо от выбранной операционной системы.
how to buy clomid without prescription: order generic clomid pills – can you buy clomid prices
prednisone in canada: prednisone 250 mg – how much is prednisone 10 mg
http://amoxil.icu/# amoxicillin capsule 500mg price
Абузоустойчивый сервер для работы с Хрумером, GSA и всевозможными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Высокоскоростной Интернет: До 1000 Мбит/с**
Скорость интернет-соединения – еще один важный момент для успешной работы вашего проекта. Наши VPS серверы, арендуемые под Windows и Linux, предоставляют доступ к интернету со скоростью до 1000 Мбит/с, обеспечивая быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
where to buy amoxicillin over the counter: amoxicillin 500 mg – medicine amoxicillin 500
I’ll immediately grab your rss as I can’t find your e-mail subscription link or e-newsletter service. Do you have any? Kindly let me know in order that I could subscribe. Thanks.
http://ciprofloxacin.life/# ciprofloxacin mail online
buy paxlovid online: paxlovid for sale – paxlovid cost without insurance
paxlovid for sale: paxlovid for sale – paxlovid buy
Fantastic site you have here but I was wondering if you knew of any discussion boards that cover the same topics talked about in this article? I’d really love to be a part of community where I can get feed-back from other knowledgeable individuals that share the same interest. If you have any recommendations, please let me know. Cheers!
paxlovid: paxlovid price – paxlovid for sale
how can i get cheap clomid without dr prescription: where can i get cheap clomid without dr prescription – where to buy cheap clomid no prescription
paxlovid pharmacy: paxlovid cost without insurance – paxlovid buy
https://prednisone.bid/# 20mg prednisone
paxlovid for sale: paxlovid price – paxlovid pill
Thanks for finally writing about > There is A Revolution Ahead and It Has A Voice
– Tech.pinions < Loved it!
cipro for sale: ciprofloxacin order online – purchase cipro
cost cheap clomid now: cost of clomid for sale – cost cheap clomid now
how can i get cheap clomid no prescription how can i get cheap clomid price cost generic clomid pill
Great information shared.. really enjoyed reading this post thank you author for sharing this post .. appreciated
buy prednisone online fast shipping: average cost of prednisone – prednisone cream rx
http://paxlovid.win/# Paxlovid over the counter
paxlovid price: Paxlovid over the counter – paxlovid for sale
Мощный дедик
Аренда мощного дедика (VPS): Абузоустойчивость, Эффективность, Надежность и Защита от DDoS от 13 рублей
В современном мире онлайн-проекты нуждаются в надежных и производительных серверах для бесперебойной работы. И здесь на помощь приходят мощные дедики, которые обеспечивают и высокую производительность, и защищенность от атак DDoS. Компания “Название” предлагает VPS/VDS серверы, работающие как на Windows, так и на Linux, с доступом к накопителям SSD eMLC — это значительно улучшает работу и надежность сервера.
can you buy prednisone without a prescription: prednisone medication – prednisone 5 tablets
http://ciprofloxacin.life/# buy cipro cheap
Howdy! I know this is kinda off topic however I’d figured I’d ask. Would you be interested in trading links or maybe guest writing a blog post or vice-versa? My site covers a lot of the same subjects as yours and I think we could greatly benefit from each other. If you are interested feel free to shoot me an email. I look forward to hearing from you! Wonderful blog by the way!
Merely wanna input on few general things, The website design and style is perfect, the articles is really fantastic : D.
https://paxlovid.win/# paxlovid generic
I have learn a few good stuff here. Definitely price bookmarking for revisiting. I wonder how a lot effort you put to create such a excellent informative site.
Can I just say what a relief to find someone who actually knows what theyre talking about on the internet. You definitely know how to bring an issue to light and make it important. More people need to read this and understand this side of the story. I cant believe youre not more popular because you definitely have the gift.
cipro: cipro pharmacy – ciprofloxacin over the counter
amoxicillin 775 mg amoxicillin 200 mg tablet amoxicillin 500mg price canada
http://clomid.site/# cheap clomid pill
Абузоустойчивый сервер для работы с Хрумером, GSA и всевозможными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Виртуальные сервера (VPS/VDS) и Дедик Сервер: Оптимальное Решение для Вашего Проекта
В мире современных вычислений виртуальные сервера (VPS/VDS) и дедик сервера становятся ключевыми элементами успешного бизнеса и онлайн-проектов. Выбор оптимальной операционной системы и типа сервера являются решающими шагами в создании надежной и эффективной инфраструктуры. Наши VPS/VDS серверы Windows и Linux, доступные от 13 рублей, а также дедик серверы, предлагают целый ряд преимуществ, делая их неотъемлемыми инструментами для развития вашего проекта.
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point. You obviously know what youre talking about, why waste your intelligence on just posting videos to your weblog when you could be giving us something informative to read?
Cortexi is an effective hearing health support formula that has gained positive user feedback for its ability to improve hearing ability and memory. This supplement contains natural ingredients and has undergone evaluation to ensure its efficacy and safety. Manufactured in an FDA-registered and GMP-certified facility, Cortexi promotes healthy hearing, enhances mental acuity, and sharpens memory.
Buy discount supplements, vitamins, health supplements, probiotic supplements. Save on top vitamin and supplement brands.
While improving eyesight isn’t often the goal of consumers who wear their glasses religiously, it doesn’t mean they’re stuck where they are.
Excellent goods from you, man. I’ve understand your stuff previous to and you’re simply extremely magnificent. I really like what you have obtained here, certainly like what you are saying and the best way through which you say it. You are making it enjoyable and you continue to care for to stay it wise. I cant wait to read far more from you. This is really a great web site.
Wow! This could be one particular of the most useful blogs We’ve ever arrive across on this subject. Actually Wonderful. I am also an expert in this topic therefore I can understand your hard work.
This design is wicked! You certainly know how to keep a reader entertained. Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Great job. I really loved what you had to say, and more than that, how you presented it. Too cool!
Just wish to say your article is as surprising. The clearness in your post is just great and i could assume you are an expert on this subject. Well with your permission allow me to grab your RSS feed to keep up to date with forthcoming post. Thanks a million and please continue the rewarding work.
Superb blog! Do you have any hints for aspiring writers? I’m hoping to start my own blog soon but I’m a little lost on everything. Would you propose starting with a free platform like WordPress or go for a paid option? There are so many choices out there that I’m completely confused .. Any tips? Thanks a lot!
Sight Care is a daily supplement proven in clinical trials and conclusive science to improve vision by nourishing the body from within. The Sight Care formula claims to reverse issues in eyesight, and every ingredient is completely natural.
посоветуйте vps
осоветуйте vps
Абузоустойчивый сервер для работы с Хрумером и GSA и различными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Виртуальные сервера VPS/VDS и Дедик Сервер: Оптимальное Решение для Вашего Проекта
В мире современных вычислений виртуальные сервера VPS/VDS и дедик сервера становятся ключевыми элементами успешного бизнеса и онлайн-проектов. Выбор оптимальной операционной системы и типа сервера являются решающими шагами в создании надежной и эффективной инфраструктуры. Наши VPS/VDS серверы Windows и Linux, доступные от 13 рублей, а также дедик серверы, предлагают целый ряд преимуществ, делая их неотъемлемыми инструментами для развития вашего проекта.
Great blog! Is your theme custom made or did you download it from somewhere? A design like yours with a few simple adjustements would really make my blog shine. Please let me know where you got your design. Many thanks
My wife and i have been contented Emmanuel managed to finish up his preliminary research by way of the ideas he had from your site. It’s not at all simplistic just to continually be giving for free strategies the others have been selling. So we fully understand we have the blog owner to be grateful to for that. The main explanations you have made, the straightforward website navigation, the friendships you will give support to engender – it’s got all impressive, and it’s really helping our son in addition to the family know that that topic is enjoyable, which is quite pressing. Thanks for the whole lot!
GlucoBerry is one of the biggest all-natural dietary and biggest scientific breakthrough formulas ever in the health industry today. This is all because of its amazing high-quality cutting-edge formula that helps treat high blood sugar levels very naturally and effectively.
Free Shiping If You Purchase Today!
EndoPump is an all-natural male enhancement supplement that improves libido, sexual health, and penile muscle strength.
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.
Thanks for sharing superb informations. Your site is so cool. I am impressed by the details that you’ve on this website. It reveals how nicely you understand this subject. Bookmarked this web page, will come back for extra articles. You, my pal, ROCK! I found just the information I already searched everywhere and just couldn’t come across. What an ideal site.
民意調查
民調
I couldn’t resist commenting
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
GlucoTrust is a revolutionary blood sugar support solution that eliminates the underlying causes of type 2 diabetes and associated health risks.
EyeFortin is a natural vision support formula crafted with a blend of plant-based compounds and essential minerals. It aims to enhance vision clarity, focus, and moisture balance.
Neotonics is an essential probiotic supplement that works to support the microbiome in the gut and also works as an anti-aging formula. The formula targets the cause of the aging of the skin.
Erec Prime is a cutting-edge male enhancement formula with high quality raw ingredients designed to enhance erection quality and duration, providing increased stamina and a heightened libido.
Puravive introduced an innovative approach to weight loss and management that set it apart from other supplements. It enhances the production and storage of brown fat in the body, a stark contrast to the unhealthy white fat that contributes to obesity.
With its all-natural ingredients and impressive results, Aizen Power supplement is quickly becoming a popular choice for anyone looking for an effective solution for improve sexual health with this revolutionary treatment.
t’s Time To Say Goodbye To All Your Bedroom Troubles And Enjoy The Ultimate Satisfaction And Give Her The Leg-shaking Orgasms. The Endopeak Is Your True Partner To Build Those Monster Powers In Your Manhood You Ever Craved For..
Prostadine is a dietary supplement meticulously formulated to support prostate health, enhance bladder function, and promote overall urinary system well-being. Crafted from a blend of entirely natural ingredients, Prostadine draws upon a recent groundbreaking discovery by Harvard scientists.
HoneyBurn is a 100% natural honey mixture formula that can support both your digestive health and fat-burning mechanism. Since it is formulated using 11 natural plant ingredients, it is clinically proven to be safe and free of toxins, chemicals, or additives.
Glucofort Blood Sugar Support is an all-natural dietary formula that works to support healthy blood sugar levels. It also supports glucose metabolism. According to the manufacturer, this supplement can help users keep their blood sugar levels healthy and within a normal range with herbs, vitamins, plant extracts, and other natural ingredients.
TropiSlim is a unique dietary supplement designed to address specific health concerns, primarily focusing on weight management and related issues in women, particularly those over the age of 40.
The other day, while I was at work, my sister stole my apple ipad and tested to see if it can survive a thirty foot drop, just so she can be a youtube sensation. My apple ipad is now broken and she has 83 views. I know this is totally off topic but I had to share it with someone!
Nervogen Pro, A Cutting-Edge Supplement Dedicated To Enhancing Nerve Health And Providing Natural Relief From Discomfort. Our Mission Is To Empower You To Lead A Life Free From The Limitations Of Nerve-Related Challenges. With A Focus On Premium Ingredients And Scientific Expertise.
Claritox Pro™ is a natural dietary supplement that is formulated to support brain health and promote a healthy balance system to prevent dizziness, risk injuries, and disability. This formulation is made using naturally sourced and effective ingredients that are mixed in the right way and in the right amounts to deliver effective results.
InchaGrow is an advanced male enhancement supplement. Discover the natural way to boost your sexual health. Increase desire, improve erections, and experience more intense orgasms.
Hey there, I think your website might be having browser compatibility issues. When I look at your website in Firefox, it looks fine but when opening in Internet Explorer, it has some overlapping. I just wanted to give you a quick heads up! Other then that, awesome blog!
Wow! Thank you! I continually wanted to write on my website something like that. Can I implement a part of your post to my blog?
總統民調
民意調查
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
民意調查
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
It?¦s really a great and helpful piece of information. I am satisfied that you just shared this helpful information with us. Please stay us up to date like this. Thanks for sharing.
民調
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
VidaCalm is an all-natural blend of herbs and plant extracts that treat tinnitus and help you live a peaceful life.
LeanFlux is a natural supplement that claims to increase brown adipose tissue (BAT) levels and burn fat and calories.
Leanotox is one of the world’s most unique products designed to promote optimal weight and balance blood sugar levels while curbing your appetite,detoxifying and boosting metabolism.
Puralean is an all-natural dietary supplement designed to support boosted fat-burning rates, energy levels, and metabolism by targeting healthy liver function.
PowerBite is a natural tooth and gum support formula that will eliminate your dental problems, allowing you to live a healthy lifestyle.
DentaTonic™ is formulated to support lactoperoxidase levels in saliva, which is important for maintaining oral health. This enzyme is associated with defending teeth and gums from bacteria that could lead to dental issues.
Keratone is 100% natural formula, non invasive, and helps remove fungal build-up in your toe, improve circulation in capillaries so you can easily and effortlessly break free from toenail fungus.
LeanBliss™ is a natural weight loss supplement that has gained immense popularity due to its safe and innovative approach towards weight loss and support for healthy blood sugar.
An impressive share, I just given this onto a colleague who was doing a little analysis on this. And he in fact bought me breakfast because I found it for him.. smile. So let me reword that: Thnx for the treat! But yeah Thnkx for spending the time to discuss this, I feel strongly about it and love reading more on this topic. If possible, as you become expertise, would you mind updating your blog with more details? It is highly helpful for me. Big thumb up for this blog post!
Sugar Defender is the #1 rated blood sugar formula with an advanced blend of 24 proven ingredients that support healthy glucose levels and natural weight loss.
That is the precise blog for anybody who desires to search out out about this topic. You notice so much its almost arduous to argue with you (not that I really would want…HaHa). You definitely put a new spin on a topic thats been written about for years. Nice stuff, just great!
Fast Lean Pro is a natural dietary aid designed to boost weight loss. Fast Lean Pro powder supplement claims to harness the benefits of intermittent fasting, promoting cellular renewal and healthy metabolism.
This is my first time pay a quick visit at here and i am really happy to read everthing at one place
I¦ve recently started a website, the information you offer on this site has helped me greatly. Thank you for all of your time & work.
I have been surfing online greater than 3 hours lately, but
I never found any attention-grabbing article like yours.
It’s beautiful price enough for me. In my view, if all site owners and bloggers made just right content material as you did, the net will likely be much more helpful than ever
before.
Great weblog here! Additionally your web site a lot up very fast! What host are you the usage of? Can I am getting your affiliate hyperlink to your host? I desire my web site loaded up as fast as yours lol
Would you be all in favour of exchanging hyperlinks?
I like this website so much, saved to my bookmarks.
Howdy! This is kind of off topic but I need some help from an established blog. Is it very difficult to set up your own blog? I’m not very techincal but I can figure things out pretty fast. I’m thinking about making my own but I’m not sure where to begin. Do you have any points or suggestions? Appreciate it
I have been exploring for a little for any high quality articles or blog posts in this kind of space .
Exploring in Yahoo I ultimately stumbled upon this site.
Studying this information So i’m satisfied to express that I have an incredibly just right uncanny feeling I came upon exactly what I needed.
I most undoubtedly will make certain to do not forget this website and provides it a glance on a continuing basis.
Some genuinely prize blog posts on this website , bookmarked.
I think the admin of this web site is genuinely working hard in favor of his web site, because here every information is quality based data.
Hey there! Someone in my Facebook group shared this site with us so I came to take a look. I’m definitely loving the information. I’m bookmarking and will be tweeting this to my followers! Wonderful blog and terrific design.
You made some decent points there. I did a search on the subject matter and found most individuals will go along with with your site.
Hello! I could have sworn I’ve been to this blog before but after browsing through some of the post I realized it’s new to me. Anyways, I’m definitely happy I found it and I’ll be book-marking and checking back frequently!
I used to be suggested this web site by means of my cousin. I’m not positive whether this publish is written via him as nobody else recognise such
designated about my problem. You’re amazing! Thanks!
Nice post. I was checking continuously this blog and I’m impressed! Extremely useful info specially the last part 🙂 I care for such information much. I was looking for this particular information for a long time. Thank you and good luck.
I love your blog.. very nice colors & theme. Did you design this website yourself or did you hire someone to do it for you? Plz respond as I’m looking to create my own blog and would like to find out where u got this from. cheers
Hmm it appears like your blog ate my first comment (it was extremely long) so I guess I’ll just sum it up what I had written and say, I’m thoroughly enjoying your blog. I as well am an aspiring blog writer but I’m still new to the whole thing. Do you have any tips and hints for rookie blog writers? I’d really appreciate it.
Keep working ,great job!
Would love to incessantly get updated outstanding blog! .
Nice post. I learn something totally new and challenging on websites
Awesome! Its genuinely remarkable post, I have got much clear idea regarding from this post
It is really a great and helpful piece of information. I?¦m happy that you simply shared this helpful info with us. Please keep us up to date like this. Thank you for sharing.
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
BioVanish a weight management solution that’s transforming the approach to healthy living. In a world where weight loss often feels like an uphill battle, BioVanish offers a refreshing and effective alternative. This innovative supplement harnesses the power of natural ingredients to support optimal weight management. https://biovanishbuynow.us/
Sweet blog! I found it while searching on Yahoo News. Do you have any tips on how to get listed in Yahoo News? I’ve been trying for a while but I never seem to get there! Cheers
EyeFortin is an all-natural eye-health supplement that helps to keep your eyes healthy even as you age. It prevents infections and detoxifies your eyes while also being stimulant-free. This makes it a great choice for those who are looking for a natural way to improve their eye health. https://eyefortinbuynow.us/
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
Alpha Tonic is a powder-based supplement that uses multiple natural herbs and essential vitamins and minerals to helpoptimize your body’s natural testosterone levels. https://alphatonicbuynow.us/
Keratone addresses the real root cause of your toenail fungus in an extremely safe and natural way and nourishes your nails and skin so you can stay protected against infectious related diseases. https://keratonebuynow.us/
Reliver Pro is a dietary supplement formulated with a blend of natural ingredients aimed at supporting liver health
Sugar Defender is the #1 rated blood sugar formula with an advanced blend of 24 proven ingredients that support healthy glucose levels and natural weight loss. https://sugardefenderbuynow.us/
GlucoBerry is one of the biggest all-natural dietary and biggest scientific breakthrough formulas ever in the health industry today. This is all because of its amazing high-quality cutting-edge formula that helps treat high blood sugar levels very naturally and effectively. https://glucoberrybuynow.us/
TropiSlim is the world’s first 100% natural solution to support healthy weight loss by using a blend of carefully selected ingredients. https://tropislimbuynow.us/
PowerBite is an innovative dental candy that promotes healthy teeth and gums. It’s a powerful formula that supports a strong and vibrant smile. https://powerbitebuynow.us/
Neurodrine is a nootropic supplement that helps maintain memory and a healthy brain. It increases the brain’s sharpness, focus, memory, and concentration. https://neurodrinebuynow.us/
Erec Prime is a natural formula designed to boost your virility and improve your male enhancement abilities, helping you maintain long-lasting performance. This product is ideal for men facing challenges with maintaining strong erections and desiring to enhance both their size and overall health. https://erecprimebuynow.us/
BioFit is an all-natural supplement that is known to enhance and balance good bacteria in the gut area. To lose weight, you need to have a balanced hormones and body processes. Many times, people struggle with weight loss because their gut health has issues. https://biofitbuynow.us/
Researchers consider obesity a world crisis affecting over half a billion people worldwide. Vid Labs provides an effective solution that helps combat obesity and overweight without exercise or dieting. https://leanotoxbuynow.us/
Wild Stallion Pro, a natural male enhancement supplement, promises noticeable improvements in penis size and sexual performance within weeks. Crafted with a blend of carefully selected natural ingredients, it offers a holistic approach for a more satisfying and confident sexual experience. https://wildstallionprobuynow.us/
Good write-up, I’m regular visitor of one’s blog, maintain up the nice operate, and It is going to be a regular visitor for a long time.
Dentitox Pro is a liquid dietary solution created as a serum to support healthy gums and teeth. Dentitox Pro formula is made in the best natural way with unique, powerful botanical ingredients that can support healthy teeth. https://dentitoxbuynow.us/
Puralean incorporates blends of Mediterranean plant-based nutrients, specifically formulated to support healthy liver function. These blends aid in naturally detoxifying your body, promoting efficient fat burning and facilitating weight loss. https://puraleanbuynow.us/
LeanBliss is a unique weight loss formula that promotes optimal weight and balanced blood sugar levels while curbing your appetite, detoxifying, and boosting your metabolism. https://leanblissbuynow.us/
Absolutely composed content, thanks for selective information. “Necessity is the mother of taking chances.” by Mark Twain.
Illuderma is a serum designed to deeply nourish, clear, and hydrate the skin. The goal of this solution began with dark spots, which were previously thought to be a natural symptom of ageing. The creators of Illuderma were certain that blue modern radiation is the source of dark spots after conducting extensive research. https://illudermabuynow.us/
Metabo Flex is a nutritional formula that enhances metabolic flexibility by awakening the calorie-burning switch in the body. The supplement is designed to target the underlying causes of stubborn weight gain utilizing a special “miracle plant” from Cambodia that can melt fat 24/7. https://metaboflexbuynow.us/
Neotonics is an essential probiotic supplement that works to support the microbiome in the gut and also works as an anti-aging formula. The formula targets the cause of the aging of the skin. https://neotonicsbuynow.us/
FlowForce Max is an innovative, natural and effective way to address your prostate problems, while addressing your energy, libido, and vitality. https://flowforcemaxbuynow.us/
https://gutvitabuynow.us/
very good put up, i actually love this web site, keep on it
EndoPump is a dietary supplement for men’s health. This supplement is said to improve the strength and stamina required by your body to perform various physical tasks. Because the supplement addresses issues associated with aging, it also provides support for a variety of other age-related issues that may affect the body. https://endopumpbuynow.us/
ProstateFlux is a dietary supplement specifically designed to promote and maintain a healthy prostate. It is formulated with a blend of natural ingredients known for their potential benefits for prostate health. https://prostatefluxbuynow.us/
Quietum Plus supplement promotes healthy ears, enables clearer hearing, and combats tinnitus by utilizing only the purest natural ingredients. Supplements are widely used for various reasons, including boosting energy, lowering blood pressure, and boosting metabolism. https://quietumplusbuynow.us/
Red Boost is a male-specific natural dietary supplement. Nitric oxide is naturally increased by it, which enhances blood circulation all throughout the body. This may improve your general well-being. Red Boost is an excellent option if you’re trying to assist your circulatory system. https://redboostbuynow.us/
https://zoracelbuynow.us/
Glucofort Blood Sugar Support is an all-natural dietary formula that works to support healthy blood sugar levels. It also supports glucose metabolism. According to the manufacturer, this supplement can help users keep their blood sugar levels healthy and within a normal range with herbs, vitamins, plant extracts, and other natural ingredients. https://glucofortbuynow.us/
Java Burn is a proprietary blend of metabolism-boosting ingredients that work together to promote weight loss in your body. https://javaburnbuynow.us/
Cortexi is a completely natural product that promotes healthy hearing, improves memory, and sharpens mental clarity. Cortexi hearing support formula is a combination of high-quality natural components that work together to offer you with a variety of health advantages, particularly for persons in their middle and late years. https://cortexibuynow.us/
Serolean, a revolutionary weight loss supplement, zeroes in on serotonin—the key neurotransmitter governing mood, appetite, and fat storage. https://seroleanbuynow.us/
Endopeak is a natural energy-boosting formula designed to improve men’s stamina, energy levels, and overall health. The supplement is made up of eight high-quality ingredients that address the underlying cause of declining energy and vitality. https://endopeakbuynow.us/
Some truly excellent info , Gladiolus I noticed this.
LeanBiome is designed to support healthy weight loss. Formulated through the latest Ivy League research and backed by real-world results, it’s your partner on the path to a healthier you. https://leanbiomebuynow.us/
Unlock the incredible potential of Puravive! Supercharge your metabolism and incinerate calories like never before with our unique fusion of 8 exotic components. Bid farewell to those stubborn pounds and welcome a reinvigorated metabolism and boundless vitality. Grab your bottle today and seize this golden opportunity! https://puravivebuynow.us/
娛樂城
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
Kerassentials are natural skin care products with ingredients such as vitamins and plants that help support good health and prevent the appearance of aging skin. They’re also 100% natural and safe to use. The manufacturer states that the product has no negative side effects and is safe to take on a daily basis. Kerassentials is a convenient, easy-to-use formula. https://kerassentialsbuynow.us/
Neurozoom crafted in the United States, is a cognitive support formula designed to enhance memory retention and promote overall cognitive well-being. https://neurozoombuynow.us/
DentaTonic is a breakthrough solution that would ultimately free you from the pain and humiliation of tooth decay, bleeding gums, and bad breath. It protects your teeth and gums from decay, cavities, and pain. https://dentatonicbuynow.us/
Boostaro is a dietary supplement designed specifically for men who suffer from health issues. https://boostarobuynow.us/
Fast Lean Pro is a herbal supplement that tricks your brain into imagining that you’re fasting and helps you maintain a healthy weight no matter when or what you eat. It offers a novel approach to reducing fat accumulation and promoting long-term weight management. https://fastleanprobuynow.us/
long term car rental Dubai
Dubai, a city known for its opulence and modernity, demands a mode of transportation that reflects its grandeur. For those seeking a cost-effective and reliable long-term solution, Somonion Rent Car LLC emerges as the premier choice for monthly car rentals in Dubai. With a diverse fleet ranging from compact cars to premium vehicles, the company promises an unmatched blend of affordability, flexibility, and personalized service.
Favorable Rental Conditions:
Understanding the potential financial strain of long-term car rentals, Somonion Rent Car LLC aims to make your journey more economical. The company offers flexible rental terms coupled with exclusive discounts for loyal customers. This commitment to affordability extends beyond the rental cost, as additional services such as insurance, maintenance, and repair ensure your safety and peace of mind throughout the duration of your rental.
A Plethora of Options:
Somonion Rent Car LLC boasts an extensive selection of vehicles to cater to diverse preferences and budgets. Whether you’re in the market for a sleek sedan or a spacious crossover, the company has the perfect car to complement your needs. The transparency in pricing, coupled with the ease of booking through their online platform, makes Somonion Rent Car LLC a hassle-free solution for those embarking on a long-term adventure in Dubai.
Car Rental Services Tailored for You:
Somonion Rent Car LLC doesn’t just offer cars; it provides a comprehensive range of rental services tailored to suit various occasions. From daily and weekly rentals to airport transfers and business travel, the company ensures that your stay in Dubai is not only comfortable but also exudes prestige. The fleet includes popular models such as the Nissan Altima 2018, KIA Forte 2018, Hyundai Elantra 2018, and the Toyota Camry Sport Edition 2020, all available for monthly rentals at competitive rates.
Featured Deals and Specials:
Somonion Rent Car LLC constantly updates its offerings to provide customers with the best deals. Featured cars like the Hyundai Sonata 2018 and Hyundai Santa Fe 2018 add a touch of luxury to your rental experience, with daily rates starting as low as AED 100. The company’s commitment to affordable luxury is further emphasized by the online booking system, allowing customers to secure the best deals in real-time through their website or by contacting the experts via phone or WhatsApp.
Conclusion:
Whether you’re a tourist looking to explore Dubai at your pace or a business traveler in need of a reliable and prestigious mode of transportation, Somonion Rent Car LLC stands as the go-to choice for monthly car rentals in Dubai. Unlock the ultimate mobility experience with Somonion, where affordability meets excellence, ensuring your journey through Dubai is as seamless and luxurious as the city itself. Contact Somonion Rent Car LLC today and embark on a journey where every mile is a testament to comfort, style, and unmatched service.
Folixine is a enhancement that regrows hair from the follicles by nourishing the scalp. It helps in strengthening hairs from roots. https://folixinebuynow.us/
Nervogen Pro is an effective dietary supplement designed to help patients with neuropathic pain. When you combine exotic herbs, spices, and other organic substances, your immune system will be strengthened. https://nervogenprobuynow.us/
SynoGut is an all-natural dietary supplement that is designed to support the health of your digestive system, keeping you energized and active. https://synogutbuynow.us/
Are you tired of looking in the mirror and noticing saggy skin? Is saggy skin making you feel like you are trapped in a losing battle against aging? Do you still long for the days when your complexion radiated youth and confidence? https://refirmancebuynow.us/
ProDentim is a nutritional dental health supplement that is formulated to reverse serious dental issues and to help maintain good dental health. https://prodentimbuynow.us/
Dubai, a city of grandeur and innovation, demands a transportation solution that matches its dynamic pace. Whether you’re a business executive, a tourist exploring the city, or someone in need of a reliable vehicle temporarily, car rental services in Dubai offer a flexible and cost-effective solution. In this guide, we’ll explore the popular car rental options in Dubai, catering to diverse needs and preferences.
Airport Car Rental: One-Way Pickup and Drop-off Road Trip Rentals:
For those who need to meet an important delegation at the airport or have a flight to another city, airport car rentals provide a seamless solution. Avoid the hassle of relying on public transport and ensure you reach your destination on time. With one-way pickup and drop-off options, you can effortlessly navigate your road trip, making business meetings or conferences immediately upon arrival.
Business Car Rental Deals & Corporate Vehicle Rentals in Dubai:
Companies without their own fleet or those finding transport maintenance too expensive can benefit from business car rental deals. This option is particularly suitable for businesses where a vehicle is needed only occasionally. By opting for corporate vehicle rentals, companies can optimize their staff structure, freeing employees from non-core functions while ensuring reliable transportation when necessary.
Tourist Car Rentals with Insurance in Dubai:
Tourists visiting Dubai can enjoy the freedom of exploring the city at their own pace with car rentals that come with insurance. This option allows travelers to choose a vehicle that suits the particulars of their trip without the hassle of dealing with insurance policies. Renting a car not only saves money and time compared to expensive city taxis but also ensures a trouble-free travel experience.
Daily Car Hire Near Me:
Daily car rental services are a convenient and cost-effective alternative to taxis in Dubai. Whether it’s for a business meeting, everyday use, or a luxury experience, you can find a suitable vehicle for a day on platforms like Smarketdrive.com. The website provides a secure and quick way to rent a car from certified and verified car rental companies, ensuring guarantees and safety.
Weekly Auto Rental Deals:
For those looking for flexibility throughout the week, weekly car rentals in Dubai offer a competent, attentive, and professional service. Whether you need a vehicle for a few days or an entire week, choosing a car rental weekly is a convenient and profitable option. The certified and tested car rental companies listed on Smarketdrive.com ensure a reliable and comfortable experience.
Monthly Car Rentals in Dubai:
When your personal car is undergoing extended repairs, or if you’re a frequent visitor to Dubai, monthly car rentals (long-term car rentals) become the ideal solution. Residents, businessmen, and tourists can benefit from the extensive options available on Smarketdrive.com, ensuring mobility and convenience throughout their stay in Dubai.
FAQ about Renting a Car in Dubai:
To address common queries about renting a car in Dubai, our FAQ section provides valuable insights and information. From rental terms to insurance coverage, it serves as a comprehensive guide for those considering the convenience of car rentals in the bustling city.
Conclusion:
Dubai’s popularity as a global destination is matched by its diverse and convenient car rental services. Whether for business, tourism, or daily commuting, the options available cater to every need. With reliable platforms like Smarketdrive.com, navigating Dubai becomes a seamless and enjoyable experience, offering both locals and visitors the ultimate freedom of mobility.
Amiclear is a dietary supplement designed to support healthy blood sugar levels and assist with glucose metabolism. It contains eight proprietary blends of ingredients that have been clinically proven to be effective. https://amiclearbuynow.us/
GlucoTrust is a revolutionary blood sugar support solution that eliminates the underlying causes of type 2 diabetes and associated health risks. https://glucotrustbuynow.us/
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
Dubai, a city known for its opulence and modernity, demands a mode of transportation that reflects its grandeur. For those seeking a cost-effective and reliable long-term solution, Somonion Rent Car LLC emerges as the premier choice for monthly car rentals in Dubai. With a diverse fleet ranging from compact cars to premium vehicles, the company promises an unmatched blend of affordability, flexibility, and personalized service.
Favorable Rental Conditions:
Understanding the potential financial strain of long-term car rentals, Somonion Rent Car LLC aims to make your journey more economical. The company offers flexible rental terms coupled with exclusive discounts for loyal customers. This commitment to affordability extends beyond the rental cost, as additional services such as insurance, maintenance, and repair ensure your safety and peace of mind throughout the duration of your rental.
A Plethora of Options:
Somonion Rent Car LLC boasts an extensive selection of vehicles to cater to diverse preferences and budgets. Whether you’re in the market for a sleek sedan or a spacious crossover, the company has the perfect car to complement your needs. The transparency in pricing, coupled with the ease of booking through their online platform, makes Somonion Rent Car LLC a hassle-free solution for those embarking on a long-term adventure in Dubai.
Car Rental Services Tailored for You:
Somonion Rent Car LLC doesn’t just offer cars; it provides a comprehensive range of rental services tailored to suit various occasions. From daily and weekly rentals to airport transfers and business travel, the company ensures that your stay in Dubai is not only comfortable but also exudes prestige. The fleet includes popular models such as the Nissan Altima 2018, KIA Forte 2018, Hyundai Elantra 2018, and the Toyota Camry Sport Edition 2020, all available for monthly rentals at competitive rates.
Featured Deals and Specials:
Somonion Rent Car LLC constantly updates its offerings to provide customers with the best deals. Featured cars like the Hyundai Sonata 2018 and Hyundai Santa Fe 2018 add a touch of luxury to your rental experience, with daily rates starting as low as AED 100. The company’s commitment to affordable luxury is further emphasized by the online booking system, allowing customers to secure the best deals in real-time through their website or by contacting the experts via phone or WhatsApp.
Conclusion:
Whether you’re a tourist looking to explore Dubai at your pace or a business traveler in need of a reliable and prestigious mode of transportation, Somonion Rent Car LLC stands as the go-to choice for monthly car rentals in Dubai. Unlock the ultimate mobility experience with Somonion, where affordability meets excellence, ensuring your journey through Dubai is as seamless and luxurious as the city itself. Contact Somonion Rent Car LLC today and embark on a journey where every mile is a testament to comfort, style, and unmatched service.
I really like your blog.. very nice colors & theme. Did you create this website yourself or did you hire someone to do it
for you? Plz respond as I’m looking to design my own blog
and would like to know where u got this from. appreciate it
Hello there, I discovered your blog by means of Google while searching for a comparable matter, your website came up, it looks good. I’ve bookmarked it in my google bookmarks.
you are really a good webmaster. The site loading speed is amazing. It seems that you’re doing any unique trick. Also, The contents are masterpiece. you’ve done a magnificent job on this topic!
I do not even know how I ended up here, but I thought this post was great. I don’t know who you are but definitely you’re going to a famous blogger if you aren’t already Cheers!
Dubai, a city known for its opulence and modernity, demands a mode of transportation that reflects its grandeur. For those seeking a cost-effective and reliable long-term solution, Somonion Rent Car LLC emerges as the premier choice for monthly car rentals in Dubai. With a diverse fleet ranging from compact cars to premium vehicles, the company promises an unmatched blend of affordability, flexibility, and personalized service.
Favorable Rental Conditions:
Understanding the potential financial strain of long-term car rentals, Somonion Rent Car LLC aims to make your journey more economical. The company offers flexible rental terms coupled with exclusive discounts for loyal customers. This commitment to affordability extends beyond the rental cost, as additional services such as insurance, maintenance, and repair ensure your safety and peace of mind throughout the duration of your rental.
A Plethora of Options:
Somonion Rent Car LLC boasts an extensive selection of vehicles to cater to diverse preferences and budgets. Whether you’re in the market for a sleek sedan or a spacious crossover, the company has the perfect car to complement your needs. The transparency in pricing, coupled with the ease of booking through their online platform, makes Somonion Rent Car LLC a hassle-free solution for those embarking on a long-term adventure in Dubai.
Car Rental Services Tailored for You:
Somonion Rent Car LLC doesn’t just offer cars; it provides a comprehensive range of rental services tailored to suit various occasions. From daily and weekly rentals to airport transfers and business travel, the company ensures that your stay in Dubai is not only comfortable but also exudes prestige. The fleet includes popular models such as the Nissan Altima 2018, KIA Forte 2018, Hyundai Elantra 2018, and the Toyota Camry Sport Edition 2020, all available for monthly rentals at competitive rates.
Featured Deals and Specials:
Somonion Rent Car LLC constantly updates its offerings to provide customers with the best deals. Featured cars like the Hyundai Sonata 2018 and Hyundai Santa Fe 2018 add a touch of luxury to your rental experience, with daily rates starting as low as AED 100. The company’s commitment to affordable luxury is further emphasized by the online booking system, allowing customers to secure the best deals in real-time through their website or by contacting the experts via phone or WhatsApp.
Conclusion:
Whether you’re a tourist looking to explore Dubai at your pace or a business traveler in need of a reliable and prestigious mode of transportation, Somonion Rent Car LLC stands as the go-to choice for monthly car rentals in Dubai. Unlock the ultimate mobility experience with Somonion, where affordability meets excellence, ensuring your journey through Dubai is as seamless and luxurious as the city itself. Contact Somonion Rent Car LLC today and embark on a journey where every mile is a testament to comfort, style, and unmatched service.
Thanks for every other informative website. The place else could I get that type of info written in such an ideal way? I’ve a venture that I’m just now operating on, and I’ve been at the look out for such info.
When I originally commented I clicked the -Notify me when new comments are added- checkbox and now each time a comment is added I get four emails with the same comment. Is there any way you can remove me from that service? Thanks!
Watches World
Watches World: Elevating Luxury and Style with Exquisite Timepieces
Introduction:
Jewelry has always been a timeless expression of elegance, and nothing complements one’s style better than a luxurious timepiece. At Watches World, we bring you an exclusive collection of coveted luxury watches that not only tell time but also serve as a testament to your refined taste. Explore our curated selection featuring iconic brands like Rolex, Hublot, Omega, Cartier, and more, as we redefine the art of accessorizing.
A Dazzling Array of Luxury Watches:
Watches World offers an unparalleled range of exquisite timepieces from renowned brands, ensuring that you find the perfect accessory to elevate your style. Whether you’re drawn to the classic sophistication of Rolex, the avant-garde designs of Hublot, or the precision engineering of Patek Philippe, our collection caters to diverse preferences.
Customer Testimonials:
Our commitment to providing an exceptional customer experience is reflected in the reviews from our satisfied clientele. O.M. commends our excellent communication and flawless packaging, while Richard Houtman appreciates the helpfulness and courtesy of our team. These testimonials highlight our dedication to transparency, communication, and customer satisfaction.
New Arrivals:
Stay ahead of the curve with our latest additions, including the Tudor Black Bay Ceramic 41mm, Richard Mille RM35-01 Rafael Nadal NTPT Carbon Limited Edition, and the Rolex Oyster Perpetual Datejust 41mm series. These new arrivals showcase cutting-edge designs and impeccable craftsmanship, ensuring you stay on the forefront of luxury watch fashion.
Best Sellers:
Discover our best-selling watches, such as the Bulgari Serpenti Tubogas 35mm and the Cartier Panthere Medium Model. These timeless pieces combine elegance with precision, making them a staple in any sophisticated wardrobe.
Expert’s Selection:
Our experts have carefully curated a selection of watches, including the Cartier Panthere Small Model, Omega Speedmaster Moonwatch 44.25 mm, and Rolex Oyster Perpetual Cosmograph Daytona 40mm. These choices exemplify the epitome of watchmaking excellence and style.
Secured and Tracked Delivery:
At Watches World, we prioritize the safety of your purchase. Our secured and tracked delivery ensures that your exquisite timepiece reaches you in perfect condition, giving you peace of mind with every order.
Passionate Experts at Your Service:
Our team of passionate watch experts is dedicated to providing personalized service. From assisting you in choosing the perfect timepiece to addressing any inquiries, we are here to make your watch-buying experience seamless and enjoyable.
Global Presence:
With a presence in key cities around the world, including Dubai, Geneva, Hong Kong, London, Miami, Paris, Prague, Dublin, Singapore, and Sao Paulo, Watches World brings luxury timepieces to enthusiasts globally.
Conclusion:
Watches World goes beyond being an online platform for luxury watches; it is a destination where expertise, trust, and satisfaction converge. Explore our collection, and let our timeless timepieces become an integral part of your style narrative. Join us in redefining luxury, one exquisite watch at a time.
Luxury car rental dubai
Dubai, a city of grandeur and innovation, demands a transportation solution that matches its dynamic pace. Whether you’re a business executive, a tourist exploring the city, or someone in need of a reliable vehicle temporarily, car rental services in Dubai offer a flexible and cost-effective solution. In this guide, we’ll explore the popular car rental options in Dubai, catering to diverse needs and preferences.
Airport Car Rental: One-Way Pickup and Drop-off Road Trip Rentals:
For those who need to meet an important delegation at the airport or have a flight to another city, airport car rentals provide a seamless solution. Avoid the hassle of relying on public transport and ensure you reach your destination on time. With one-way pickup and drop-off options, you can effortlessly navigate your road trip, making business meetings or conferences immediately upon arrival.
Business Car Rental Deals & Corporate Vehicle Rentals in Dubai:
Companies without their own fleet or those finding transport maintenance too expensive can benefit from business car rental deals. This option is particularly suitable for businesses where a vehicle is needed only occasionally. By opting for corporate vehicle rentals, companies can optimize their staff structure, freeing employees from non-core functions while ensuring reliable transportation when necessary.
Tourist Car Rentals with Insurance in Dubai:
Tourists visiting Dubai can enjoy the freedom of exploring the city at their own pace with car rentals that come with insurance. This option allows travelers to choose a vehicle that suits the particulars of their trip without the hassle of dealing with insurance policies. Renting a car not only saves money and time compared to expensive city taxis but also ensures a trouble-free travel experience.
Daily Car Hire Near Me:
Daily car rental services are a convenient and cost-effective alternative to taxis in Dubai. Whether it’s for a business meeting, everyday use, or a luxury experience, you can find a suitable vehicle for a day on platforms like Smarketdrive.com. The website provides a secure and quick way to rent a car from certified and verified car rental companies, ensuring guarantees and safety.
Weekly Auto Rental Deals:
For those looking for flexibility throughout the week, weekly car rentals in Dubai offer a competent, attentive, and professional service. Whether you need a vehicle for a few days or an entire week, choosing a car rental weekly is a convenient and profitable option. The certified and tested car rental companies listed on Smarketdrive.com ensure a reliable and comfortable experience.
Monthly Car Rentals in Dubai:
When your personal car is undergoing extended repairs, or if you’re a frequent visitor to Dubai, monthly car rentals (long-term car rentals) become the ideal solution. Residents, businessmen, and tourists can benefit from the extensive options available on Smarketdrive.com, ensuring mobility and convenience throughout their stay in Dubai.
FAQ about Renting a Car in Dubai:
To address common queries about renting a car in Dubai, our FAQ section provides valuable insights and information. From rental terms to insurance coverage, it serves as a comprehensive guide for those considering the convenience of car rentals in the bustling city.
Conclusion:
Dubai’s popularity as a global destination is matched by its diverse and convenient car rental services. Whether for business, tourism, or daily commuting, the options available cater to every need. With reliable platforms like Smarketdrive.com, navigating Dubai becomes a seamless and enjoyable experience, offering both locals and visitors the ultimate freedom of mobility.
Dubai, a city known for its opulence and modernity, demands a mode of transportation that reflects its grandeur. For those seeking a cost-effective and reliable long-term solution, Somonion Rent Car LLC emerges as the premier choice for monthly car rentals in Dubai. With a diverse fleet ranging from compact cars to premium vehicles, the company promises an unmatched blend of affordability, flexibility, and personalized service.
Favorable Rental Conditions:
Understanding the potential financial strain of long-term car rentals, Somonion Rent Car LLC aims to make your journey more economical. The company offers flexible rental terms coupled with exclusive discounts for loyal customers. This commitment to affordability extends beyond the rental cost, as additional services such as insurance, maintenance, and repair ensure your safety and peace of mind throughout the duration of your rental.
A Plethora of Options:
Somonion Rent Car LLC boasts an extensive selection of vehicles to cater to diverse preferences and budgets. Whether you’re in the market for a sleek sedan or a spacious crossover, the company has the perfect car to complement your needs. The transparency in pricing, coupled with the ease of booking through their online platform, makes Somonion Rent Car LLC a hassle-free solution for those embarking on a long-term adventure in Dubai.
Car Rental Services Tailored for You:
Somonion Rent Car LLC doesn’t just offer cars; it provides a comprehensive range of rental services tailored to suit various occasions. From daily and weekly rentals to airport transfers and business travel, the company ensures that your stay in Dubai is not only comfortable but also exudes prestige. The fleet includes popular models such as the Nissan Altima 2018, KIA Forte 2018, Hyundai Elantra 2018, and the Toyota Camry Sport Edition 2020, all available for monthly rentals at competitive rates.
Featured Deals and Specials:
Somonion Rent Car LLC constantly updates its offerings to provide customers with the best deals. Featured cars like the Hyundai Sonata 2018 and Hyundai Santa Fe 2018 add a touch of luxury to your rental experience, with daily rates starting as low as AED 100. The company’s commitment to affordable luxury is further emphasized by the online booking system, allowing customers to secure the best deals in real-time through their website or by contacting the experts via phone or WhatsApp.
Conclusion:
Whether you’re a tourist looking to explore Dubai at your pace or a business traveler in need of a reliable and prestigious mode of transportation, Somonion Rent Car LLC stands as the go-to choice for monthly car rentals in Dubai. Unlock the ultimate mobility experience with Somonion, where affordability meets excellence, ensuring your journey through Dubai is as seamless and luxurious as the city itself. Contact Somonion Rent Car LLC today and embark on a journey where every mile is a testament to comfort, style, and unmatched service.
Your means of telling all in this article is truly good, every one be capable of easily be aware of it,
Thanks a lot.
I genuinely enjoy looking through on this site, it contains great articles.
View the latest from the world of psychology: from behavioral research to practical guidance on relationships, mental health and addiction. Find help from our directory of therapists, psychologists and counselors. https://therapisttoday.us/
Virginia News: Your source for Virginia breaking news, sports, business, entertainment, weather and traffic https://virginiapost.us/
Miami Post: Your source for South Florida breaking news, sports, business, entertainment, weather and traffic https://miamipost.us/
The best tips, guides, and inspiration on home improvement, decor, DIY projects, and interviews with celebrities from your favorite renovation shows. https://houseblog.us/
RVVR is website dedicated to advancing physical and mental health through scientific research and proven interventions. Learn about our evidence-based health promotion programs. https://rvvr.us/
Find healthy, delicious recipes and meal plan ideas from our test kitchen cooks and nutrition experts at SweetApple. Learn how to make healthier food choices every day. https://sweetapple.site/
Breaking US news, local New York news coverage, sports, entertainment news, celebrity gossip, autos, videos and photos at nybreakingnews.us https://nybreakingnews.us/
Covering the latest beauty and fashion trends, relationship advice, wellness tips and more. https://gliz.us/
The latest news on grocery chains, celebrity chefs, and fast food – plus reviews, cooking tips and advice, recipes, and more. https://megamenu.us/
Colorado breaking news, sports, business, weather, entertainment. https://denver-news.us/
OCNews.us covers local news in Orange County, CA, California and national news, sports, things to do and the best places to eat, business and the Orange County housing market. https://ocnews.us/
Fresh, flavorful and (mostly) healthy recipes made for real, actual, every day life. Helping you celebrate the joy of food in a totally non-intimidating way. https://skillfulcook.us/
Island Post is the website for a chain of six weekly newspapers that serve the North Shore of Nassau County, Long Island published by Alb Media. The newspapers are comprised of the Great Neck News, Manhasset Times, Roslyn Times, Port Washington Times, New Hyde Park Herald Courier and the Williston Times. Their coverage includes village governments, the towns of Hempstead and North Hempstead, schools, business, entertainment and lifestyle. https://islandpost.us/
Looking for quick and easy dinner ideas? Browse 100
I truly appreciate your technique of writing a blog. I added it to my bookmark site list and will
Healthcare Blog provides news, trends, jobs and resources for health industry professionals. We cover topics like healthcare IT, hospital administration, polcy
Latest Denver news, top Colorado news and local breaking news from Denver News, including sports, weather, traffic, business, politics, photos and video. https://denver-news.us/
I have been absent for a while, but now I remember why I used to love this web site. Thanks, I will try and check back more often. How frequently you update your website?
Pretty component of content. I just stumbled upon your blog and in accession capital to say that I acquire in fact loved account your weblog posts. Any way I’ll be subscribing in your augment or even I fulfillment you get right of entry to consistently fast.
Real superb visual appeal on this web site, I’d rate it 10 10.
Santa Cruz Sentinel: Local News, Local Sports and more for Santa Cruz https://santacruznews.us/
Watches World: Elevating Luxury and Style with Exquisite Timepieces
Introduction:
Jewelry has always been a timeless expression of elegance, and nothing complements one’s style better than a luxurious timepiece. At Watches World, we bring you an exclusive collection of coveted luxury watches that not only tell time but also serve as a testament to your refined taste. Explore our curated selection featuring iconic brands like Rolex, Hublot, Omega, Cartier, and more, as we redefine the art of accessorizing.
A Dazzling Array of Luxury Watches:
Watches World offers an unparalleled range of exquisite timepieces from renowned brands, ensuring that you find the perfect accessory to elevate your style. Whether you’re drawn to the classic sophistication of Rolex, the avant-garde designs of Hublot, or the precision engineering of Patek Philippe, our collection caters to diverse preferences.
Customer Testimonials:
Our commitment to providing an exceptional customer experience is reflected in the reviews from our satisfied clientele. O.M. commends our excellent communication and flawless packaging, while Richard Houtman appreciates the helpfulness and courtesy of our team. These testimonials highlight our dedication to transparency, communication, and customer satisfaction.
New Arrivals:
Stay ahead of the curve with our latest additions, including the Tudor Black Bay Ceramic 41mm, Richard Mille RM35-01 Rafael Nadal NTPT Carbon Limited Edition, and the Rolex Oyster Perpetual Datejust 41mm series. These new arrivals showcase cutting-edge designs and impeccable craftsmanship, ensuring you stay on the forefront of luxury watch fashion.
Best Sellers:
Discover our best-selling watches, such as the Bulgari Serpenti Tubogas 35mm and the Cartier Panthere Medium Model. These timeless pieces combine elegance with precision, making them a staple in any sophisticated wardrobe.
Expert’s Selection:
Our experts have carefully curated a selection of watches, including the Cartier Panthere Small Model, Omega Speedmaster Moonwatch 44.25 mm, and Rolex Oyster Perpetual Cosmograph Daytona 40mm. These choices exemplify the epitome of watchmaking excellence and style.
Secured and Tracked Delivery:
At Watches World, we prioritize the safety of your purchase. Our secured and tracked delivery ensures that your exquisite timepiece reaches you in perfect condition, giving you peace of mind with every order.
Passionate Experts at Your Service:
Our team of passionate watch experts is dedicated to providing personalized service. From assisting you in choosing the perfect timepiece to addressing any inquiries, we are here to make your watch-buying experience seamless and enjoyable.
Global Presence:
With a presence in key cities around the world, including Dubai, Geneva, Hong Kong, London, Miami, Paris, Prague, Dublin, Singapore, and Sao Paulo, Watches World brings luxury timepieces to enthusiasts globally.
Conclusion:
Watches World goes beyond being an online platform for luxury watches; it is a destination where expertise, trust, and satisfaction converge. Explore our collection, and let our timeless timepieces become an integral part of your style narrative. Join us in redefining luxury, one exquisite watch at a time.
I’m also commenting to make you know of the nice experience our child experienced studying your web site. She came to find some things, which included how it is like to possess a wonderful helping style to make most people just have an understanding of certain specialized matters. You truly surpassed our expected results. Many thanks for churning out such interesting, trusted, informative and also easy tips on the topic to Sandra.
I consider something really special in this internet site.
Great post, you have pointed out some good details , I also conceive this s a very wonderful website.
East Bay News is the leading source of breaking news, local news, sports, entertainment, lifestyle and opinion for Contra Costa County, Alameda County, Oakland and beyond https://eastbaynews.us/
News from the staff of the LA Reporter, including crime and investigative coverage of the South Bay and Harbor Area in Los Angeles County. https://lareporter.us/
I’m extremely pleased to discover this website. I wanted to thank you for ones time just for this fantastic read!
My website: секс ру
Do whatever you want. Steal cars, drive tanks and helicopters, defeat gangs. It’s your city! https://play.google.com/store/apps/details?id=com.gangster.city.open.world
Respect to post author, some fantastic information
My website: русское реальное порно пьяных баб смотреть
What’s up mates, nice post and fastidious arguments commented here,
I am actually enjoying by these.
It’s really a nice and useful piece of info. I’m glad that you shared this useful info with us. Please keep us informed like this. Thanks for sharing.
The latest film and TV news, movie trailers, exclusive interviews, reviews, as well as informed opinions on everything Hollywood has to offer. https://xoop.us/
Thank you for your whole effort on this blog. My mum loves engaging in investigation and it is obvious why. Almost all hear all regarding the dynamic mode you present both interesting and useful steps by means of your blog and as well as recommend response from visitors on this subject matter and our favorite princess is without a doubt being taught a great deal. Take pleasure in the rest of the year. You are carrying out a very good job.
ATG戰神賽特
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
戰神賽特試玩推薦
看完了❰戰神賽特老虎機❱介紹之後,玩家們是否也蓄勢待發要進入古埃及的世界,一探神奇秘寶探險之旅。
本次ATG賽特與線上娛樂城推薦第一名的富遊娛樂城合作,只需要加入會員,即可領取到168體驗金,免費試玩420轉!
2024娛樂城No.1 – 富遊娛樂城介紹
2024 年 1 月 5 日
|
娛樂城, 現金版娛樂城
富遊娛樂城是無論老手、新手,都非常推薦的線上博奕,在2024娛樂城當中扮演著多年來最來勢洶洶的一匹黑馬,『人性化且精緻的介面,遊戲種類眾多,超級多的娛樂城優惠,擁有眾多與會員交流遊戲的群組』是一大特色。
富遊娛樂城擁有歐洲馬爾他(MGA)和菲律賓政府競猜委員會(PAGCOR)頒發的合法執照。
註冊於英屬維爾京群島,受國際行業協會認可的合法公司。
我們的中心思想就是能夠帶領玩家遠詐騙黑網,讓大家安心放心的暢玩線上博弈,娛樂城也受各大部落客、IG網紅、PTT論壇,推薦討論,富遊娛樂城沒有之一,絕對是線上賭場玩家的第一首選!
富遊娛樂城介面 / 2024娛樂城NO.1
富遊娛樂城簡介
品牌名稱 : 富遊RG
創立時間 : 2019年
存款速度 : 平均15秒
提款速度 : 平均5分
單筆提款金額 : 最低1000-100萬
遊戲對象 : 18歲以上男女老少皆可
合作廠商 : 22家遊戲平台商
支付平台 : 各大銀行、各大便利超商
支援配備 : 手機網頁、電腦網頁、IOS、安卓(Android)
富遊娛樂城遊戲品牌
真人百家 — 歐博真人、DG真人、亞博真人、SA真人、OG真人
體育投注 — SUPER體育、鑫寶體育、亞博體育
電競遊戲 — 泛亞電競
彩票遊戲 — 富遊彩票、WIN 539
電子遊戲 —ZG電子、BNG電子、BWIN電子、RSG電子、好路GR電子
棋牌遊戲 —ZG棋牌、亞博棋牌、好路棋牌、博亞棋牌
捕魚遊戲 —ZG捕魚、RSG捕魚、好路GR捕魚、亞博捕魚
富遊娛樂城優惠活動
每日任務簽到金666
富遊VIP全面啟動
復酬金活動10%優惠
日日返水
新會員好禮五選一
首存禮1000送1000
免費體驗金$168
富遊娛樂城APP
步驟1 : 開啟網頁版【富遊娛樂城官網】
步驟2 : 點選上方(下載app),會跳出下載與複製連結選項,點選後跳轉。
步驟3 : 跳轉後點選(安裝),並點選(允許)操作下載描述檔,跳出下載描述檔後點選關閉。
步驟4 : 到手機設置>一般>裝置管理>設定描述檔(富遊)安裝,即可完成安裝。
富遊娛樂城常見問題FAQ
富遊娛樂城詐騙?
黑網詐騙可細分兩種,小出大不出及純詐騙黑網,我們可從品牌知名度經營和網站架設畫面分辨來簡單分辨。
富遊娛樂城會出金嗎?
如上面提到,富遊是在做一個品牌,為的是能夠保證出金,和帶領玩家遠離黑網,而且還有DUKER娛樂城出金認證,所以各位能夠放心富遊娛樂城為正出金娛樂城。
富遊娛樂城出金延遲怎麼辦?
基本上只要是公司系統問提造成富遊娛樂城會員無法在30分鐘成功提款,富遊娛樂城會即刻派送補償金,表達誠摯的歉意。
富遊娛樂城結論
富遊娛樂城安心玩,評價4.5顆星。如果還想看其他娛樂城推薦的,可以來娛樂城推薦尋找喔。
https://rg88.org/seth/
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
戰神賽特試玩推薦
看完了❰戰神賽特老虎機❱介紹之後,玩家們是否也蓄勢待發要進入古埃及的世界,一探神奇秘寶探險之旅。
本次ATG賽特與線上娛樂城推薦第一名的富遊娛樂城合作,只需要加入會員,即可領取到168體驗金,免費試玩420轉!
http://indianpharmacy.shop/# india online pharmacy
top 10 online pharmacy in india
indiaherald.us provides latest news from India , India News and around the world. Get breaking news alerts from India and follow today’s live news updates in field of politics, business, sports, defence, entertainment and more. https://indiaherald.us
When I initially commented I clicked the -Notify me when new comments are added- checkbox and now each time a remark is added I get 4 emails with the identical comment. Is there any approach you’ll be able to remove me from that service? Thanks!
http://indianpharmacy.shop/# best online pharmacy india indianpharmacy.shop
https://indianpharmacy.shop/# buy medicines online in india indianpharmacy.shop
reputable indian pharmacies
medicine in mexico pharmacies: Mexico pharmacy – mexican pharmaceuticals online
Pretty! This has been a really wonderful post. Many thanks for providing these details.
http://canadianpharmacy.pro/# my canadian pharmacy canadianpharmacy.pro
reputable indian pharmacies
https://mexicanpharmacy.win/# best mexican online pharmacies mexicanpharmacy.win
Kingston News – Kingston, NY News, Breaking News, Sports, Weather https://kingstonnews.us/
Stri is the leading entrepreneurs and innovation magazine devoted to shed light on the booming stri ecosystem worldwide. https://stri.us/
Yolonews.us covers local news in Yolo County, California. Keep up with all business, local sports, outdoors, local columnists and more. https://yolonews.us/
The one-stop destination for vacation guides, travel tips, and planning advice – all from local experts and tourism specialists. https://travelerblog.us/
Outdoor Blog will help you live your best life outside – from wildlife guides, to safety information, gardening tips, and more. https://outdoorblog.us/
Baltimore Post: Your source for Baltimore breaking news, sports, business, entertainment, weather and traffic https://baltimorepost.us/
http://indianpharmacy.shop/# indian pharmacy paypal indianpharmacy.shop
buy prescription drugs from india
The latest health news, wellness advice, and exclusives backed by trusted medical authorities. https://healthmap.us/
https://indianpharmacy.shop/# online pharmacy india indianpharmacy.shop
Money Analysis is the destination for balancing life and budget – from money management tips, to cost-cutting deals, tax advice, and much more. https://moneyanalysis.us/
Thanks , I have just been looking for info about this topic for ages and yours is the best I’ve discovered till now. But, what about the bottom line? Are you sure about the source?
pharmacies in mexico that ship to usa mexican pharmacy online mexican border pharmacies shipping to usa mexicanpharmacy.win
2024娛樂城
2024娛樂城No.1 – 富遊娛樂城介紹
2024 年 1 月 5 日
|
娛樂城, 現金版娛樂城
富遊娛樂城是無論老手、新手,都非常推薦的線上博奕,在2024娛樂城當中扮演著多年來最來勢洶洶的一匹黑馬,『人性化且精緻的介面,遊戲種類眾多,超級多的娛樂城優惠,擁有眾多與會員交流遊戲的群組』是一大特色。
富遊娛樂城擁有歐洲馬爾他(MGA)和菲律賓政府競猜委員會(PAGCOR)頒發的合法執照。
註冊於英屬維爾京群島,受國際行業協會認可的合法公司。
我們的中心思想就是能夠帶領玩家遠詐騙黑網,讓大家安心放心的暢玩線上博弈,娛樂城也受各大部落客、IG網紅、PTT論壇,推薦討論,富遊娛樂城沒有之一,絕對是線上賭場玩家的第一首選!
富遊娛樂城介面 / 2024娛樂城NO.1
富遊娛樂城簡介
品牌名稱 : 富遊RG
創立時間 : 2019年
存款速度 : 平均15秒
提款速度 : 平均5分
單筆提款金額 : 最低1000-100萬
遊戲對象 : 18歲以上男女老少皆可
合作廠商 : 22家遊戲平台商
支付平台 : 各大銀行、各大便利超商
支援配備 : 手機網頁、電腦網頁、IOS、安卓(Android)
富遊娛樂城遊戲品牌
真人百家 — 歐博真人、DG真人、亞博真人、SA真人、OG真人
體育投注 — SUPER體育、鑫寶體育、亞博體育
電競遊戲 — 泛亞電競
彩票遊戲 — 富遊彩票、WIN 539
電子遊戲 —ZG電子、BNG電子、BWIN電子、RSG電子、好路GR電子
棋牌遊戲 —ZG棋牌、亞博棋牌、好路棋牌、博亞棋牌
捕魚遊戲 —ZG捕魚、RSG捕魚、好路GR捕魚、亞博捕魚
富遊娛樂城優惠活動
每日任務簽到金666
富遊VIP全面啟動
復酬金活動10%優惠
日日返水
新會員好禮五選一
首存禮1000送1000
免費體驗金$168
富遊娛樂城APP
步驟1 : 開啟網頁版【富遊娛樂城官網】
步驟2 : 點選上方(下載app),會跳出下載與複製連結選項,點選後跳轉。
步驟3 : 跳轉後點選(安裝),並點選(允許)操作下載描述檔,跳出下載描述檔後點選關閉。
步驟4 : 到手機設置>一般>裝置管理>設定描述檔(富遊)安裝,即可完成安裝。
富遊娛樂城常見問題FAQ
富遊娛樂城詐騙?
黑網詐騙可細分兩種,小出大不出及純詐騙黑網,我們可從品牌知名度經營和網站架設畫面分辨來簡單分辨。
富遊娛樂城會出金嗎?
如上面提到,富遊是在做一個品牌,為的是能夠保證出金,和帶領玩家遠離黑網,而且還有DUKER娛樂城出金認證,所以各位能夠放心富遊娛樂城為正出金娛樂城。
富遊娛樂城出金延遲怎麼辦?
基本上只要是公司系統問提造成富遊娛樂城會員無法在30分鐘成功提款,富遊娛樂城會即刻派送補償金,表達誠摯的歉意。
富遊娛樂城結論
富遊娛樂城安心玩,評價4.5顆星。如果還想看其他娛樂城推薦的,可以來娛樂城推薦尋找喔。
戰神賽特
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
戰神賽特試玩推薦
看完了❰戰神賽特老虎機❱介紹之後,玩家們是否也蓄勢待發要進入古埃及的世界,一探神奇秘寶探險之旅。
本次ATG賽特與線上娛樂城推薦第一名的富遊娛樂城合作,只需要加入會員,即可領取到168體驗金,免費試玩420轉!
2024娛樂城
2024娛樂城No.1 – 富遊娛樂城介紹
2024 年 1 月 5 日
|
娛樂城, 現金版娛樂城
富遊娛樂城是無論老手、新手,都非常推薦的線上博奕,在2024娛樂城當中扮演著多年來最來勢洶洶的一匹黑馬,『人性化且精緻的介面,遊戲種類眾多,超級多的娛樂城優惠,擁有眾多與會員交流遊戲的群組』是一大特色。
富遊娛樂城擁有歐洲馬爾他(MGA)和菲律賓政府競猜委員會(PAGCOR)頒發的合法執照。
註冊於英屬維爾京群島,受國際行業協會認可的合法公司。
我們的中心思想就是能夠帶領玩家遠詐騙黑網,讓大家安心放心的暢玩線上博弈,娛樂城也受各大部落客、IG網紅、PTT論壇,推薦討論,富遊娛樂城沒有之一,絕對是線上賭場玩家的第一首選!
富遊娛樂城介面 / 2024娛樂城NO.1
富遊娛樂城簡介
品牌名稱 : 富遊RG
創立時間 : 2019年
存款速度 : 平均15秒
提款速度 : 平均5分
單筆提款金額 : 最低1000-100萬
遊戲對象 : 18歲以上男女老少皆可
合作廠商 : 22家遊戲平台商
支付平台 : 各大銀行、各大便利超商
支援配備 : 手機網頁、電腦網頁、IOS、安卓(Android)
富遊娛樂城遊戲品牌
真人百家 — 歐博真人、DG真人、亞博真人、SA真人、OG真人
體育投注 — SUPER體育、鑫寶體育、亞博體育
電競遊戲 — 泛亞電競
彩票遊戲 — 富遊彩票、WIN 539
電子遊戲 —ZG電子、BNG電子、BWIN電子、RSG電子、好路GR電子
棋牌遊戲 —ZG棋牌、亞博棋牌、好路棋牌、博亞棋牌
捕魚遊戲 —ZG捕魚、RSG捕魚、好路GR捕魚、亞博捕魚
富遊娛樂城優惠活動
每日任務簽到金666
富遊VIP全面啟動
復酬金活動10%優惠
日日返水
新會員好禮五選一
首存禮1000送1000
免費體驗金$168
富遊娛樂城APP
步驟1 : 開啟網頁版【富遊娛樂城官網】
步驟2 : 點選上方(下載app),會跳出下載與複製連結選項,點選後跳轉。
步驟3 : 跳轉後點選(安裝),並點選(允許)操作下載描述檔,跳出下載描述檔後點選關閉。
步驟4 : 到手機設置>一般>裝置管理>設定描述檔(富遊)安裝,即可完成安裝。
富遊娛樂城常見問題FAQ
富遊娛樂城詐騙?
黑網詐騙可細分兩種,小出大不出及純詐騙黑網,我們可從品牌知名度經營和網站架設畫面分辨來簡單分辨。
富遊娛樂城會出金嗎?
如上面提到,富遊是在做一個品牌,為的是能夠保證出金,和帶領玩家遠離黑網,而且還有DUKER娛樂城出金認證,所以各位能夠放心富遊娛樂城為正出金娛樂城。
富遊娛樂城出金延遲怎麼辦?
基本上只要是公司系統問提造成富遊娛樂城會員無法在30分鐘成功提款,富遊娛樂城會即刻派送補償金,表達誠摯的歉意。
富遊娛樂城結論
富遊娛樂城安心玩,評價4.5顆星。如果還想看其他娛樂城推薦的,可以來娛樂城推薦尋找喔。
https://mexicanpharmacy.win/# buying from online mexican pharmacy mexicanpharmacy.win
indian pharmacy
http://mexicanpharmacy.win/# mexican pharmacy mexicanpharmacy.win
https://indianpharmacy.shop/# india pharmacy mail order indianpharmacy.shop
buy medicines online in india
戰神賽特
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
戰神賽特試玩推薦
看完了❰戰神賽特老虎機❱介紹之後,玩家們是否也蓄勢待發要進入古埃及的世界,一探神奇秘寶探險之旅。
本次ATG賽特與線上娛樂城推薦第一名的富遊娛樂城合作,只需要加入會員,即可領取到168體驗金,免費試玩420轉!
https://canadianpharmacy.pro/# canadian pharmacy online canadianpharmacy.pro
https://mexicanpharmacy.win/# reputable mexican pharmacies online mexicanpharmacy.win
https://canadianpharmacy.pro/# canadian pharmacy service canadianpharmacy.pro
prescription without a doctor’s prescription
https://canadianpharmacy.pro/# canada pharmacy reviews canadianpharmacy.pro
india pharmacy mail order
https://indianpharmacy.shop/# best india pharmacy indianpharmacy.shop
The LB News is the local news source for Long Beach and the surrounding area providing breaking news, sports, business, entertainment, things to do, opinion, photos, videos and more https://lbnews.us/
I am incessantly thought about this, thanks for posting.
My website: массаж интим
Thank you for every other informative site. Where else may I get that kind of information written in such a perfect approach? I’ve a project that I’m simply now operating on, and I have been at the glance out for such info.
http://pharmadoc.pro/# Pharmacie en ligne fiable
Pharmacies en ligne certifiГ©es
http://acheterkamagra.pro/# pharmacie en ligne
pharmacie ouverte Pharmacies en ligne certifiees Pharmacies en ligne certifiГ©es
Pharmacie en ligne livraison 24h: cialis prix – Pharmacie en ligne fiable
Boulder News
Pharmacie en ligne pas cher pharmacie en ligne pas cher pharmacie ouverte 24/24
https://acheterkamagra.pro/# pharmacie en ligne
Muchos Gracias for your article.Really thank you! Cool.
My website: категории русского порно
Viagra en france livraison rapide Viagra homme prix en pharmacie sans ordonnance Viagra sans ordonnance 24h suisse
acheter mГ©dicaments Г l’Г©tranger: pharmacie ouverte 24/24 – Pharmacie en ligne livraison 24h
http://pharmadoc.pro/# п»їpharmacie en ligne
Pharmacie en ligne pas cher
https://levitrasansordonnance.pro/# Pharmacies en ligne certifiées
A round of applause for your article. Much thanks again.
My website: секс студентки русское
Pharmacie en ligne France: acheter kamagra site fiable – Pharmacie en ligne livraison rapide
Дома АВС – Ваш уютный уголок
Мы строим не просто дома, мы создаем пространство, где каждый уголок будет наполнен комфортом и радостью жизни. Наш приоритет – не просто предоставить место для проживания, а создать настоящий дом, где вы будете чувствовать себя счастливыми и уютно.
В нашем информационном разделе “ПРОЕКТЫ” вы всегда найдете вдохновение и новые идеи для строительства вашего будущего дома. Мы постоянно работаем над тем, чтобы предложить вам самые инновационные и стильные проекты.
Мы убеждены, что основа хорошего дома – это его дизайн. Поэтому мы предоставляем услуги опытных дизайнеров-архитекторов, которые помогут вам воплотить все ваши идеи в жизнь. Наши архитекторы и персональные консультанты всегда готовы поделиться своим опытом и предложить функциональные и комфортные решения для вашего будущего дома.
Мы стремимся сделать весь процесс строительства максимально комфортным для вас. Наша команда предоставляет детализированные сметы, разрабатывает четкие этапы строительства и осуществляет контроль качества на каждом этапе.
Для тех, кто ценит экологичность и близость к природе, мы предлагаем деревянные дома премиум-класса. Используя клееный брус и оцилиндрованное бревно, мы создаем уникальные и здоровые условия для вашего проживания.
Тем, кто предпочитает надежность и многообразие форм, мы предлагаем дома из камня, блоков и кирпичной кладки.
Для практичных и ценящих свое время людей у нас есть быстровозводимые каркасные дома и эконом-класса. Эти решения обеспечат вас комфортным проживанием в кратчайшие сроки.
С Домами АВС создайте свой уютный уголок, где каждый момент жизни будет наполнен радостью и удовлетворением
http://viagrasansordonnance.pro/# Sildénafil Teva 100 mg acheter
Pharmacie en ligne fiable: cialis generique – Pharmacies en ligne certifiГ©es
I am really enjoying the theme/design of your website. Do you ever run into any browser compatibility problems? A couple of my blog visitors have complained about my website not operating correctly in Explorer but looks great in Safari. Do you have any ideas to help fix this issue?
Hi there this is somewhat of off topic but I was wanting to know if blogs use WYSIWYG editors or if you have to manually code with HTML. I’m starting a blog soon but have no coding know-how so I wanted to get guidance from someone with experience. Any help would be enormously appreciated!
Viagra pas cher paris: viagra sans ordonnance – Viagra Pfizer sans ordonnance
https://acheterkamagra.pro/# pharmacie en ligne
https://rg888.app/set/
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
戰神賽特試玩推薦
看完了❰戰神賽特老虎機❱介紹之後,玩家們是否也蓄勢待發要進入古埃及的世界,一探神奇秘寶探險之旅。
本次ATG賽特與線上娛樂城推薦第一名的富遊娛樂城合作,只需要加入會員,即可領取到168體驗金,免費試玩420轉!
I need to to thank you for this fantastic read!! I definitely loved every bit of it. I have you bookmarked to check out new stuff you post?
Viagra Pfizer sans ordonnance: viagra sans ordonnance – Viagra sans ordonnance pharmacie France
This site definitely has all of the information I needed about this subject
My website: школьница порно
http://cialissansordonnance.shop/# acheter médicaments à l’étranger
https://levitrasansordonnance.pro/# Pharmacie en ligne livraison 24h
Pharmacies en ligne certifiГ©es
The latest video game news, reviews, exclusives, streamers, esports, and everything else gaming. https://zaaz.us/
Oakland County, MI News, Sports, Weather, Things to Do https://oaklandpost.us/
Canon City, Colorado News, Sports, Weather and Things to Do https://canoncitynews.us/
https://acheterkamagra.pro/# pharmacie ouverte
Pharmacies en ligne certifiГ©es: Pharmacies en ligne certifiees – Pharmacie en ligne pas cher
I am incessantly thought about this, thanks for posting.
My website: porno russian teen teacher
I reckon something truly special in this website.
My website: секс с преподом
https://ivermectin.store/# ivermectin cost
prednisone 21 pack: apo prednisone – prednisone without prescription
socialmediatric.com
“공식 문서는 없고 구술, 도박, 이기기, 이기기!”
https://amoxicillin.bid/# how to buy amoxycillin
where to get clomid prices: order clomid without a prescription – order generic clomid tablets
rivipaolo.com
홀에 있던 양반들과 관료들이 낮은 목소리로 토론하기 시작했다.
ivermectin 0.1: cost of ivermectin cream – stromectol drug
You actually make it appear so easy along with your presentation however I to find this matter to be actually one thing that I think I’d by no means understand. It kind of feels too complicated and very extensive for me. I am having a look forward on your subsequent post, I?ll attempt to get the dangle of it!
https://amoxicillin.bid/# price for amoxicillin 875 mg
Great post. I am facing a couple of these problems.
ivermectin coronavirus: ivermectin 3 – ivermectin buy australia
http://azithromycin.bid/# where can i buy zithromax uk
Valley News covers local news from Pomona to Ontario including, California news, sports, things to do, and business in the Inland Empire. https://valleynews.us/
zithromax antibiotic: buy cheap zithromax online – zithromax buy online no prescription
https://ivermectin.store/# ivermectin 4 tablets price
https://amoxicillin.bid/# amoxicillin in india
amoxicillin 500mg capsules antibiotic: price for amoxicillin 875 mg – amoxicillin 500 mg capsule
https://azithromycin.bid/# zithromax 500mg price
Get Lehigh Valley news, Allentown news, Bethlehem news, Easton news, Quakertown news, Poconos news and Pennsylvania news from Morning Post. https://morningpost.us/
Pilot News: Your source for Virginia breaking news, sports, business, entertainment, weather and traffic https://pilotnews.us/
buy zithromax online australia: can i buy zithromax over the counter – zithromax antibiotic
Evidence-based resource on weight loss, nutrition, low-carb meal planning, gut health, diet reviews and weight-loss plans. We offer in-depth reviews on diet supplements, products and programs. https://healthpress.us/
Supplement Reviews – Get unbiased ratings and reviews for 1000 products from Consumer Reports, plus trusted advice and in-depth reporting on what matters most. https://supplementreviews.us/
https://amoxicillin.bid/# amoxicillin 500mg capsules antibiotic
The destination for entertainment and women’s lifestyle – from royals news, fashion advice, and beauty tips, to celebrity interviews, and more. https://womenlifestyle.us/
buying prednisone from canada: buy prednisone mexico – prednisone 250 mg
Mass News is the leading source of breaking news, local news, sports, business, entertainment, lifestyle and opinion for Silicon Valley, San Francisco Bay Area and beyond https://massnews.us/
buy prednisone 50 mg: buying prednisone from canada – prednisone purchase online
Foodie Blog is the destination for living a delicious life – from kitchen tips to culinary history, celebrity chefs, restaurant recommendations, and much more. https://foodieblog.us/
http://clomiphene.icu/# how to buy clomid without dr prescription
The Boston Post is the leading source of breaking news, local news, sports, politics, entertainment, opinion and weather in Boston, Massachusetts. https://bostonpost.us/
http://azithromycin.bid/# can i buy zithromax over the counter
Aw, this was a really nice post. In thought I want to put in writing like this additionally – taking time and actual effort to make an excellent article… however what can I say… I procrastinate alot and in no way seem to get something done.
cost of clomid without a prescription: can you buy cheap clomid without dr prescription – order generic clomid online
http://amoxicillin.bid/# amoxicillin without rx
order amoxicillin online uk amoxicillin no prescription amoxicillin price canada
prednisone 20mg online pharmacy: can i order prednisone – 50 mg prednisone tablet
azithromycin zithromax: how much is zithromax 250 mg – buy cheap zithromax online
Holy moly, this website is an absolute treasure chest of information! I could not stop perusing from start to finish. Every word is like a magic spell that keeps me mesmerized. Can’t wait for additional mind-blowing posts! #ImpressiveWebsite #IncredibleContent
Ohio Reporter – Ohio News, Sports, Weather and Things to Do https://ohioreporter.us/
Vacavillenews.us covers local news in Vacaville, California. Keep up with all business, local sports, outdoors, local columnists and more. https://vacavillenews.us/
canadian pharmacy 1 internet online drugstore: Licensed Online Pharmacy – canadian world pharmacy canadianpharm.store
Fashion More provides in-depth journalism and insight into the news and trends impacting the fashion
https://indianpharm.store/# online shopping pharmacy india indianpharm.store
saungsantoso.com
노인과 선생님은 모든 것을 할 수 있습니다. 지금 농담입니까?
canadian pharmacy: legitimate canadian pharmacies – canadian pharmacy king reviews canadianpharm.store
mexican online pharmacies prescription drugs: Certified Pharmacy from Mexico – pharmacies in mexico that ship to usa mexicanpharm.shop
http://canadianpharm.store/# canadian pharmacy antibiotics canadianpharm.store
pharmacy website india: Indian pharmacy to USA – Online medicine home delivery indianpharm.store
Даркнет, сокращение от “даркнетворк” (dark network), представляет собой часть интернета, недоступную для обычных поисковых систем. В отличие от повседневного интернета, где мы привыкли к публичному контенту, даркнет скрыт от обычного пользователя. Здесь используются специальные сети, такие как Tor (The Onion Router), чтобы обеспечить анонимность пользователей.
Great line up. We will be linking to this great article on our site. Keep up the good writing.
medicine in mexico pharmacies: Certified Pharmacy from Mexico – purple pharmacy mexico price list mexicanpharm.shop
http://canadianpharm.store/# canadadrugpharmacy com canadianpharm.store
PharmaMore provides a forum for industry leaders to hear the most important voices and ideas in the industry. https://pharmamore.us/
https://mexicanpharm.shop/# pharmacies in mexico that ship to usa mexicanpharm.shop
Medical More provides medical technology news and analysis for industry professionals. We cover medical devices, diagnostics, digital health, FDA regulation and compliance, imaging, and more. https://medicalmore.us
digiyumi.com
Liu Jian과 다른 사람들은 파란색에서 온 볼트처럼 느껴졌고 마음은 완전히 차가워졌습니다.
online pharmacy india: Indian pharmacy to USA – Online medicine order indianpharm.store
Absolutely indited subject matter, Really enjoyed examining.
https://indianpharm.store/# legitimate online pharmacies india indianpharm.store
http://indianpharm.store/# mail order pharmacy india indianpharm.store
I think the admin of this site is really working hard for his website since here every stuff is quality based data.<a href="https://www.google.co.il/url?sa=t
hi!,I love your writing very so much! percentage we communicate more about your post on AOL? I need a specialist in this area to solve my problem. May be that is you! Looking forward to see you.
п»їbest mexican online pharmacies: mexican rx online – mexican pharmaceuticals online mexicanpharm.shop
http://canadianpharm.store/# legal canadian pharmacy online canadianpharm.store
Howdy! This is my 1st comment here so I just wanted to give a quick shout out and tell you I truly enjoy reading your blog posts. Can you recommend any other blogs/websites/forums that go over the same topics? Many thanks!
mexican drugstore online: Online Mexican pharmacy – mexican pharmaceuticals online mexicanpharm.shop
Local news from Redlands, CA, California news, sports, things to do, and business in the Inland Empire. https://redlandsnews.us
Thank you for every other magnificent article. The place else may anyone get that type of info in such a perfect manner of writing? I’ve a presentation subsequent week, and I am at the search for such info.
https://indianpharm.store/# buy medicines online in india indianpharm.store
best online pharmacy india: order medicine from india to usa – online shopping pharmacy india indianpharm.store
NewsBreak provides latest and breaking Renton, WA local news, weather forecast, crime and safety reports, traffic updates, event notices, sports https://rentonnews.us
world pharmacy india: Indian pharmacy to USA – indian pharmacies safe indianpharm.store
http://canadianpharm.store/# pharmacy canadian canadianpharm.store
Bellevue Latest Headlines: City of Bellevue can Apply for Digital Equity Grant https://bellevuenews.us
mexico drug stores pharmacies: Certified Pharmacy from Mexico – mexican border pharmacies shipping to usa mexicanpharm.shop
buying from online mexican pharmacy: Online Pharmacies in Mexico – mexican rx online mexicanpharm.shop
https://indianpharm.store/# indian pharmacy paypal indianpharm.store
https://indianpharm.store/# mail order pharmacy india indianpharm.store
best online pharmacy india: Indian pharmacy to USA – cheapest online pharmacy india indianpharm.store
Definitely, what a great blog and revealing posts, I definitely will bookmark your site. Best Regards!
My website: порно русское с преподом
https://mexicanpharm.shop/# buying prescription drugs in mexico online mexicanpharm.shop
п»їbest mexican online pharmacies: buying prescription drugs in mexico online – buying prescription drugs in mexico mexicanpharm.shop
buy medicines online in india: Indian pharmacy to USA – Online medicine home delivery indianpharm.store
https://mexicanpharm.shop/# mexican mail order pharmacies mexicanpharm.shop
mexican mail order pharmacies: best online pharmacies in mexico – mexico drug stores pharmacies mexicanpharm.shop
mexican pharmaceuticals online: mexico drug stores pharmacies – mexico drug stores pharmacies mexicanpharm.shop
chasemusik.com
얼굴을 향해 불어오는 폭염과 함께 거센 바람이 사람들의 얼굴을 아프게 했다.
https://canadianpharm.store/# pharmacy com canada canadianpharm.store
Reading, PA News, Sports, Weather, Things to Do http://readingnews.us/
https://mexicanpharm.shop/# mexico pharmacies prescription drugs mexicanpharm.shop
mexican drugstore online: Certified Pharmacy from Mexico – mexico drug stores pharmacies mexicanpharm.shop
I absolutely love your blog and find the majority of your post’s to be just what I’m looking for. Do you offer guest writers to write content in your case? I wouldn’t mind creating a post or elaborating on a lot of the subjects you write concerning here. Again, awesome site!
online shopping pharmacy india: india online pharmacy – indian pharmacy online indianpharm.store
https://mexicanpharm.shop/# pharmacies in mexico that ship to usa mexicanpharm.shop
Definitely, what a great blog and revealing posts, I definitely will bookmark your site. Best Regards!
My website: порно арабы
娛樂城
**娛樂城與線上賭場:現代娛樂的轉型與未來**
在當今數位化的時代,”娛樂城”和”線上賭場”已成為現代娛樂和休閒生活的重要組成部分。從傳統的賭場到互聯網上的線上賭場,這一領域的發展不僅改變了人們娛樂的方式,也推動了全球娛樂產業的創新與進步。
**起源與發展**
娛樂城的概念源自於傳統的實體賭場,這些場所最初旨在提供各種形式的賭博娛樂,如撲克、輪盤、老虎機等。隨著時間的推移,這些賭場逐漸發展成為包含餐飲、表演藝術和住宿等多元化服務的綜合娛樂中心,從而吸引了來自世界各地的遊客。
隨著互聯網技術的飛速發展,線上賭場應運而生。這種新型態的賭博平台讓使用者可以在家中或任何有互聯網連接的地方,享受賭博遊戲的樂趣。線上賭場的出現不僅為賭博愛好者提供了更多便利與選擇,也大大擴展了賭博產業的市場範圍。
**特點與魅力**
娛樂城和線上賭場的主要魅力在於它們能提供多樣化的娛樂選項和高度的可訪問性。無論是實體的娛樂城還是虛擬的線上賭場,它們都致力於創造一個充滿樂趣和刺激的環境,讓人們可以從日常生活的壓力中短暫逃脫。
此外,線上賭場通過提供豐富的遊戲選擇、吸引人的獎金方案以及便捷的支付系統,成功地吸引了全球範圍內的用戶。這些平台通常具有高度的互動性和社交性,使玩家不僅能享受遊戲本身,還能與來自世界各地的其他玩家交流。
**未來趨勢**
隨著技術的不斷進步和用戶需求的不斷演變,娛樂城和線上賭場的未來發展呈現出多元化的趨勢。一方面,虛
擬現實(VR)和擴增現實(AR)技術的應用,有望為線上賭場帶來更加沉浸式和互動式的遊戲體驗。另一方面,對於實體娛樂城而言,將更多地注重提供綜合性的休閒體驗,結合賭博、娛樂、休閒和旅遊等多個方面,以滿足不同客群的需求。
此外,隨著對負責任賭博的認識加深,未來娛樂城和線上賭場在提供娛樂的同時,也將更加注重促進健康的賭博行為和保護用戶的安全。
總之,娛樂城和線上賭場作為現代娛樂生活的一部分,隨著社會的發展和技術的進步,將繼續演化和創新,為人們提供更多的樂趣和便利。這一領域的未來發展無疑充滿了無限的可能性和機遇。
Touche. Sound arguments. Keep up the amazing effort.
canada online pharmacy: legitimate canadian internet pharmacies – canadian online pharmacies not requiring a prescription
I know this if off topic but I’m looking into starting my own weblog
and was wondering what all is needed to get setup? I’m assuming having a blog like yours would cost a
pretty penny? I’m not very internet savvy so I’m not 100% certain. Any tips or advice would be greatly appreciated.
Cheers
certainly like your web site but you need to take a look at the spelling on several of your posts. Many of them are rife with spelling issues and I find it very troublesome to inform the reality then again I will surely come back again.
Very interesting subject, regards for putting up. “Everything in the world may be endured except continued prosperity.” by Johann von Goethe.
http://canadadrugs.pro/# canada pharmacy
fda approved online pharmacies: canadian pharmacies that are legit – best online pharmacies without a script
Thank you ever so for you blog. Really looking forward to read more.
My website: ебут мамок
Absolutely written written content, appreciate it for information .
http://canadadrugs.pro/# canadian pharmacy no presciption
canadian pharmacy 24hr: legitimate canadian pharmacies online – prescription price comparison
I keep listening to the newscast speak about receiving boundless online grant applications so I have been looking around for the top site to get one. Could you tell me please, where could i get some?
I reckon something truly special in this website.
My website: секс с красивым трансом
cheap prescription drugs: online pharmacy without a prescription – certified online canadian pharmacies
https://canadadrugs.pro/# canadian pharmacy cialis cheap
Read the latest news on Crime, Politics, Schools, Sports, Weather, Business, Arts, Jobs, Obits, and Things to do in Kent Washington. https://kentnews.us/
Maryland Post: Your source for Maryland breaking news, sports, business, entertainment, weather and traffic https://marylandpost.us
Peninsula News is a daily news website, covering the northern Olympic Peninsula in the state of Washington, United States. https://peninsulanews.us
Fresh, flavorful and (mostly) healthy recipes made for real, actual, every day life. Helping you celebrate the joy of food in a totally non-intimidating way. https://skillfulcook.us
http://canadadrugs.pro/# online meds without presxription
My website: секс зрелых милф
Macomb County, MI News, Breaking News, Sports, Weather, Things to Do https://macombnews.us
This blog is definitely rather handy since I’m at the moment creating an internet floral website – although I am only starting out therefore it’s really fairly small, nothing like this site. Can link to a few of the posts here as they are quite. Thanks much. Zoey Olsen
Get Lehigh Valley news, Allentown news, Bethlehem news, Easton news, Quakertown news, Poconos news and Pennsylvania news from Morning Post. https://morningpost.us
OCNews.us covers local news in Orange County, CA, California and national news, sports, things to do and the best places to eat, business and the Orange County housing market. https://ocnews.us
legitimate canadian online pharmacy: certified canadian online pharmacy – canadian pharcharmy online
I have not checked in here for some time since I thought it was getting boring, but the last few posts are good quality so I guess I will add you back to my everyday bloglist. You deserve it my friend 🙂
discount prescription drugs: no 1 canadian pharmacy – legitimate canadian internet pharmacies
http://canadadrugs.pro/# discount pharmaceuticals
Great beat ! I would like to apprentice while you amend your web site, how can i subscribe for a blog site? The account helped me a acceptable deal. I had been a little bit acquainted of this your broadcast provided bright clear concept
Some genuinely nice stuff on this web site, I love it.
kinoboomhd.com
어지러운 일이 왜 나와 관련이 있는 건지…
Respect to post author, some fantastic information
My website: порно больно в анал
I¦ve learn some just right stuff here. Definitely worth bookmarking for revisiting. I wonder how much effort you place to create one of these excellent informative site.
Good day! Do you know if they make any plugins to help with Search Engine Optimization? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good success. If you know of any please share. Thank you!
canadian pharmacies that sell viagra: safe online canadian pharmacy – no 1 canadian pharcharmy online
http://canadadrugs.pro/# canadian pharmacy advair
http://canadadrugs.pro/# overseas pharmacies that deliver to usa
Wohh precisely what I was searching for, regards for putting up.
My website: порно в жопу боль
aarp canadian pharmacy: canadian pharmacies that ship to us – cheapest canadian online pharmacy
modernkarachi.com
Zhen Guo Mansion에 도착했을 때 영국 공작은 얼굴을 들고 초조하게 기다렸습니다.
rx canada: trustworthy canadian pharmacy – buying drugs canada
I like this web blog very much, Its a rattling nice post to read and get info .
Right now it appears like Movable Type is the best blogging platform out there right now. (from what I’ve read) Is that what you are using on your blog?
http://canadadrugs.pro/# best online canadian pharcharmy
canadian pharmacy cialis cheap: safe canadian pharmacies online – best canadian online pharmacy
canadian pharmacy without prescription: pharmacy review – online pharmacy no prescription
http://canadadrugs.pro/# cheapest canadian pharmacy
I’m extremely pleased to discover this website. I wanted to thank you for ones time just for this fantastic read!
My website: волосатые зрелые женщины видео
side jobs from per click
Understanding the processes and protocols within a Professional Tenure Committee (PTC) is crucial for faculty members. This Frequently Asked Questions (FAQ) guide aims to address common queries related to PTC procedures, voting, and membership.
1. Why should members of the PTC fill out vote justification forms explaining their votes?
Vote justification forms provide transparency in decision-making. Members articulate their reasoning, fostering a culture of openness and ensuring that decisions are well-founded and understood by the academic community.
2. How can absentee ballots be cast?
To accommodate absentee voting, PTCs may implement secure electronic methods or designated proxy voters. This ensures that faculty members who cannot physically attend meetings can still contribute to decision-making processes.
3. How will additional members of PTCs be elected in departments with fewer than four tenured faculty members?
In smaller departments, creative solutions like rotating roles or involving faculty from related disciplines can be explored. Flexibility in election procedures ensures representation even in departments with fewer tenured faculty members.
4. Can a faculty member on OCSA or FML serve on a PTC?
Faculty members involved in other committees like the Organization of Committee on Student Affairs (OCSA) or Family and Medical Leave (FML) can serve on a PTC, but potential conflicts of interest should be carefully considered and managed.
5. Can an abstention vote be cast at a PTC meeting?
Yes, PTC members have the option to abstain from voting if they feel unable to take a stance on a particular matter. This allows for ethical decision-making and prevents uninformed voting.
6. What constitutes a positive or negative vote in PTCs?
A positive vote typically indicates approval or agreement, while a negative vote signifies disapproval or disagreement. Clear definitions and guidelines within each PTC help members interpret and cast their votes accurately.
7. What constitutes a quorum in a PTC?
A quorum, the minimum number of members required for a valid meeting, is essential for decision-making. Specific rules about quorum size are usually outlined in the PTC’s governing documents.
Our Plan Packages: Choose The Best Plan for You
Explore our plan packages designed to suit your earning potential and preferences. With daily limits, referral bonuses, and various subscription plans, our platform offers opportunities for financial growth.
Blog Section: Insights and Updates
Stay informed with our blog, providing valuable insights into legal matters, organizational updates, and industry trends. Our recent articles cover topics ranging from law firm openings to significant developments in the legal landscape.
Testimonials: What Our Clients Say
Discover what our clients have to say about their experiences. Join thousands of satisfied users who have successfully withdrawn earnings and benefited from our platform.
Conclusion:
This FAQ guide serves as a resource for faculty members engaging with PTC procedures. By addressing common questions and providing insights into our platform’s earning opportunities, we aim to facilitate a transparent and informed academic community.
https://canadadrugs.pro/# pharmacy in canada
I’m not that much of a internet reader to be honest but your sites really nice,
keep it up! I’ll go ahead and bookmark your website
to come back in the future. Cheers
http://canadadrugs.pro/# canada pharmacies
pharmacy cost comparison: best non prescription online pharmacies – compare prices prescription drugs
safe online pharmacies in canada: best canadian pharmacy online – best canadian online pharmacy
Muchos Gracias for your article.Really thank you! Cool.
My website: порно трах дома
http://edpill.cheap/# best over the counter ed pills
Hello! I know this is kinda off topic but I’d figured I’d ask. Would you be interested in trading links or maybe guest authoring a blog article or vice-versa? My site addresses a lot of the same topics as yours and I believe we could greatly benefit from each other. If you happen to be interested feel free to send me an e-mail. I look forward to hearing from you! Fantastic blog by the way!
https://certifiedpharmacymexico.pro/# purple pharmacy mexico price list
india online pharmacy: best india pharmacy – top online pharmacy india
http://canadianinternationalpharmacy.pro/# pharmacy canadian
http://medicinefromindia.store/# top online pharmacy india
mexican drugstore online reputable mexican pharmacies online mexico drug stores pharmacies
cheapest online pharmacy india: Online medicine home delivery – india pharmacy
top erection pills: the best ed pill – pills erectile dysfunction
Understanding the processes and protocols within a Professional Tenure Committee (PTC) is crucial for faculty members. This Frequently Asked Questions (FAQ) guide aims to address common queries related to PTC procedures, voting, and membership.
1. Why should members of the PTC fill out vote justification forms explaining their votes?
Vote justification forms provide transparency in decision-making. Members articulate their reasoning, fostering a culture of openness and ensuring that decisions are well-founded and understood by the academic community.
2. How can absentee ballots be cast?
To accommodate absentee voting, PTCs may implement secure electronic methods or designated proxy voters. This ensures that faculty members who cannot physically attend meetings can still contribute to decision-making processes.
3. How will additional members of PTCs be elected in departments with fewer than four tenured faculty members?
In smaller departments, creative solutions like rotating roles or involving faculty from related disciplines can be explored. Flexibility in election procedures ensures representation even in departments with fewer tenured faculty members.
4. Can a faculty member on OCSA or FML serve on a PTC?
Faculty members involved in other committees like the Organization of Committee on Student Affairs (OCSA) or Family and Medical Leave (FML) can serve on a PTC, but potential conflicts of interest should be carefully considered and managed.
5. Can an abstention vote be cast at a PTC meeting?
Yes, PTC members have the option to abstain from voting if they feel unable to take a stance on a particular matter. This allows for ethical decision-making and prevents uninformed voting.
6. What constitutes a positive or negative vote in PTCs?
A positive vote typically indicates approval or agreement, while a negative vote signifies disapproval or disagreement. Clear definitions and guidelines within each PTC help members interpret and cast their votes accurately.
7. What constitutes a quorum in a PTC?
A quorum, the minimum number of members required for a valid meeting, is essential for decision-making. Specific rules about quorum size are usually outlined in the PTC’s governing documents.
Our Plan Packages: Choose The Best Plan for You
Explore our plan packages designed to suit your earning potential and preferences. With daily limits, referral bonuses, and various subscription plans, our platform offers opportunities for financial growth.
Blog Section: Insights and Updates
Stay informed with our blog, providing valuable insights into legal matters, organizational updates, and industry trends. Our recent articles cover topics ranging from law firm openings to significant developments in the legal landscape.
Testimonials: What Our Clients Say
Discover what our clients have to say about their experiences. Join thousands of satisfied users who have successfully withdrawn earnings and benefited from our platform.
Conclusion:
This FAQ guide serves as a resource for faculty members engaging with PTC procedures. By addressing common questions and providing insights into our platform’s earning opportunities, we aim to facilitate a transparent and informed academic community.
http://edwithoutdoctorprescription.pro/# real viagra without a doctor prescription
generic ed pills erectile dysfunction drug ed remedies
I went over this website and I think you have a lot of wonderful info , saved to bookmarks (:.
http://canadianinternationalpharmacy.pro/# best canadian pharmacy
https://edwithoutdoctorprescription.pro/# buy prescription drugs from canada cheap
I gotta favorite this site it seems very beneficial handy
My website: ебля на природе
http://medicinefromindia.store/# online shopping pharmacy india
top 10 online pharmacy in india: Online medicine home delivery – pharmacy website india
legit canadian pharmacy: canadianpharmacyworld com – reliable canadian pharmacy reviews
india pharmacy mail order best online pharmacy india pharmacy website india
https://certifiedpharmacymexico.pro/# pharmacies in mexico that ship to usa
Kraken darknet market зеркало
Даркнет, представляет собой, невидимую, платформу, на, интернете, вход в нее, реализуется, по средствам, специальные, программы и, технические средства, сохраняющие, конфиденциальность сетевых участников. Одним из, таких, инструментов, является, браузер Тор, который, обеспечивает, защищенное, подключение в темную сторону интернета. С помощью, этот, сетевые пользователи, могут иметь шанс, незаметно, обращаться к, сайты, не отображаемые, обычными, поисковыми системами, что делает возможным, условия, для организации, различных, нелегальных активностей.
Кракен, соответственно, часто ассоциируется с, скрытой сетью, в качестве, рынок, осуществления обмена, криминалитетом. На данной платформе, можно, приобрести, разные, запрещенные, вещи, начиная от, наркотиков и стволов, вплоть до, хакерскими действиями. Платформа, предоставляет, высокую степень, криптографической защиты, а, защиты личной информации, что, создает, ее, привлекательной, для тех, кто, намерен, уклониться от, негативных последствий, от правоохранительных органов
Major thanks for the article post. Much thanks again.
My website: глубоко сосет член
кракен kraken kraken darknet top
Темная сторона интернета, это, анонимную, сеть, на, интернете, вход, получается, по средствам, уникальные, приложения а также, инструменты, обеспечивающие, конфиденциальность участников. Из числа, подобных, инструментов, представляется, Тор браузер, который позволяет, обеспечивает, защищенное, подключение, к сети Даркнет. С помощью, его же, участники, имеют возможность, анонимно, заходить, интернет-ресурсы, не индексируемые, стандартными, поисками, создавая тем самым, среду, для, разнообразных, противоправных деятельностей.
Кракен, в результате, часто ассоциируется с, даркнетом, в качестве, площадка, для, киберугрозами. На этой площадке, есть возможность, получить доступ к, разнообразные, непозволительные, товары, начиная от, наркотических средств и огнестрельного оружия, вплоть до, хакерскими услугами. Платформа, предоставляет, высокий уровень, шифрования, и также, защиты личной информации, что, делает, эту площадку, желанной, для, намерен, избежать, наказания, от правоохранительных органов.
https://certifiedpharmacymexico.pro/# buying prescription drugs in mexico online
online ed medications: medicine erectile dysfunction – best ed pill
This site definitely has all of the information I needed about this subject
My website: русское анальное порно видео
https://edpill.cheap/# best erectile dysfunction pills
The latest news and reviews in the world of tech, automotive, gaming, science, and entertainment. https://millionbyte.us/
gnc ed pills: ed pills – ed pills that work
https://certifiedpharmacymexico.pro/# mexican pharmaceuticals online
homefronttoheartland.com
Liu Kaizhi는 그것을 몰랐고 잠시 동안 Chen Tong의 마음이 조금 바뀌었습니다.
Major thanks for the article post. Much thanks again.
My website: Фут фетиш
http://edpill.cheap/# new ed drugs
netovideo.com
Li Zheng이 말한 것은 … Zhu Zaimo를 잠시 침묵하게 만들었습니다.이곳은… 미국의 가장 중심적인 위치인 북미입니다.
Hmm is anyone else having problems with the pictures on this blog loading?
I’m trying to determine if its a problem on my end or if it’s the blog.
Any suggestions would be greatly appreciated.
http://canadianinternationalpharmacy.pro/# canadian pharmacy drugs online
medicine in mexico pharmacies: purple pharmacy mexico price list – mexican border pharmacies shipping to usa
https://medicinefromindia.store/# cheapest online pharmacy india
colibrim.com web site.
Темная сторона интернета, является, анонимную, платформу, в, интернете, подключение к этой сети, реализуется, через, определенные, приложения а также, технологии, гарантирующие, скрытность участников. Один из, этих, технических решений, является, The Onion Router, который обеспечивает, гарантирует, приватное, подключение к интернету, в даркнет. С, его же, участники, могут, незаметно, обращаться к, сайты, не отображаемые, традиционными, поисковыми сервисами, что делает возможным, среду, для осуществления, разносторонних, противоправных действий.
Киберторговая площадка, в свою очередь, часто ассоциируется с, даркнетом, в качестве, рынок, для осуществления обмена, киберпреступниками. На данной платформе, можно, приобрести, разнообразные, нелегальные, услуги, начиная от, препаратов и огнестрельного оружия, заканчивая, хакерскими действиями. Ресурс, гарантирует, крупную долю, криптографической защиты, и также, защиты личной информации, это, создает, ее, интересной, для, намерен, избежать, негативных последствий, со стороны правоохранительных органов.
https://medicinefromindia.store/# online shopping pharmacy india
This site definitely has all of the information I needed about this subject
My website: армянка анал
colibrim.com
http://canadianinternationalpharmacy.pro/# canadian pharmacy online ship to usa
colibrim.com
colibrim.com
colibrim.com
colibrim.com
colibrim.com
http://edpill.cheap/# ed remedies
ed meds online without doctor prescription: generic cialis without a doctor prescription – prescription drugs canada buy online
Wohh precisely what I was searching for, regards for putting up.
My website: жены любящие групповухи
https://canadianinternationalpharmacy.pro/# canadian pharmacy 365
http://medicinefromindia.store/# reputable indian pharmacies
https://edpill.cheap/# erectile dysfunction drug
As a Newbie, I am continuously exploring online for articles that can be of assistance to me.
My website: армянское порно
http://medicinefromindia.store/# Online medicine order
pharmacy canadian: canadapharmacyonline com – canada pharmacy online
Watches World
My website: огромный член
http://canadianinternationalpharmacy.pro/# cross border pharmacy canada
I truly appreciate this post. I have been looking everywhere for this! Thank goodness I found it on Bing. You have made my day! Thank you again!
It?¦s really a cool and helpful piece of info. I am glad that you simply shared this useful information with us. Please stay us up to date like this. Thanks for sharing.
I am absolutely thrilled to introduce you to the incredible Sumatra Slim Belly Tonic! This powdered weight loss formula is like no other, featuring a powerful blend of eight natural ingredients that are scientifically linked to fat burning, weight management, and overall weight loss. Just imagine the possibilities! With Sumatra Slim Belly Tonic, you have the opportunity to finally achieve your weight loss goals and transform your body into the best version of yourself.
http://medicinefromindia.store/# best india pharmacy
best india pharmacy world pharmacy india cheapest online pharmacy india
https://mexicanph.shop/# mexican rx online
buying prescription drugs in mexico
pharmacies in mexico that ship to usa buying from online mexican pharmacy mexican rx online
Respect to post author, some fantastic information
My website: очень красивая жена порно
mexican drugstore online mexican border pharmacies shipping to usa best online pharmacies in mexico
Very good written information. It will be beneficial to anybody who usess it, including yours truly :). Keep up the good work – can’r wait to read more posts.
mexico drug stores pharmacies mexican pharmaceuticals online mexico drug stores pharmacies
Great info. Lucky me I discovered your website by chance (stumbleupon).
I’ve bookmarked it for later!
Oh my goodness! a tremendous article dude. Thank you Nonetheless I’m experiencing situation with ur rss . Don’t know why Unable to subscribe to it. Is there anybody getting similar rss problem? Anybody who is aware of kindly respond. Thnkx
best mexican online pharmacies mexico drug stores pharmacies mexican pharmaceuticals online
http://mexicanph.shop/# pharmacies in mexico that ship to usa
mexican mail order pharmacies
I’m extremely pleased to discover this website. I wanted to thank you for ones time just for this fantastic read!
My website: лица анальной боли
Wristwatches Universe
Customer Comments Shine light on Our Watch Boutique Adventure
At WatchesWorld, customer happiness isn’t just a target; it’s a bright evidence to our devotion to perfection. Let’s dive into what our respected patrons have to express about their adventures, illuminating on the impeccable assistance and exceptional watches we present.
O.M.’s Trustpilot Feedback: A Smooth Trip
“Very great communication and follow-up throughout the procession. The watch was flawlessly packed and in pristine. I would definitely work with this teamwork again for a timepiece acquisition.
O.M.’s declaration illustrates our loyalty to comms and meticulous care in delivering timepieces in flawless condition. The faith built with O.M. is a foundation of our customer relationships.
Richard Houtman’s Perceptive Review: A Personalized Connection
“I dealt with Benny, who was exceptionally helpful and polite at all times, keeping me regularly notified of the course. Progressing, even though I ended up sourcing the watch locally, I would still certainly recommend Benny and the enterprise moving forward.
Richard Houtman’s experience showcases our individualized approach. Benny’s assistance and uninterrupted comms demonstrate our loyalty to ensuring every buyer feels esteemed and notified.
Customer’s Effective Assistance Testimonial: A Seamless Transaction
“A very good and productive service. Kept me informed on the order development.
Our commitment to effectiveness is echoed in this customer’s input. Keeping customers updated and the uninterrupted progress of transactions are integral to the Our Watch Boutique journey.
Examine Our Current Offerings
Audemars Piguet Selfwinding Royal Oak 37mm
A stunning piece at €45,900, this 2022 edition (REF: 15551ST.ZZ.1356ST.05) invites you to add it to your cart and elevate your set.
Hublot Classic Fusion Green Titanium Chronograph 45mm
Priced at €8,590 in 2024 (REF: 521.NX.8970.RX), this Hublot creation is a combination of styling and novelty, awaiting your inquiry.
mexican pharmacy best online pharmacies in mexico mexican mail order pharmacies
Red Boost is an all-natural dietary supplement that boosts the body’s hormonal levels, blood flow, and supply of oxygen and nutrients.
https://mexicanph.com/# mexican drugstore online
purple pharmacy mexico price list
medication from mexico pharmacy mexican pharmaceuticals online medication from mexico pharmacy
mexico pharmacy mexican drugstore online medicine in mexico pharmacies
medication from mexico pharmacy purple pharmacy mexico price list п»їbest mexican online pharmacies
buying from online mexican pharmacy mexican rx online buying from online mexican pharmacy
ST666
mexico drug stores pharmacies mexico pharmacies prescription drugs mexico pharmacies prescription drugs
Защита в сети: Список переходов для Tor Browser
В наше время, когда проблемы конфиденциальности и безопасности в сети становятся все более актуальными, немало пользователи обращают внимание на аппаратные средства, позволяющие сберечь анонимность и противостояние личной информации. Один из таких инструментов – Tor Browser, разработанный на системе Tor. Однако даже при использовании Tor Browser есть опасность столкнуться с преградой или фильтрацией со стороны Интернет-поставщиков или органов цензуры.
Для обхода этих ограничений были созданы переходы для Tor Browser. Переходы – это эксклюзивные серверы, которые могут быть использованы для прохождения блокировок и обеспечения доступа к сети Tor. В представленном тексте мы рассмотрим реестр мостов, которые можно использовать с Tor Browser для обеспечения достоверной и секурной скрытности в интернете.
meek-azure: Этот мост использует облачный сервис Azure для того, чтобы замаскировать тот факт, что вы используете Tor. Это может быть важно в странах, где поставщики интернет-услуг блокируют доступ к серверам Tor.
obfs4: Переправа обфускации, предоставляющий средства для сокрытия трафика Tor. Этот переправа может эффективно обходить блокировки и цензуру, делая ваш трафик неотличимым для сторонних.
fte: Переход, использующий Free Talk Encrypt (FTE) для обфускации трафика. FTE позволяет трансформировать трафик так, чтобы он казался обычным сетевым трафиком, что делает его труднее для выявления.
snowflake: Этот подход позволяет вам использовать браузеры, которые поддерживаются расширение Snowflake, чтобы помочь другим пользователям Tor пройти через ограничения.
fte-ipv6: Вариант FTE с работающий с IPv6, который может быть полезен, если ваш провайдер интернета предоставляет IPv6-подключение.
Чтобы использовать эти переправы с Tor Browser, откройте его настройки, перейдите в раздел “Проброс мостов” и введите названия переходов, которые вы хотите использовать.
Не забывайте, что эффективность мостов может изменяться в зависимости от страны и Интернет-поставщиков. Также рекомендуется регулярно обновлять перечень подходов, чтобы быть уверенным в производительности обхода блокировок. Помните о важности защиты в интернете и принимайте меры для сохранения своей личной информации.
мосты для tor browser список
Внутри века технологий, в условиях, когда цифровые границы смешиваются с реальностью, не допускается игнорировать присутствие угроз в теневом интернете. Одной из таких угроз является blacksprut – выражение, превратившийся символом нелегальной, вредоносной деятельности в скрытых уголках интернета.
Blacksprut, будучи компонентом подпольной сети, представляет существенную угрозу для цифровой безопасности и личной устойчивости пользователей. Этот темный уголок сети иногда ассоциируется с незаконными сделками, торговлей запрещенными товарами и услугами, а также другими противозаконными деяниями.
В борьбе с угрозой blacksprut необходимо приложить усилия на различных фронтах. Одним из решающих направлений является совершенствование технологий защиты в сети. Развитие продвинутых алгоритмов и технологий анализа данных позволит выявлять и пресекать деятельность blacksprut в реальном времени.
Помимо технических мер, важна взаимодействие усилий служб безопасности на глобальном уровне. Международное сотрудничество в области деятельности защиты в сети необходимо для эффективного исключения угрозам, связанным с blacksprut. Обмен данными, выработка совместных стратегий и быстрые действия помогут ограничить воздействие этой угрозы.
Образование и разъяснение также играют существенную роль в борьбе с blacksprut. Повышение осведомленности пользователей о рисках подпольной сети и методах предупреждения становится неотъемлемой компонентом антиспампинговых мероприятий. Чем более осведомленными будут пользователи, тем меньше возможность попадания под влияние угрозы blacksprut.
В заключение, в борьбе с угрозой blacksprut необходимо скоординировать усилия как на технологическом, так и на правовом уровнях. Это проблема, предполагающий совместных усилий людей, правоохранительных органов и технологических компаний. Только совместными усилиями мы достигнем создания безопасного и устойчивого цифрового пространства для всех.
почему-тор браузер не соединяется
Торовский браузер является продвинутым инструментом для обеспечения анонимности и защиты в интернете. Однако, иногда пользователи могут встретиться с проблемами соединения. В данном материале мы осветим возможные предпосылки и выдвинем решения для исправления неполадок с подключением к Tor Browser.
Проблемы с сетью:
Решение: Оцените ваше интернет-подключение. Убедитесь, что вы соединены к вебу, и нет ли затруднений с вашим провайдером.
Блокировка Тор-инфраструктуры:
Решение: В некоторых странах или интернет-сетях Tor может быть ограничен. Примените применять переходы для прохождения блокировок. В установках Tor Browser выберите “Проброс мостов” и соблюдайте инструкциям.
Прокси-серверы и стены:
Решение: Проверка параметров установки прокси и стены. Убедитесь, что они не блокируют доступ Tor Browser к интернету. Измени те установки или временно деактивируйте прокси и стены для проверки.
Проблемы с самим программой для просмотра:
Решение: Проверьте, что у вас установлена последнее обновление Tor Browser. Иногда обновления могут преодолеть трудности с доступом. Также попробуйте переустановить приложение.
Временные сбои в Tor сети:
Решение: Выждите некоторое время и попробуйте соединиться впоследствии. Временные перебои в работе Tor могут вызываться, и те ситуации как обычно устраняются в кратчайшие сроки.
Отключение JavaScript:
Решение: Некоторые из сайты могут запрещать вход через Tor, если в вашем веб-обозревателе включен JavaScript. Попробуйте временно выключить JavaScript в настройках браузера.
Проблемы с антивирусным ПО:
Решение: Ваш антивирус или брандмауэр может ограничивать Tor Browser. Убедитесь, что у вас отсутствует ограничений для Tor в настройках вашего антивирусного приложения.
Исчерпание оперативной памяти:
Решение: Если у вас активно большое количество веб-страниц или задачи, это может призвести к исчерпанию памяти и сбоям с доступом. Закройте дополнительные вкладки браузера или перезапустите программу.
В случае, если затруднение с доступом к Tor Browser остается в силе, заинтересуйтесь за поддержкой и помощью на официальном форуме Tor. Эксперты смогут предложить дополнительную поддержку и помощь и рекомендации. Соблюдайте, что секретность и скрытность зависят от постоянного внимательного отношения к аспектам, следовательно прослеживайте нововведениями и следуйте советам сообщества Tor.
pharmacies in mexico that ship to usa mexico pharmacy buying from online mexican pharmacy
mexican mail order pharmacies medicine in mexico pharmacies mexican rx online
reputable mexican pharmacies online mexican pharmaceuticals online mexico drug stores pharmacies
Horological instruments World
Client Testimonials Highlight Timepieces Universe Journey
At WatchesWorld, customer happiness isn’t just a goal; it’s a bright proof to our dedication to excellence. Let’s plunge into what our valued buyers have to say about their adventures, revealing on the faultless service and exceptional clocks we offer.
O.M.’s Trustpilot Review: A Seamless Adventure
“Very good comms and follow through throughout the procession. The watch was perfectly packed and in pristine. I would certainly work with this team again for a timepiece acquisition.
O.M.’s testimony illustrates our dedication to contact and precise care in delivering timepieces in perfect condition. The trust forged with O.M. is a building block of our patron relations.
Richard Houtman’s Insightful Testimonial: A Personal Contact
“I dealt with Benny, who was extremely useful and polite at all times, keeping me consistently informed of the course. Going forward, even though I ended up sourcing the watch locally, I would still surely recommend Benny and the firm moving forward.
Richard Houtman’s interaction spotlights our tailored approach. Benny’s aid and constant communication display our dedication to ensuring every customer feels esteemed and updated.
Customer’s Effective Assistance Review: A Uninterrupted Transaction
“A very effective and effective service. Kept me up to date on the transaction progression.
Our devotion to effectiveness is echoed in this client’s feedback. Keeping customers informed and the uninterrupted advancement of orders are integral to the WatchesWorld adventure.
Discover Our Current Selections
Audemars Piguet Selfwinding Royal Oak 37mm
A gorgeous piece at €45,900, this 2022 edition (REF: 15551ST.ZZ.1356ST.05) invites you to add it to your cart and elevate your assortment.
Hublot Titanium Green 45mm Chrono
Priced at €8,590 in 2024 (REF: 521.NX.8970.RX), this Hublot creation is a fusion of design and novelty, awaiting your request.
A lot of blog writers nowadays yet just a few have blog posts worth spending time on reviewing.
My website: порно видео мжм
medication from mexico pharmacy mexican pharmaceuticals online buying prescription drugs in mexico online
chasemusik.com
Xu Jing이 오래 전에 바다에서 죽었다는 소식을 듣지 않았습니까?
http://mexicanph.shop/# mexican mail order pharmacies
reputable mexican pharmacies online
mexican rx online medicine in mexico pharmacies п»їbest mexican online pharmacies
I’m extremely pleased to discover this website. I wanted to thank you for ones time just for this fantastic read!
My website: как дрочить самой себе
I do like the way you have presented this concern and it does provide me personally a lot of fodder for thought. Nonetheless, coming from everything that I have observed, I just wish when the comments pile on that individuals remain on issue and not embark upon a soap box involving some other news du jour. Yet, thank you for this outstanding piece and while I do not really concur with it in totality, I respect your standpoint.
best mexican online pharmacies medicine in mexico pharmacies medication from mexico pharmacy
mexican border pharmacies shipping to usa purple pharmacy mexico price list mexican mail order pharmacies
Your writing style is so engaging and easy to follow I find myself reading through each post without even realizing I’ve reached the end
mexico pharmacy mexican pharmacy best online pharmacies in mexico
purple pharmacy mexico price list medication from mexico pharmacy pharmacies in mexico that ship to usa
My website: порно анал групповуха
buying prescription drugs in mexico online mexico drug stores pharmacies mexican pharmaceuticals online
medication from mexico pharmacy mexican rx online mexico pharmacies prescription drugs
medicine in mexico pharmacies best online pharmacies in mexico mexican pharmaceuticals online
buying prescription drugs in mexico medicine in mexico pharmacies mexican mail order pharmacies
LipoSlend is a liquid nutritional supplement that promotes healthy and steady weight loss. https://liposlendofficial.us/
mexico pharmacies prescription drugs mexico drug stores pharmacies pharmacies in mexico that ship to usa
reputable mexican pharmacies online buying prescription drugs in mexico mexican drugstore online
Definitely, what a great blog and revealing posts, I definitely will bookmark your site. Best Regards!
My website: секс с русской мамкой
best mexican online pharmacies mexican pharmaceuticals online mexican pharmaceuticals online
mexico drug stores pharmacies best online pharmacies in mexico reputable mexican pharmacies online
mexico drug stores pharmacies purple pharmacy mexico price list best mexican online pharmacies
reputable mexican pharmacies online pharmacies in mexico that ship to usa buying prescription drugs in mexico online
As a Newbie, I am continuously exploring online for articles that can be of assistance to me.
My website: девушка дрочит рукой
http://mexicanph.com/# mexico pharmacies prescription drugs
mexican drugstore online
medicine in mexico pharmacies mexico pharmacy mexican pharmacy
mexican mail order pharmacies mexico drug stores pharmacies mexican pharmaceuticals online
ST666
Good write-up, I am normal visitor of one’s website, maintain up the nice operate, and It’s going to be a regular visitor for a long time.
mexican pharmacy purple pharmacy mexico price list medicine in mexico pharmacies
mexican pharmacy medication from mexico pharmacy mexico pharmacies prescription drugs
best online pharmacies in mexico mexican pharmacy mexico pharmacy
I reckon something truly special in this website.
My website: красивое порно в чулках
mexican border pharmacies shipping to usa purple pharmacy mexico price list mexico drug stores pharmacies
mexican rx online pharmacies in mexico that ship to usa mexico pharmacies prescription drugs
mexican mail order pharmacies buying prescription drugs in mexico mexican pharmaceuticals online
mexico drug stores pharmacies mexican pharmacy medication from mexico pharmacy
http://mexicanph.shop/# best online pharmacies in mexico
mexican drugstore online
I am glad to be a visitant of this stark website! , appreciate it for this rare info ! .
buying prescription drugs in mexico online medicine in mexico pharmacies mexican rx online
mexico pharmacy reputable mexican pharmacies online mexico pharmacies prescription drugs
mexico drug stores pharmacies mexican border pharmacies shipping to usa mexican mail order pharmacies
Muchos Gracias for your article.Really thank you! Cool.
My website: жесткий анилингус
mexican border pharmacies shipping to usa mexican rx online mexican drugstore online
mexican online pharmacies prescription drugs mexico pharmacies prescription drugs medicine in mexico pharmacies
I gotta favorite this site it seems very beneficial handy
My website: фемдом бесплатно
mexico pharmacies prescription drugs mexican rx online mexican mail order pharmacies
best online pharmacies in mexico pharmacies in mexico that ship to usa pharmacies in mexico that ship to usa
reputable mexican pharmacies online mexican mail order pharmacies mexican drugstore online
purple pharmacy mexico price list medication from mexico pharmacy mexican pharmaceuticals online
http://mexicanph.com/# reputable mexican pharmacies online
mexican mail order pharmacies
saungsantoso.com
말은 코를 골고 고통스러워 보였고 즉시 울부 짖고 질주하기 시작했습니다.
mexico pharmacies prescription drugs best online pharmacies in mexico mexican mail order pharmacies
buying prescription drugs in mexico best online pharmacies in mexico mexico pharmacies prescription drugs
mexican drugstore online buying from online mexican pharmacy best online pharmacies in mexico
I got what you intend,bookmarked, very decent website.
My website: Первый анал
mexican mail order pharmacies pharmacies in mexico that ship to usa buying prescription drugs in mexico online
mexico drug stores pharmacies medicine in mexico pharmacies mexican drugstore online
buying from online mexican pharmacy mexico pharmacy medication from mexico pharmacy
I love your blog.. very nice colors & theme. Did you create this website yourself? Plz reply back as I’m looking to create my own blog and would like to know wheere u got this from. thanks
mexican border pharmacies shipping to usa mexican pharmacy buying from online mexican pharmacy
best mexican online pharmacies mexican online pharmacies prescription drugs mexican online pharmacies prescription drugs
I gotta favorite this site it seems very beneficial handy
My website: секс арабская девушка
https://mexicanph.shop/# mexico drug stores pharmacies
mexican border pharmacies shipping to usa
mexican drugstore online purple pharmacy mexico price list mexico drug stores pharmacies
medicine in mexico pharmacies pharmacies in mexico that ship to usa best online pharmacies in mexico
https://furosemide.guru/# furosemide 100mg
lasix 40 mg: Buy Lasix – lasix 100 mg
https://stromectol.fun/# ivermectin purchase
lisinopril 10 12.55mg order lisinopril online us lisinopril sale
I’ve read several good stuff here. Certainly worth bookmarking for revisiting. I surprise how much effort you put to create such a wonderful informative website.
http://lisinopril.top/# lisinopril from mexico
https://amoxil.cheap/# buy amoxicillin over the counter uk
furosemide: Buy Lasix – lasix medication
lasix 100mg Buy Furosemide lasix for sale
https://furosemide.guru/# lasix furosemide 40 mg
lasix dosage: Over The Counter Lasix – lasix 40 mg
I do enjoy the way you have presented this particular issue and it does give us a lot of fodder for thought. On the other hand, because of just what I have witnessed, I simply just hope when the remarks pile on that people keep on point and not embark on a tirade associated with the news of the day. Yet, thank you for this fantastic point and while I do not go along with the idea in totality, I regard your standpoint.
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
https://stromectol.fun/# buy stromectol canada
台灣線上娛樂城的規模正迅速增長,新的娛樂場所不斷開張。為了吸引玩家,這些場所提供了各種吸引人的優惠和贈品。每家娛樂城都致力於提供卓越的服務,務求讓客人享受最佳的遊戲體驗。
2024年網友推薦最多的線上娛樂城:No.1富遊娛樂城、No.2 BET365、No.3 DG娛樂城、No.4 九州娛樂城、No.5 亞博娛樂城,以下來介紹這幾間娛樂城網友對他們的真實評價及娛樂城推薦。
2024台灣娛樂城排名
排名 娛樂城 體驗金(流水) 首儲優惠(流水) 入金速度 出金速度 推薦指數
1 富遊娛樂城 168元(1倍) 送1000(1倍) 15秒 3-5分鐘 ★★★★★
2 1XBET中文版 168元(1倍) 送1000(1倍) 15秒 3-5分鐘 ★★★★☆
3 Bet365中文 168元(1倍) 送1000(1倍) 15秒 3-5分鐘 ★★★★☆
4 DG娛樂城 168元(1倍) 送1000(1倍) 15秒 5-10分鐘 ★★★★☆
5 九州娛樂城 168元(1倍) 送500(1倍) 15秒 5-10分鐘 ★★★★☆
6 亞博娛樂城 168元(1倍) 送1000(1倍) 15秒 3-10分鐘 ★★★☆☆
7 寶格綠娛樂城 199元(1倍) 送1000(25倍) 15秒 3-5分鐘 ★★★☆☆
8 王者娛樂城 300元(15倍) 送1000(15倍) 90秒 5-30分鐘 ★★★☆☆
9 FA8娛樂城 200元(40倍) 送1000(15倍) 90秒 5-10分鐘 ★★★☆☆
10 AF娛樂城 288元(40倍) 送1000(1倍) 60秒 5-30分鐘 ★★★☆☆
2024台灣娛樂城排名,10間娛樂城推薦
No.1 富遊娛樂城
富遊娛樂城推薦指數:★★★★★(5/5)
富遊娛樂城介面 / 2024娛樂城NO.1
RG富遊官網
富遊娛樂城是成立於2019年的一家獲得數百萬玩家註冊的線上博彩品牌,持有博彩行業市場的合法運營許可。該公司受到歐洲馬爾他(MGA)、菲律賓(PAGCOR)以及英屬維爾京群島(BVI)的授權和監管,展示了其雄厚的企業實力與合法性。
富遊娛樂城致力於提供豐富多樣的遊戲選項和全天候的會員服務,不斷追求卓越,確保遊戲的公平性。公司運用先進的加密技術及嚴格的安全管理體系,保障玩家資金的安全。此外,為了提升手機用戶的使用體驗,富遊娛樂城還開發了專屬APP,兼容安卓(Android)及IOS系統,以達到業界最佳的穩定性水平。
在資金存提方面,富遊娛樂城採用第三方金流服務,進一步保障玩家的資金安全,贏得了玩家的信賴與支持。這使得每位玩家都能在此放心享受遊戲樂趣,無需擔心後顧之憂。
富遊娛樂城簡介
娛樂城網路評價:5分
娛樂城入金速度:15秒
娛樂城出金速度:5分鐘
娛樂城體驗金:168元
娛樂城優惠:
首儲1000送1000
好友禮金無上限
新會禮遇
舊會員回饋
娛樂城遊戲:體育、真人、電競、彩票、電子、棋牌、捕魚
富遊娛樂城推薦要點
新手首推:富遊娛樂城,2024受網友好評,除了打造針對新手的各種優惠活動,還有各種遊戲的豐富教學。
首儲再贈送:首儲1000元,立即在獲得1000元獎金,而且只需要1倍流水,對新手而言相當友好。
免費遊戲體驗:新進玩家享有免費體驗金,讓您暢玩娛樂城內的任何遊戲。
優惠多元:活動頻繁且豐富,流水要求低,對各玩家可說是相當友善。
玩家首選:遊戲多樣,服務優質,是新手與老手的最佳賭場選擇。
富遊娛樂城優缺點整合
優點 缺點
• 台灣註冊人數NO.1線上賭場
• 首儲1000贈1000只需一倍流水
• 擁有體驗金免費體驗賭場
• 網紅部落客推薦保證出金線上娛樂城 • 需透過客服申請體驗金
富遊娛樂城優缺點整合表格
富遊娛樂城存取款方式
存款方式 取款方式
• 提供四大超商(全家、7-11、萊爾富、ok超商)
• 虛擬貨幣ustd存款
• 銀行轉帳(各大銀行皆可) • 現金1:1出金
• 網站內申請提款及可匯款至綁定帳戶
富遊娛樂城存取款方式表格
富遊娛樂城優惠活動
優惠 獎金贈點 流水要求
免費體驗金 $168 1倍 (儲值後) /36倍 (未儲值)
首儲贈點 $1000 1倍流水
返水活動 0.3% – 0.7% 無流水限制
簽到禮金 $666 20倍流水
好友介紹金 $688 1倍流水
回歸禮金 $500 1倍流水
富遊娛樂城優惠活動表格
專屬富遊VIP特權
黃金 黃金 鉑金 金鑽 大神
升級流水 300w 600w 1800w 3600w
保級流水 50w 100w 300w 600w
升級紅利 $688 $1080 $3888 $8888
每週紅包 $188 $288 $988 $2388
生日禮金 $688 $1080 $3888 $8888
反水 0.4% 0.5% 0.6% 0.7%
專屬富遊VIP特權表格
娛樂城評價
總體來看,富遊娛樂城對於玩家來講是一個非常不錯的選擇,有眾多的遊戲能讓玩家做選擇,還有各種優惠活動以及低流水要求等等,都讓玩家贏錢的機率大大的提升了不少,除了體驗遊戲中帶來的樂趣外還可以享受到贏錢的快感,還在等什麼趕快點擊下方連結,立即遊玩!
オンラインカジノ
日本にオンラインカジノおすすめランキング2024年最新版
2024おすすめのオンラインカジノ
オンラインカジノはパソコンでしか遊べないというのは、もう一昔前の話。現在はスマホやタブレットなどのモバイル端末からも、パソコンと変わらないクオリティでオンラインカジノを当たり前に楽しむことができるようになりました。
数あるモバイルカジノの中で、当サイトが厳選したトップ5カジノはこちら。
オンラインカジノおすすめ: コニベット(Konibet)
コニベットといえば、キャッシュバックや毎日もらえるリベートボーナスなど豪華ボーナスが満載!それに加えて低い出金条件も見どころです。さらにVIPレベルごとの還元率の高さも業界内で突出している点や、出金速度の速さなどトータルバランスの良さからもハイローラーの方にも好まれています。
カスタマーサポートは365日24時間稼働しているので、初心者の方にも安心してご利用いただけます。
さらに【業界初のオンラインポーカー】を導入!毎日トーナメントも開催されているので、早速参加しちゃいましょう!
RTP(還元率)公開や、入出金対応がスムーズで初心者向き
2000種類以上の豊富なゲーム数を誇り、スロットゲーム多数!
今なら$20の入金不要ボーナスと最大$650還元ボーナス!
8種類以上のライブカジノプロバイダー
業界初オンラインポーカーあり,日本利用者数No.1の安心のオンラインカジノメディア!
おすすめポイント
コニベットは、その豊富なボーナスと高還元率、そして安心のキャッシュバック制度で知られています。まず、新規登録者には入金不要の$20ボーナスが提供され、さらに初回入金時には最大$650の還元ボーナスが得られます。これらのキャンペーンはプレイヤーにとって大きな魅力となっています。
また、コニベットの特徴的な点は、VIP制度です。一度ロイヤルクラブになると、降格がなく、スロットリベートが1.5%という驚異の還元率を享受できます。これは他のオンラインカジノと比較しても非常に高い還元率です。さらに、常時週間損失キャッシュバックも行っているため、不運で負けてしまった場合でも取り返すチャンスがあります。これらの特徴から、コニベットはプレイヤーにとって非常に魅力的なオンラインカジノと言えるでしょう。
コニベット 無料会員登録をする
| コニベットのボーナス
コニベットは、新規登録者向けに20ドルの入金不要ボーナスを用意しています
コニベットカジノでは、限定で初回入金後に残高が1ドル未満になった場合、入金額の50%(最高500ドル)がキャッシュバックされる。キャッシュバック額に出金条件はないため、獲得後にすぐ出金することも可能です。
| コニベットの入金方法
入金方法 最低 / 最高入金
マスターカード 最低 : $20 / 最高 : $6,000
ジェイシービー 最低 : $20/ 最高 : $6,000
アメックス 最低 : $20 / 最高 : $6,000
アイウォレット 最低 : $20 / 最高 : $100,000
スティックペイ 最低 : $20 / 最高 : $100,000
ヴィーナスポイント 最低 : $20 / 最高 : $10,000
仮想通貨 最低 : $20 / 最高 : $100,000
銀行送金 最低 : $20 / 最高 : $10,000
| コニベット出金方法
出金方法 最低 |最高出金
アイウォレット 最低 : $40 / 最高 : なし
スティックぺイ 最低 : $40 / 最高 : なし
ヴィーナスポイント 最低 : $40 / 最高 : なし
仮想通貨 最低 : $40 / 最高 : なし
銀行送金 最低 : $40 / 最高 : なし
Very good post.Really looking forward to read more. Great.
My website: кончил на ноги
prednisone 20mg buy online: prednisone tabs 20 mg – prednisone cost us
https://lisinopril.top/# lisinopril mexico
http://furosemide.guru/# lasix furosemide
What’s Happening i am new to this, I stumbled upon this I have found It absolutely useful and it has helped me out loads. I hope to contribute & assist other users like its helped me. Good job.
https://furosemide.guru/# buy furosemide online
Wohh precisely what I was searching for, regards for putting up.
My website: жена сосет хуй
buy amoxicillin online mexico amoxicillin 500 mg for sale amoxicillin 500mg price in canada
amoxicillin azithromycin: can you buy amoxicillin over the counter in canada – order amoxicillin online
According to Our Lawyers Fairfax VA Divorce, it’s critical to have a realistic understanding of the family’s financial situation before moving forward with the divorce. You can gain a better understanding of the funding source for each asset by carefully going over your bank statements from the last few years. Engage knowledgeable Lawyers Fairfax VA Divorce if you are unable to reach a clear decision.
http://amoxil.cheap/# amoxicillin 500mg prescription
how to get amoxicillin: amoxicillin 500 capsule – generic amoxil 500 mg
http://lisinopril.top/# lisinopril 1 mg tablet
日本にオンラインカジノおすすめランキング2024年最新版
2024おすすめのオンラインカジノ
オンラインカジノはパソコンでしか遊べないというのは、もう一昔前の話。現在はスマホやタブレットなどのモバイル端末からも、パソコンと変わらないクオリティでオンラインカジノを当たり前に楽しむことができるようになりました。
数あるモバイルカジノの中で、当サイトが厳選したトップ5カジノはこちら。
オンラインカジノおすすめ: コニベット(Konibet)
コニベットといえば、キャッシュバックや毎日もらえるリベートボーナスなど豪華ボーナスが満載!それに加えて低い出金条件も見どころです。さらにVIPレベルごとの還元率の高さも業界内で突出している点や、出金速度の速さなどトータルバランスの良さからもハイローラーの方にも好まれています。
カスタマーサポートは365日24時間稼働しているので、初心者の方にも安心してご利用いただけます。
さらに【業界初のオンラインポーカー】を導入!毎日トーナメントも開催されているので、早速参加しちゃいましょう!
RTP(還元率)公開や、入出金対応がスムーズで初心者向き
2000種類以上の豊富なゲーム数を誇り、スロットゲーム多数!
今なら$20の入金不要ボーナスと最大$650還元ボーナス!
8種類以上のライブカジノプロバイダー
業界初オンラインポーカーあり,日本利用者数No.1の安心のオンラインカジノメディア!
おすすめポイント
コニベットは、その豊富なボーナスと高還元率、そして安心のキャッシュバック制度で知られています。まず、新規登録者には入金不要の$20ボーナスが提供され、さらに初回入金時には最大$650の還元ボーナスが得られます。これらのキャンペーンはプレイヤーにとって大きな魅力となっています。
また、コニベットの特徴的な点は、VIP制度です。一度ロイヤルクラブになると、降格がなく、スロットリベートが1.5%という驚異の還元率を享受できます。これは他のオンラインカジノと比較しても非常に高い還元率です。さらに、常時週間損失キャッシュバックも行っているため、不運で負けてしまった場合でも取り返すチャンスがあります。これらの特徴から、コニベットはプレイヤーにとって非常に魅力的なオンラインカジノと言えるでしょう。
コニベット 無料会員登録をする
| コニベットのボーナス
コニベットは、新規登録者向けに20ドルの入金不要ボーナスを用意しています
コニベットカジノでは、限定で初回入金後に残高が1ドル未満になった場合、入金額の50%(最高500ドル)がキャッシュバックされる。キャッシュバック額に出金条件はないため、獲得後にすぐ出金することも可能です。
| コニベットの入金方法
入金方法 最低 / 最高入金
マスターカード 最低 : $20 / 最高 : $6,000
ジェイシービー 最低 : $20/ 最高 : $6,000
アメックス 最低 : $20 / 最高 : $6,000
アイウォレット 最低 : $20 / 最高 : $100,000
スティックペイ 最低 : $20 / 最高 : $100,000
ヴィーナスポイント 最低 : $20 / 最高 : $10,000
仮想通貨 最低 : $20 / 最高 : $100,000
銀行送金 最低 : $20 / 最高 : $10,000
| コニベット出金方法
出金方法 最低 |最高出金
アイウォレット 最低 : $40 / 最高 : なし
スティックぺイ 最低 : $40 / 最高 : なし
ヴィーナスポイント 最低 : $40 / 最高 : なし
仮想通貨 最低 : $40 / 最高 : なし
銀行送金 最低 : $40 / 最高 : なし
lasix dosage: lasix 100mg – furosemide 40 mg
http://lisinopril.top/# lisinopril 20 mg price in india
日本にオンラインカジノおすすめランキング2024年最新版
2024おすすめのオンラインカジノ
オンラインカジノはパソコンでしか遊べないというのは、もう一昔前の話。現在はスマホやタブレットなどのモバイル端末からも、パソコンと変わらないクオリティでオンラインカジノを当たり前に楽しむことができるようになりました。
数あるモバイルカジノの中で、当サイトが厳選したトップ5カジノはこちら。
オンラインカジノおすすめ: コニベット(Konibet)
コニベットといえば、キャッシュバックや毎日もらえるリベートボーナスなど豪華ボーナスが満載!それに加えて低い出金条件も見どころです。さらにVIPレベルごとの還元率の高さも業界内で突出している点や、出金速度の速さなどトータルバランスの良さからもハイローラーの方にも好まれています。
カスタマーサポートは365日24時間稼働しているので、初心者の方にも安心してご利用いただけます。
さらに【業界初のオンラインポーカー】を導入!毎日トーナメントも開催されているので、早速参加しちゃいましょう!
RTP(還元率)公開や、入出金対応がスムーズで初心者向き
2000種類以上の豊富なゲーム数を誇り、スロットゲーム多数!
今なら$20の入金不要ボーナスと最大$650還元ボーナス!
8種類以上のライブカジノプロバイダー
業界初オンラインポーカーあり,日本利用者数No.1の安心のオンラインカジノメディア!
おすすめポイント
コニベットは、その豊富なボーナスと高還元率、そして安心のキャッシュバック制度で知られています。まず、新規登録者には入金不要の$20ボーナスが提供され、さらに初回入金時には最大$650の還元ボーナスが得られます。これらのキャンペーンはプレイヤーにとって大きな魅力となっています。
また、コニベットの特徴的な点は、VIP制度です。一度ロイヤルクラブになると、降格がなく、スロットリベートが1.5%という驚異の還元率を享受できます。これは他のオンラインカジノと比較しても非常に高い還元率です。さらに、常時週間損失キャッシュバックも行っているため、不運で負けてしまった場合でも取り返すチャンスがあります。これらの特徴から、コニベットはプレイヤーにとって非常に魅力的なオンラインカジノと言えるでしょう。
コニベット 無料会員登録をする
| コニベットのボーナス
コニベットは、新規登録者向けに20ドルの入金不要ボーナスを用意しています
コニベットカジノでは、限定で初回入金後に残高が1ドル未満になった場合、入金額の50%(最高500ドル)がキャッシュバックされる。キャッシュバック額に出金条件はないため、獲得後にすぐ出金することも可能です。
| コニベットの入金方法
入金方法 最低 / 最高入金
マスターカード 最低 : $20 / 最高 : $6,000
ジェイシービー 最低 : $20/ 最高 : $6,000
アメックス 最低 : $20 / 最高 : $6,000
アイウォレット 最低 : $20 / 最高 : $100,000
スティックペイ 最低 : $20 / 最高 : $100,000
ヴィーナスポイント 最低 : $20 / 最高 : $10,000
仮想通貨 最低 : $20 / 最高 : $100,000
銀行送金 最低 : $20 / 最高 : $10,000
| コニベット出金方法
出金方法 最低 |最高出金
アイウォレット 最低 : $40 / 最高 : なし
スティックぺイ 最低 : $40 / 最高 : なし
ヴィーナスポイント 最低 : $40 / 最高 : なし
仮想通貨 最低 : $40 / 最高 : なし
銀行送金 最低 : $40 / 最高 : なし
https://buyprednisone.store/# prednisone cream rx
lasix 100mg: Buy Lasix – lasix for sale
https://lisinopril.top/# lisinopril 2.5
http://buyprednisone.store/# prednisone coupon
lasix for sale: furosemida 40 mg – lasix pills
stromectol ebay ivermectin 6 tablet order stromectol
https://buyprednisone.store/# buy prednisone 10mg online
hihouse420.com
Fang Jifan은 분노를 참으며 화를 내며 말했습니다. “폐하, 연왕은 당신의 조상입니다.”
prescription prednisone cost: online prednisone 5mg – prednisone pills 10 mg
http://furosemide.guru/# lasix tablet
https://amoxil.cheap/# amoxicillin online purchase
lasix 40mg: lasix for sale – lasix pills
stromectol tablets uk ivermectin uk ivermectin 80 mg
http://amoxil.cheap/# amoxicillin 500mg buy online uk
Теневые рынки и их незаконные деятельности представляют значительную угрозу безопасности общества и являются объектом внимания правоохранительных органов по всему миру. В данной статье мы обсудим так называемые теневые рынки, где возможно покупать фальшивые паспорта, и какие угрозы это несет для граждан и государства.
Теневые рынки представляют собой неявные интернет-площадки, на которых торгуется разнообразной противозаконной продукцией и услугами. Среди этих услуг встречается и продажа фальшивых документов, таких как личные документы. Эти рынки оперируют в неофициальной сфере интернета, используя шифрование и скрытые платежные системы, чтобы оставаться непостижимыми для правоохранительных органов.
Покупка фальшивого паспорта на теневых рынках представляет существенную угрозу национальной безопасности. незаконное завладение личных данных, изготовление фальшивых документов и фальшивые идентификационные материалы могут быть использованы для совершения радикальных актов, обманного характера и прочих преступлений.
Правоохранительные органы в различных странах активно борются с скрытыми рынками, проводя акции по выявлению и задержанию тех, кто замешан в противозаконных операциях. Однако, по мере того как технологии становятся более затруднительными, эти рынки могут приспосабливаться и находить новые методы обхода законов.
Для предотвращения угроз от угроз, связанных с теневыми рынками, важно соблюдать осторожность при обработке своих индивидуальных данных. Это включает в себя избегать попыток фишинга, не раскрывать персональной информацией в недоверенных источниках и регулярно контролировать свои финансовую отчетность.
Кроме того, общество должно быть информировано о рисках и последствиях покупки нелегальных документов. Это способствует созданию более осознанного и ответственного отношения к вопросам безопасности и поможет в борьбе с теневыми рынками. Поддержка законопроектов, направленных на ужесточение наказаний за создание и продажу поддельных документов, также представляет важное направление в борьбе с этими преступлениями
sm-slot.com
그리고 이 모든 것은 사실 조국개혁에 대한 비밀 논의가 유출된 것과 관련이 있습니다.
prednisone pack: prednisone brand name in usa – prednisone 5443
http://stromectol.fun/# how much is ivermectin
There are some interesting deadlines on this article but I don’t know if I see all of them heart to heart. There may be some validity however I will take maintain opinion until I look into it further. Good article , thanks and we wish more! Added to FeedBurner as effectively
http://stromectol.fun/# stromectol ivermectin
網上賭場
prednisone 10mg tablets: prednisone 2.5 mg – how can i get prednisone
The question of whether personal values are innate or shaped by external factors is a complex and debated topic in psychology, philosophy, and sociology. Here’s an exploration of both perspectives:
Изготовление и использование дубликатов банковских карт является неправомерной практикой, представляющей важную угрозу для безопасности финансовых систем и личных средств граждан. В данной статье мы рассмотрим потенциальные опасности и последствия покупки дубликатов карт, а также как общество и правоохранительные органы борются с аналогичными преступлениями.
“Копии” карт — это поддельные дубликаты банковских карт, которые используются для неправомерных транзакций. Основной метод создания дубликатов — это хищение данных с оригинальной карты и последующее настройка этих данных на другую карту. Злоумышленники, предлагающие услуги по продаже реплик карт, обычно действуют в теневой сфере интернета, где трудно выявить и пресечь их деятельность.
Покупка реплик карт представляет собой существенное преступление, которое может повлечь за собой серьезные наказания. Покупатель также рискует стать участником мошенничества, что может привести к судебному преследованию. Основные преступные действия в этой сфере включают в себя кражу личной информации, фальсификацию документов и, конечно же, экономические махинации.
Банки и органы порядка активно борются с правонарушениями, связанными с копированием карт. Банки внедряют современные технологии для распознавания подозрительных транзакций, а также предлагают услуги по безопасности для своих клиентов. Полиция ведут следственные мероприятия и ловят тех, кто замешан в создании и реализации копий карт.
Для противодействия угрозам важно соблюдать внимание при использовании банковских карт. Необходимо регулярно контролировать выписки, избегать недоверительных сделок и следить за своей индивидуальной информацией. Знание и информированность об угрозах также являются ключевыми средствами в борьбе с финансовыми махинациями.
В заключение, использование дубликатов банковских карт — это незаконное и неприемлемое деяние, которое может привести к тяжким последствиям для тех, кто вовлечен в такую практику. Соблюдение мер предосторожности, осведомленность о возможных опасностях и сотрудничество с силовыми структурами играют определяющую роль в предотвращении и пресечении таких преступлений
http://lisinopril.top/# lisinopril 30 mg tablet
lasix: lasix 100 mg tablet – furosemida
https://furosemide.guru/# buy furosemide online
lasix 100 mg Buy Lasix lasix medication
My spouse and i have been cheerful when Louis managed to carry out his investigations while using the ideas he made using your blog. It is now and again perplexing to just find yourself releasing ideas that many people today could have been making money from. And we all keep in mind we need the blog owner to give thanks to because of that. These explanations you made, the easy web site navigation, the relationships you make it easier to instill – it’s got many remarkable, and it is aiding our son and our family consider that the idea is enjoyable, and that is extremely fundamental. Thank you for the whole thing!
online platform for watches
In the world of high-end watches, locating a dependable source is crucial, and WatchesWorld stands out as a pillar of confidence and expertise. Providing an wide collection of esteemed timepieces, WatchesWorld has collected acclaim from happy customers worldwide. Let’s delve into what our customers are saying about their encounters.
Customer Testimonials:
O.M.’s Review on O.M.:
“Very good communication and follow-up throughout the process. The watch was flawlessly packed and in perfect condition. I would certainly work with this group again for a watch purchase.”
Richard Houtman’s Review on Benny:
“I dealt with Benny, who was highly assisting and courteous at all times, preserving me regularly informed of the procedure. Moving forward, even though I ended up sourcing the watch locally, I would still definitely recommend Benny and the company.”
Customer’s Efficient Service Experience:
“A very good and prompt service. Kept me up to date on the order progress.”
Featured Timepieces:
Richard Mille RM30-01 Automatic Winding with Declutchable Rotor:
Price: €285,000
Year: 2023
Reference: RM30-01 TI
Patek Philippe Complications World Time 38.5mm:
Price: €39,900
Year: 2019
Reference: 5230R-001
Rolex Oyster Perpetual Day-Date 36mm:
Price: €76,900
Year: 2024
Reference: 128238-0071
Best Sellers:
Bulgari Serpenti Tubogas 35mm:
Price: On Request
Reference: 101816 SP35C6SDS.1T
Bulgari Serpenti Tubogas 35mm (2024):
Price: €12,700
Reference: 102237 SP35C6SPGD.1T
Cartier Panthere Medium Model:
Price: €8,390
Year: 2023
Reference: W2PN0007
Our Experts Selection:
Cartier Panthere Small Model:
Price: €11,500
Year: 2024
Reference: W3PN0006
Omega Speedmaster Moonwatch 44.25 mm:
Price: €9,190
Year: 2024
Reference: 304.30.44.52.01.001
Rolex Oyster Perpetual Cosmograph Daytona 40mm:
Price: €28,500
Year: 2023
Reference: 116500LN-0002
Rolex Oyster Perpetual 36mm:
Price: €13,600
Year: 2023
Reference: 126000-0006
Why WatchesWorld:
WatchesWorld is not just an internet platform; it’s a commitment to customized service in the world of luxury watches. Our group of watch experts prioritizes trust, ensuring that every customer makes an informed decision.
Our Commitment:
Expertise: Our group brings exceptional understanding and perspective into the world of luxury timepieces.
Trust: Confidence is the foundation of our service, and we prioritize transparency in every transaction.
Satisfaction: Customer satisfaction is our paramount goal, and we go the extra mile to ensure it.
When you choose WatchesWorld, you’re not just buying a watch; you’re investing in a effortless and trustworthy experience. Explore our range, and let us assist you in finding the perfect timepiece that mirrors your style and elegance. At WatchesWorld, your satisfaction is our time-tested commitment
ivermectin 3mg for lice: stromectol 6 mg dosage – Buy Online Ivermectin/Stromectol Now
http://amoxil.cheap/# amoxicillin order online no prescription
Magnificent items from you, man. I have take into accout your stuff prior to and you are just extremely wonderful. I really like what you have bought right here, really like what you are saying and the way in which during which you assert it. You make it entertaining and you continue to take care of to keep it wise. I can’t wait to read much more from you. That is really a wonderful web site.
https://buyprednisone.store/# prednisone 5mg daily
Использование финансовых карт является существенной составляющей современного общества. Карты предоставляют удобство, надежность и множество опций для проведения финансовых сделок. Однако, кроме дозволенного использования, существует темная сторона — кэшаут карт, когда карты используются для снятия денег без одобрения владельца. Это является незаконным действием и влечет за собой серьезные наказания.
Обналичивание карт представляет собой манипуляции, направленные на извлечение наличных средств с банковской карты, необходимые для того, чтобы обойти систему защиты и уведомлений, предусмотренных банком. К сожалению, такие противозаконные поступки существуют, и они могут привести к финансовым потерям для банков и клиентов.
Одним из способов вывода наличных средств является использование технических хитростей, таких как магнитный обман. Скимминг — это способ, при котором мошенники устанавливают устройства на банкоматах или терминалах оплаты, чтобы сканировать информацию с магнитной полосы банковской карты. Полученные данные затем используются для изготовления дубликата карты или проведения транзакций в интернете.
Другим распространенным методом является мошенничество, когда мошенники отправляют фальшивые электронные сообщения или создают фейковые сайты, имитирующие банковские ресурсы, с целью доступа к конфиденциальным данным от клиентов.
Для противостояния выводу наличных средств банки вводят разнообразные меры. Это включает в себя повышение уровня безопасности, введение двухэтапной проверки, мониторинг транзакций и просвещение пользователей о техниках предотвращения мошенничества.
Клиентам также следует быть активными в гарантировании защиты своих карт и данных. Это включает в себя регулярное изменение паролей, контроль банковских выписок, а также внимательное отношение к подозрительным транзакциям.
Кэшаут карт — это опасное преступление, которое влечет за собой вред не только финансовым учреждениям, но и всему обществу. Поэтому важно соблюдать осторожность при использовании банковских карт, быть знакомым с методами предупреждения мошенничества и соблюдать профилактические меры для предотвращения утраты средств
prednisone in uk: prednisone 20mg online without prescription – 400 mg prednisone
lfchungary.com
자(子)의 때, 새해, 홍지(洪志) 12년이 시작되었다.
http://furosemide.guru/# lasix
antibiotic amoxicillin: amoxicillin where to get – amoxicillin order online no prescription
https://buyprednisone.store/# prednisone 20mg tablets where to buy
lisinopril 10 india lisinopril 18 mg lisinopril 3.5 mg
http://lisinopril.top/# prinivil brand name
https://furosemide.guru/# lasix medication
http://furosemide.guru/# lasix side effects
Watches World
In the world of luxury watches, discovering a dependable source is paramount, and WatchesWorld stands out as a pillar of trust and knowledge. Offering an wide collection of renowned timepieces, WatchesWorld has collected praise from happy customers worldwide. Let’s delve into what our customers are saying about their encounters.
Customer Testimonials:
O.M.’s Review on O.M.:
“Very good communication and follow-up throughout the procedure. The watch was impeccably packed and in pristine condition. I would certainly work with this team again for a watch purchase.”
Richard Houtman’s Review on Benny:
“I dealt with Benny, who was highly supportive and courteous at all times, maintaining me regularly informed of the process. Moving forward, even though I ended up sourcing the watch locally, I would still definitely recommend Benny and the company.”
Customer’s Efficient Service Experience:
“A very good and prompt service. Kept me up to date on the order progress.”
Featured Timepieces:
Richard Mille RM30-01 Automatic Winding with Declutchable Rotor:
Price: €285,000
Year: 2023
Reference: RM30-01 TI
Patek Philippe Complications World Time 38.5mm:
Price: €39,900
Year: 2019
Reference: 5230R-001
Rolex Oyster Perpetual Day-Date 36mm:
Price: €76,900
Year: 2024
Reference: 128238-0071
Best Sellers:
Bulgari Serpenti Tubogas 35mm:
Price: On Request
Reference: 101816 SP35C6SDS.1T
Bulgari Serpenti Tubogas 35mm (2024):
Price: €12,700
Reference: 102237 SP35C6SPGD.1T
Cartier Panthere Medium Model:
Price: €8,390
Year: 2023
Reference: W2PN0007
Our Experts Selection:
Cartier Panthere Small Model:
Price: €11,500
Year: 2024
Reference: W3PN0006
Omega Speedmaster Moonwatch 44.25 mm:
Price: €9,190
Year: 2024
Reference: 304.30.44.52.01.001
Rolex Oyster Perpetual Cosmograph Daytona 40mm:
Price: €28,500
Year: 2023
Reference: 116500LN-0002
Rolex Oyster Perpetual 36mm:
Price: €13,600
Year: 2023
Reference: 126000-0006
Why WatchesWorld:
WatchesWorld is not just an internet platform; it’s a promise to customized service in the realm of high-end watches. Our team of watch experts prioritizes trust, ensuring that every customer makes an knowledgeable decision.
Our Commitment:
Expertise: Our group brings unparalleled knowledge and perspective into the realm of high-end timepieces.
Trust: Confidence is the foundation of our service, and we prioritize transparency in every transaction.
Satisfaction: Client satisfaction is our ultimate goal, and we go the additional step to ensure it.
When you choose WatchesWorld, you’re not just buying a watch; you’re committing in a seamless and reliable experience. Explore our range, and let us assist you in discovering the ideal timepiece that mirrors your taste and sophistication. At WatchesWorld, your satisfaction is our proven commitment
lisinopril 20 mg uk: lisinopril 12.5 mg – order lisinopril
Tonic Greens is an all-in-one dietary supplement that has been meticulously designed to improve overall health and mental wellness.
Bazopril is a blood pressure supplement featuring a blend of natural ingredients to support heart health
http://stromectol.fun/# ivermectin 9mg
generic name for ivermectin: ivermectin price uk – stromectol order online
https://buyprednisone.store/# can i purchase prednisone without a prescription
http://stromectol.fun/# ivermectin 4
Watches World
In the realm of premium watches, locating a dependable source is essential, and WatchesWorld stands out as a pillar of confidence and knowledge. Providing an extensive collection of prestigious timepieces, WatchesWorld has accumulated praise from satisfied customers worldwide. Let’s dive into what our customers are saying about their experiences.
Customer Testimonials:
O.M.’s Review on O.M.:
“Very good communication and aftercare throughout the process. The watch was impeccably packed and in mint condition. I would certainly work with this group again for a watch purchase.”
Richard Houtman’s Review on Benny:
“I dealt with Benny, who was highly supportive and courteous at all times, preserving me regularly informed of the process. Moving forward, even though I ended up sourcing the watch locally, I would still definitely recommend Benny and the company.”
Customer’s Efficient Service Experience:
“A very good and prompt service. Kept me up to date on the order progress.”
Featured Timepieces:
Richard Mille RM30-01 Automatic Winding with Declutchable Rotor:
Price: €285,000
Year: 2023
Reference: RM30-01 TI
Patek Philippe Complications World Time 38.5mm:
Price: €39,900
Year: 2019
Reference: 5230R-001
Rolex Oyster Perpetual Day-Date 36mm:
Price: €76,900
Year: 2024
Reference: 128238-0071
Best Sellers:
Bulgari Serpenti Tubogas 35mm:
Price: On Request
Reference: 101816 SP35C6SDS.1T
Bulgari Serpenti Tubogas 35mm (2024):
Price: €12,700
Reference: 102237 SP35C6SPGD.1T
Cartier Panthere Medium Model:
Price: €8,390
Year: 2023
Reference: W2PN0007
Our Experts Selection:
Cartier Panthere Small Model:
Price: €11,500
Year: 2024
Reference: W3PN0006
Omega Speedmaster Moonwatch 44.25 mm:
Price: €9,190
Year: 2024
Reference: 304.30.44.52.01.001
Rolex Oyster Perpetual Cosmograph Daytona 40mm:
Price: €28,500
Year: 2023
Reference: 116500LN-0002
Rolex Oyster Perpetual 36mm:
Price: €13,600
Year: 2023
Reference: 126000-0006
Why WatchesWorld:
WatchesWorld is not just an web-based platform; it’s a promise to individualized service in the world of high-end watches. Our team of watch experts prioritizes trust, ensuring that every client makes an well-informed decision.
Our Commitment:
Expertise: Our team brings exceptional knowledge and perspective into the world of luxury timepieces.
Trust: Confidence is the basis of our service, and we prioritize openness in every transaction.
Satisfaction: Client satisfaction is our ultimate goal, and we go the additional step to ensure it.
When you choose WatchesWorld, you’re not just purchasing a watch; you’re investing in a seamless and reliable experience. Explore our collection, and let us assist you in finding the ideal timepiece that mirrors your taste and sophistication. At WatchesWorld, your satisfaction is our time-tested commitment
I’m so happy to read this. This is the kind of manual that needs to be given and not the accidental misinformation that is at the other blogs. Appreciate your sharing this greatest doc.
yangsfitness.com
모두가 믿을 수 없었고 진청 씨를 차례로 바라 보았습니다.
Thanks a bunch for sharing this with all of us you actually know what you’re talking about! Bookmarked. Kindly also visit my website =). We could have a link exchange contract between us!
lasix furosemide: Buy Lasix – lasix 100 mg
http://stromectol.fun/# generic ivermectin
https://amoxil.cheap/# can you buy amoxicillin over the counter canada
amoxicillin 500 mg for sale: buy amoxicillin 500mg – amoxicillin for sale online
Pineal XT is a revolutionary supplement that promotes proper pineal gland function and energy levels to support healthy body function.
Have you ever thought about including a little bit more than just your articles? I mean, what you say is important and everything. But just imagine if you added some great photos or video clips to give your posts more, “pop”! Your content is excellent but with pics and videos, this blog could undeniably be one of the very best in its field. Amazing blog!
indian pharmacies safe online pharmacy india best online pharmacy india
http://indianph.xyz/# indian pharmacies safe
india pharmacy mail order
Даркнет – неведомая зона всемирной паутины, избегающая взоров обычных поисковых систем и требующая специальных средств для доступа. Этот скрытый уголок сети обильно насыщен сайтами, предоставляя доступ к разнообразным товарам и услугам через свои даркнет списки и индексы. Давайте ближе рассмотрим, что представляют собой эти списки и какие тайны они хранят.
Даркнет Списки: Порталы в Неизведанный Мир
Индексы веб-ресурсов в темной части интернета – это вид врата в неощутимый мир интернета. Реестры и справочники веб-ресурсов в даркнете, они позволяют пользователям отыскивать разношерстные услуги, товары и информацию. Варьируя от форумов и магазинов до ресурсов, уделяющих внимание аспектам анонимности и криптовалютам, эти списки предоставляют нам возможность заглянуть в таинственный мир даркнета.
Категории и Возможности
Теневой Рынок:
Даркнет часто связывается с незаконными сделками, где доступны разнообразные товары и услуги – от наркотических препаратов и стрелкового вооружения до похищенной информации и помощи наемных убийц. Каталоги ресурсов в подобной категории облегчают пользователям находить подходящие предложения без лишних усилий.
Форумы и Сообщества:
Даркнет также служит для анонимного общения. Форумы и сообщества, указанные в каталогах даркнета, охватывают широкий спектр – от кибербезопасности и хакерства до политики и философии.
Информационные Ресурсы:
На даркнете есть ресурсы, предоставляющие информацию и инструкции по обходу цензуры, защите конфиденциальности и другим темам, которые могут быть интересны тем, кто хочет остаться анонимным.
Безопасность и Осторожность
Несмотря на анонимность и свободу, даркнет не лишен рисков. Мошенничество, кибератаки и незаконные сделки присущи этому миру. Взаимодействуя с даркнет списками, пользователи должны соблюдать предельную осмотрительность и придерживаться мер безопасности.
Заключение
Реестры даркнета – это путь в неизведанный мир, где сокрыты тайны и возможности. Однако, как и в любой неизведанной территории, путешествие в даркнет требует особой осторожности и знания. Не всегда можно полагаться на анонимность, и использование темной сети требует сознательного подхода. Независимо от ваших интересов – будь то технические аспекты кибербезопасности, поиск уникальных товаров или исследование новых граней интернета – даркнет списки предоставляют ключ
даркнет-список
Теневой интернет – это часть интернета, которая остается скрытой от обычных поисковых систем и требует специального программного обеспечения для доступа. В этой анонимной зоне сети существует масса ресурсов, включая различные списки и каталоги, предоставляющие доступ к разнообразным услугам и товарам. Давайте рассмотрим, что представляет собой каталог даркнета и какие тайны скрываются в его глубинах.
Даркнет Списки: Врата в Невидимый Мир
Для начала, что такое теневой каталог? Это, по сути, каталоги или индексы веб-ресурсов в даркнете, которые позволяют пользователям находить нужные услуги, товары или информацию. Эти списки могут варьироваться от чатов и торговых площадок до ресурсов, специализирующихся на различных аспектах анонимности и криптовалют.
Категории и Возможности
Теневой Рынок:
Даркнет часто ассоциируется с рынком андеграунда, где можно найти различные товары и услуги, включая наркотики, оружие, украденные данные и даже услуги профессиональных устрашителей. Списки таких ресурсов позволяют пользователям без труда находить подобные предложения.
Чаты и Сообщества:
Даркнет также предоставляет платформы для анонимного общения. Форумы и группы на теневых каталогах могут заниматься обсуждением тем от интернет-безопасности и взлома до политики и философии.
Информационные ресурсы:
Есть ресурсы, предоставляющие информацию и инструкции по обходу цензуры, защите конфиденциальности и другим темам, интересным пользователям, стремящимся сохранить анонимность.
Безопасность и Осторожность
При всей своей анонимности и свободе действий темная сторона интернета также несет риски. Мошенничество, кибератаки и незаконные сделки становятся частью этого мира. Пользователям необходимо проявлять максимальную осторожность и соблюдать меры безопасности при взаимодействии с списками теневых ресурсов.
Заключение: Врата в Неизведанный Мир
Даркнет списки предоставляют доступ к скрытым уголкам сети, где сокрыты тайны и возможности. Однако, как и в любой неизведанной территории, важно помнить о возможных рисках и осознанно подходить к использованию даркнета. Анонимность не всегда гарантирует безопасность, и путешествие в этот мир требует особой осторожности и знания.
Независимо от того, интересуетесь ли вы техническими аспектами кибербезопасности, ищете уникальные товары или просто исследуете новые грани интернета, даркнет списки предоставляют ключ
https://indianph.xyz/# indian pharmacy paypal
https://indianph.xyz/# indianpharmacy com
india pharmacy
india pharmacy mail order reputable indian online pharmacy top online pharmacy india
https://indianph.xyz/# indian pharmacy online
Online medicine home delivery
https://indianph.xyz/# Online medicine home delivery
online pharmacy india
Asking questions are truly pleasant thing if you are not understanding something fully, but this post provides fastidious understanding yet.
http://indianph.com/# reputable indian pharmacies
mail order pharmacy india
linetogel
http://indianph.xyz/# reputable indian pharmacies
indian pharmacy paypal
I loved as much as you will receive carried out right here.
The sketch is attractive, your authored subject matter stylish.
nonetheless, you command get got an edginess over that you wish be delivering
the following. unwell unquestionably come
more formerly again as exactly the same nearly very often inside case you
shield this hike.
hey there and thank you for your information – I’ve certainly picked up anything new from right here. I did however expertise some technical points using this site, since I experienced to reload the web site a lot of times previous to I could get it to load correctly. I had been wondering if your web host is OK? Not that I am complaining, but slow loading instances times will very frequently affect your placement in google and can damage your quality score if ads and marketing with Adwords. Anyway I’m adding this RSS to my email and can look out for a lot more of your respective intriguing content. Make sure you update this again very soon..
http://indianph.xyz/# indian pharmacy
top online pharmacy india
smcasino-game.com
그리고 Zhu Houzhao와 같은 황제를 만나면 자신의 재능을 발휘할 기회가 더 많아집니다.
https://indianph.xyz/# reputable indian pharmacies
Gambling
I like this web blog its a master peace ! Glad I found this on google .
reputable indian pharmacies world pharmacy india indian pharmacy online
http://indianph.com/# Online medicine home delivery
online shopping pharmacy india
pragmatic-ko.com
“상인들도 깨달음에 관심이 있습니까?” 홍치제는 놀란 표정을 지었다.
strelkaproject.com
이 세상에서 자신만이 가장 현명하고 강력한 존재입니다.
buy misoprostol over the counter: cytotec abortion pill – buy cytotec over the counter
https://doxycycline.auction/# doxycycline 100mg
buy cytotec online fast delivery Cytotec 200mcg price cytotec buy online usa
tamoxifen for sale: tamoxifen for gynecomastia reviews – does tamoxifen cause weight loss
http://diflucan.pro/# medicine diflucan price
Hi there! I’m at work surfing around your blog from my new apple iphone! Just wanted to say I love reading through your blog and look forward to all your posts! Keep up the great work!
https://diflucan.pro/# diflucan oral
https://diflucan.pro/# buy diflucan without script
lfchungary.com
착한 얼굴을 하고 있는 것 같은 류혜원은 누구보다 강하다.
diflucan 200 diflucan pill canada can you order diflucan online
https://cytotec24.com/# buy cytotec in usa
doxycycline hyclate: doxycycline 150 mg – buy doxycycline
http://nolvadex.guru/# tamoxifen breast cancer prevention
Hello.This post was really remarkable, especially because I was searching for thoughts on this issue last Thursday.
http://doxycycline.auction/# vibramycin 100 mg
В последнее время стали популярными запросы о заливах без предварительной оплаты – услугах, предлагаемых в сети, где клиентам обещают осуществление задачи или предоставление услуги перед внесения денег. Однако, за данной привлекающей внимание возможностью могут быть скрываться серьезные риски и негативные последствия.
Привлекательность безоплатных заливов:
Привлекательная сторона идеи заливов без предоплат заключается в том, что заказчики приобретают услугу или продукцию, не внося сначала деньги. Данное условие может казаться прибыльным и комфортным, в частности для таких, кто избегает ставить под риск деньгами или остаться обманутым. Тем не менее, прежде чем вовлечься в мир бесплатных переводов, следует учесть ряд существенных аспектов.
Риски и отрицательные следствия:
Мошенничество и обман:
За порядочными проектами без предоплат скрываются мошеннические схемы, приготовленные использовать уважение потребителей. Попав в их приманку, вы можете потерять не только, но и финансов.
Сниженное качество выполнения услуг:
Без гарантии исполнителю может стать мало мотивации предоставить высококачественную работу или товар. В итоге заказчик может остаться, а исполнитель не подвергнется значительными последствиями.
Потеря информации и безопасности:
При передаче персональных данных или информации о финансовых средствах для бесплатных заливов существует риск утечки данных и последующего ихнего злоупотребления.
Советы по надежным переводам:
Поиск информации:
До выбором безоплатных переводов осуществите комплексное исследование исполнителя. Отзывы, рейтинговые оценки и репутация могут хорошим критерием.
Предоплата:
По возможности, старайтесь договориться определенный процент оплаты вперед. Это способен сделать сделку более безопасной и гарантирует вам больший управления.
Проверенные сервисы:
Отдавайте предпочтение использованию надежных площадок и сервисов для заливов. Такой выбор снизит риск мошенничества и повысит вероятность на получение наилучших качественных услуг.
Итог:
Не смотря на очевидную привлекательность, заливы без предоплат несут в себе опасности и потенциальные опасности. Осторожность и осмотрительность при выборе поставщика или площадки способны предупредить негативные последствия. Важно запомнить, что безоплатные заливы могут превратиться в причиной проблем, и осознанное принятие решений поможет избежать возможных неприятностей
buy ciprofloxacin over the counter: ciprofloxacin – buy generic ciprofloxacin
даркнет новости
Скрытая сфера – это таинственная и непознанная территория интернета, где действуют свои правила, возможности и угрозы. Ежедневно в пространстве даркнета происходят инциденты, о которых обычные участники могут только подозревать. Давайте изучим актуальные сведения из теневой зоны, которые отражают современные тренды и инциденты в этом скрытом уголке сети.”
Тенденции и События:
“Развитие Технологий и Защиты:
В теневом интернете непрерывно совершенствуются технологические решения и методы защиты. Информация о внедрении усовершенствованных систем кодирования, анонимизации и защиты личных данных говорят о стремлении пользователей и разработчиков к поддержанию надежной обстановки.”
“Свежие Теневые Площадки:
Следуя динамикой спроса и предложения, в даркнете возникают новые торговые площадки. Информация о запуске цифровых рынков подаривают пользователям различные возможности для купли-продажи продукцией и услугами
http://nolvadex.guru/# nolvadex only pct
Покупка удостоверения личности в онлайн магазине – это незаконное и рискованное поступок, которое может привести к значительным последствиям для граждан. Вот некоторые сторон, о которых необходимо помнить:
Незаконность: Покупка удостоверения личности в онлайн магазине является нарушением законодательства. Владение поддельным удостоверением может сопровождаться уголовную ответственность и тяжелые наказания.
Риски личной секретности: Факт использования фальшивого удостоверения личности способен поставить под опасность личную безопасность. Личности, использующие фальшивыми документами, способны стать целью преследования со со стороны законопослушных структур.
Материальные потери: Зачастую мошенники, торгующие фальшивыми удостоверениями, могут использовать ваши личные данные для мошенничества, что приведёт к денежным убыткам. Ваши и материальные сведения способны быть применены в преступных целях.
Трудности при путешествиях: Фальшивый паспорт может быть обнаружен при попытке перейти границу или при контакте с государственными инстанциями. Такое обстоятельство может послужить причиной задержанию, изгнанию или другим серьезным проблемам при путешествиях.
Потеря доверия и репутации: Применение фальшивого паспорта способно привести к утрате доверия со стороны сообщества и работодателей. Это ситуация способна отрицательно влиять на вашу престиж и карьерные возможности.
Вместо того, чтобы рисковать собственной свободой, защитой и престижем, рекомендуется придерживаться закон и воспользоваться государственными путями для получения документов. Эти предоставляют обеспечение всех ваших прав и обеспечивают безопасность личных информации. Незаконные действия могут повлечь за собой неожиданные и негативные последствия, порождая серьезные трудности для вас и ваших ваших сообщества
даркнет 2024
Темное пространство 2024: Неявные взгляды цифровой среды
С инициации теневого интернета представлял собой закуток интернета, где секретность и неявность были рутиной. В 2024 году этот темный мир продолжает, предоставляя новые вызовы и опасности для интернет-сообщества. Рассмотрим, какими тенденции и модификации предстоят обществу в теневом интернете 2024.
Продвижение технологий и Увеличение анонимности
С прогрессом техники, инструменты для обеспечения анонимности в теневом интернете становятся сложнее и эффективными. Использование криптовалют, современных шифровальных методов и децентрализованных сетей делает слежение за поведением пользователей еще более трудным для силовых структур.
Рост тематических рынков
Темные рынки, специализирующиеся на различных товарах и услугах, продолжают расширяться. Психотропные вещества, оружие, средства для хакерских атак, персональная информация – ассортимент продукции бывает все более многообразным. Это создает сложность для силовых структур, который сталкивается с задачей адаптироваться к постоянно меняющимся обстоятельствам преступной деятельности.
Угрозы цифровой безопасности для непрофессионалов
Сервисы аренды хакерских услуг и мошеннические схемы продолжают существовать работоспособными в даркнете. Обычные пользователи становятся целью для киберпреступников, стремящихся зайти к личным данным, счетам в банке и иных секретных данных.
Возможности цифровой реальности в даркнете
С прогрессом техники виртуальной реальности, теневой интернет может войти в новый этап, предоставляя пользователям более реалистичные и захватывающие цифровые области. Это может включать в себя новыми формами преступной деятельности, такими как виртуальные торговые площадки для передачи цифровыми товарами.
Противостояние силам безопасности
Органы обеспечения безопасности совершенствуют свои технические средства и подходы борьбы с даркнетом. Коллективные меры государств и мировых объединений направлены на предотвращение цифровой преступности и противостояние новым вызовам, связанным с развитием скрытого веба.
Вывод
Теневой интернет в 2024 году остается сложной и многогранной средой, где технические инновации продвигаются изменять пейзаж нелегальных действий. Важно для участников оставаться настороженными, обеспечивать свою защиту в интернете и следовать законы, даже при нахождении в виртуальном пространстве. Вместе с тем, борьба с даркнетом требует совместных усилиях от стран, технологических компаний и граждан, чтобы обеспечить защиту в цифровом мире.
даркнет магазин
В недавно интернет стал в беспрерывный ресурс информации, услуг и продуктов. Однако, в среде множества виртуальных магазинов и площадок, существует скрытая сторона, называемая как даркнет магазины. Данный уголок виртуального мира порождает свои рискованные сценарии и сопровождается значительными опасностями.
Каковы Даркнет Магазины:
Даркнет магазины являются онлайн-платформы, доступные через скрытые браузеры и специальные программы. Они оперируют в глубоком вебе, невидимом от обычных поисковых систем. Здесь можно найти не только торговцев нелегальными товарами и услугами, но и разнообразные преступные схемы.
Категории Товаров и Услуг:
Даркнет магазины предлагают разнообразный ассортимент товаров и услуг, от наркотиков и оружия вплоть до хакерских услуг и похищенных данных. На этой темной площадке действуют торговцы, дающие возможность приобретения запрещенных вещей без риска быть выслеженным.
Риски для Пользователей:
Легальные Последствия:
Покупка запрещенных товаров на даркнет магазинах ставит под угрозу пользователей риску столкнуться с полицией. Уголовная ответственность может быть значительным следствием таких покупок.
Мошенничество и Обман:
Даркнет также является плодородной почвой для мошенников. Пользователи могут попасть в обман, где оплата не приведет к к получению товара или услуги.
Угрозы Кибербезопасности:
Даркнет магазины предлагают услуги хакеров и киберпреступников, что создает реальными угрозами для безопасности данных и конфиденциальности.
Распространение Преступной Деятельности:
Экономика даркнет магазинов содействует распространению преступной деятельности, так как обеспечивает инфраструктуру для противозаконных транзакций.
Борьба с Проблемой:
Усиление Кибербезопасности:
Развитие кибербезопасности и технологий слежения помогает бороться с даркнет магазинами, делая их менее поулчаемыми.
Законодательные Меры:
Принятие строгих законов и их эффективная реализация направлены на предупреждение и кара пользователей даркнет магазинов.
Образование и Пропаганда:
Повышение осведомленности о рисках и последствиях использования даркнет магазинов способно снизить спрос на незаконные товары и услуги.
Заключение:
Даркнет магазины предоставляют темным уголкам интернета, где появляются теневые фигуры с преступными планами. Разумное использование ресурсов и активная осторожность необходимы, чтобы защитить себя от рисков, связанных с этими темными магазинами. В конечном итоге, безопасность и законопослушание должны быть на первом месте, когда речь заходит о виртуальных покупках
https://diflucan.pro/# where to get diflucan
http://diflucan.pro/# diflucan canadian pharmacy
http://diflucan.pro/# can you order diflucan online
Howdy! I know this is kinda off topic but I was wondering which blog platform are you using for this website? I’m getting fed up of WordPress because I’ve had problems with hackers and I’m looking at options for another platform. I would be great if you could point me in the direction of a good platform.
buy cytotec pills Abortion pills online buy misoprostol over the counter
https://doxycycline.auction/# buy doxycycline online 270 tabs
great points altogether, you simply received a new reader. What may you suggest about your put up that you just made a few days ago? Any sure?
https://doxycycline.auction/# order doxycycline online
https://cytotec24.com/# cytotec abortion pill
lfchungary.com
Zhu Zaimo의 표정은 매우 추악했습니다. 이 사건은 그가 판단했습니다.
Wonderful website you have here but I was wondering if you knew of any user discussion forums that cover the same topics discussed in this article? I’d really love to be a part of online community where I can get comments from other knowledgeable individuals that share the same interest. If you have any recommendations, please let me know. Kudos!
https://nolvadex.guru/# tamoxifen premenopausal
Great wordpress blog here.. It’s hard to find quality writing like yours these days. I really appreciate people like you! take care
http://cipro.guru/# buy cipro online without prescription
Spot on with this write-up, I really assume this web site wants far more consideration. I’ll in all probability be once more to learn much more, thanks for that info.
http://nolvadex.guru/# tamoxifen generic
http://diflucan.pro/# how much is diflucan over the counter
sweeti fox: sweeti fox – sweety fox
https://angelawhite.pro/# Angela Beyaz modeli
Selamat datang di situs kantorbola , agent judi slot gacor terbaik dengan RTP diatas 98% , segera daftar di situs kantor bola untuk mendapatkan bonus deposit harian 100 ribu dan bonus rollingan 1%
https://angelawhite.pro/# Angela White izle
https://evaelfie.pro/# eva elfie modeli
lana rhoades filmleri: lana rhodes – lana rhoades modeli
Saved as a favorite, I really like your blog!
http://abelladanger.online/# abella danger video
strelkaproject.com
오늘은 왕부시가 근무 중이라 곧장 저택으로 돌아갔다.
https://evaelfie.pro/# eva elfie
lana rhoades: lana rhoades filmleri – lana rhoades
http://evaelfie.pro/# eva elfie modeli
lfchungary.com
“뻔뻔하다.” 장마오는 침을 뱉지 않을 수 없었다.
https://abelladanger.online/# abella danger filmleri
http://lanarhoades.fun/# lana rhoades filmleri
http://sweetiefox.online/# Sweetie Fox video
http://evaelfie.pro/# eva elfie video
http://angelawhite.pro/# Angela Beyaz modeli
lana rhoades filmleri: lana rhodes – lana rhodes
http://angelawhite.pro/# Angela White
http://evaelfie.pro/# eva elfie video
lana rhoades: lana rhoades modeli – lana rhoades izle
creative
https://angelawhite.pro/# Angela White video
http://evaelfie.pro/# eva elfie modeli
I think other web-site proprietors should take this web site as an model, very clean and magnificent user genial style and design, as well as the content. You are an expert in this topic!
windowsresolution.com
급증하는 수요는 Xishan이 비밀리에 던지는 것임에 틀림 없습니다.
eva elfie modeli: eva elfie – eva elfie video
https://sweetiefox.online/# Sweetie Fox izle
https://angelawhite.pro/# Angela Beyaz modeli
I have been absent for some time, but now I remember why I used to love this web site. Thanks, I will try and check back more often. How frequently you update your site?
http://lanarhoades.fun/# lana rhoades izle
lfchungary.com
그러자 군중이 몰려들었고 모두 팔을 들었습니다. “싸워라.”
Angela Beyaz modeli: Abella Danger – abella danger izle
https://angelawhite.pro/# Angela White filmleri
Deference to post author, some excellent selective information.
http://evaelfie.pro/# eva elfie
https://sweetiefox.online/# sweeti fox
lana rhoades modeli: lana rhoades filmleri – lana rhodes
http://lanarhoades.fun/# lana rhoades filmleri
Sumatra Slim Belly Tonic is an advanced weight loss supplement that addresses the underlying cause of unexplained weight gain. It focuses on the effects of blue light exposure and disruptions in non-rapid eye movement (NREM) sleep.
The ProNail Complex is a meticulously-crafted natural formula which combines extremely potent oils and skin-supporting vitamins.
Angela White video: Abella Danger – abella danger izle
Zeneara is marketed as an expert-formulated health supplement that can improve hearing and alleviate tinnitus, among other hearing issues. The ear support formulation has four active ingredients to fight common hearing issues. It may also protect consumers against age-related hearing problems.
you have a great blog here! would you like to make some invite posts on my blog?
https://evaelfie.pro/# eva elfie
I’d must test with you here. Which is not one thing I usually do! I enjoy reading a post that will make people think. Additionally, thanks for allowing me to remark!
Unquestionably consider that which you said. Your favourite reason appeared to be on the web the simplest factor to remember of. I say to you, I certainly get irked even as people think about issues that they plainly don’t understand about. You controlled to hit the nail upon the highest and outlined out the entire thing without having side-effects , people can take a signal. Will likely be back to get more. Thank you
https://evaelfie.pro/# eva elfie modeli
Sweetie Fox: swetie fox – Sweetie Fox filmleri
https://sweetiefox.online/# Sweetie Fox izle
Thank you, I have recently been searching for information about this subject for ages and yours is the greatest I have discovered till now. But, what about the conclusion? Are you sure about the source?
http://angelawhite.pro/# Angela White izle
https://abelladanger.online/# abella danger izle
Angela White izle: ?????? ???? – ?????? ????
http://abelladanger.online/# Abella Danger
hihouse420.com
Zhu Xiurong은 조심스럽게 말했습니다. “매우 심각합니까?”
Your place is valueble for me. Thanks!…
Angela Beyaz modeli: abella danger filmleri – abella danger izle
khasiss.com
이거… 혹시 하늘에서 내려온 농담일까요?
http://evaelfie.pro/# eva elfie
I was very pleased to find this web-site.I wanted to thanks for your time for this wonderful read!! I definitely enjoying every little bit of it and I have you bookmarked to check out new stuff you blog post.
https://evaelfie.site/# eva elfie hd
Обнал карт: Как гарантировать защиту от мошенников и гарантировать защиту в сети
Современный мир высоких технологий предоставляет преимущества онлайн-платежей и банковских операций, но с этим приходит и нарастающая угроза обнала карт. Обнал карт является операцией использования похищенных или незаконно полученных кредитных карт для совершения финансовых транзакций с целью замаскировать их происхождение и предотвратить отслеживание.
Ключевые моменты для безопасности в сети и предотвращения обнала карт:
Защита личной информации:
Соблюдайте осторожность при выдаче личной информации онлайн. Никогда не делитесь банковскими номерами карт, кодами безопасности и дополнительными конфиденциальными данными на непроверенных сайтах.
Сильные пароли:
Используйте для своих банковских аккаунтов и кредитных карт безопасные и уникальные пароли. Регулярно изменяйте пароли для увеличения уровня безопасности.
Мониторинг транзакций:
Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это содействует выявлению подозрительных транзакций и моментально реагировать.
Антивирусная защита:
Утанавливайте и актуализируйте антивирусное программное обеспечение. Такие программы помогут предотвратить вредоносные программы, которые могут быть использованы для изъятия данных.
Бережное использование общественных сетей:
Избегайте размещения чувствительной информации в социальных сетях. Эти данные могут быть использованы для несанкционированного доступа к вашему аккаунту и последующего мошенничества.
Уведомление банка:
Если вы заметили подозрительные операции или утерю карты, свяжитесь с банком немедленно для блокировки карты и предупреждения финансовых убытков.
Образование и обучение:
Следите за новыми методами мошенничества и постоянно обновляйте свои знания, как предотвращать подобные атаки. Современные мошенники постоянно усовершенствуют свои приемы, и ваше понимание может стать ключевым для защиты.
В завершение, соблюдение простых правил безопасности в сети и регулярное обновление знаний помогут вам уменьшить риск стать жертвой мошенничества с картами на рабочем месте и в ежедневной практике. Помните, что ваш финансовый комфорт в ваших руках, и проактивные меры могут сделать ваш онлайн-опыт более защищенным и надежным.
обнал карт форум
Обнал карт: Как гарантировать защиту от хакеров и гарантировать безопасность в сети
Современный мир высоких технологий предоставляет возможности онлайн-платежей и банковских операций, но с этим приходит и повышающаяся опасность обнала карт. Обнал карт является операцией использования украденных или полученных незаконным образом кредитных карт для совершения финансовых транзакций с целью скрыть их источник и пресечь отслеживание.
Ключевые моменты для безопасности в сети и предотвращения обнала карт:
Защита личной информации:
Соблюдайте осторожность при выдаче личной информации онлайн. Никогда не делитесь картовыми номерами, пин-кодами и другими конфиденциальными данными на непроверенных сайтах.
Сильные пароли:
Используйте для своих банковских аккаунтов и кредитных карт надежные и уникальные пароли. Регулярно изменяйте пароли для усиления безопасности.
Мониторинг транзакций:
Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это помогает выявить подозрительные транзакции и оперативно реагировать.
Антивирусная защита:
Устанавливайте и регулярно обновляйте антивирусное программное обеспечение. Такие программы помогут предотвратить вредоносные программы, которые могут быть использованы для изъятия данных.
Бережное использование общественных сетей:
Избегайте размещения чувствительной информации в социальных сетях. Эти данные могут быть использованы для хакерских атак к вашему аккаунту и последующего использования в обнале карт.
Уведомление банка:
Если вы заметили подозрительные операции или утерю карты, свяжитесь с банком сразу для блокировки карты и избежания финансовых ущербов.
Образование и обучение:
Следите за новыми методами мошенничества и постоянно обучайтесь тому, как предотвращать подобные атаки. Современные мошенники постоянно разрабатывают новые методы, и ваше понимание может стать ключевым для защиты
фальшивые 5000 купитьФальшивые купюры 5000 рублей: Опасность для экономики и граждан
Фальшивые купюры всегда были серьезной угрозой для финансовой стабильности общества. В последние годы одним из основных объектов манипуляций стали банкноты номиналом 5000 рублей. Эти контрафактные деньги представляют собой серьезную опасность для экономики и финансовой безопасности граждан. Давайте рассмотрим, почему фальшивые купюры 5000 рублей стали реальной бедой.
Сложность выявления.
Купюры 5000 рублей являются одними из по номиналу, что делает их чрезвычайно привлекательными для фальшивомонетчиков. Отлично проработанные подделки могут быть трудно выявить даже профессионалам в сфере финансов. Современные технологии позволяют создавать превосходные копии с использованием передовых методов печати и защитных элементов.
Риск для бизнеса.
Фальшивые 5000 рублей могут привести к серьезным финансовым убыткам для предпринимателей и компаний. Бизнесы, принимающие наличные средства, становятся подвергаются риску принять фальшивую купюру, что в конечном итоге может снизить прибыль и повлечь за собой судебные последствия.
Повышение инфляции.
Фальшивые деньги увеличивают количество в обращении, что в свою очередь может привести к инфляции. Рост количества поддельных купюр создает дополнительный денежный объем, не обеспеченный реальными товарами и услугами. Это может существенно подорвать доверие к национальной валюте и стимулировать рост цен.
Ущерб для доверия к финансовой системе.
Фальшивые деньги вызывают отсутствие доверия к финансовой системе в целом. Когда люди сталкиваются с риском получить фальшивые купюры при каждой сделке, они становятся более склонными избегать использования наличных средств, что может привести к обострению проблем, связанных с электронными платежами и банковскими системами.
Меры безопасности и образование.
Для предотвращения распространению фальшивых денег необходимо внедрять более эффективные защитные меры на банкнотах и активно проводить просветительскую работу среди населения. Гражданам нужно быть более внимательными при приеме наличных средств и обучаться основам распознавания поддельных купюр.
В заключение:
Фальшивые купюры 5000 рублей представляют серьезную угрозу для финансовой стабильности и безопасности граждан. Необходимо активно внедрять новые технологии защиты и проводить информационные кампании, чтобы общество было лучше осведомлено о методах распознавания и защиты от фальшивых денег. Только совместные усилия банков, правоохранительных органов и общества в целом позволят минимизировать угрозу подделок и обеспечить стабильность финансовой системы.
купить фальшивые деньги
Изготовление и приобретение поддельных денег: опасное дело
Купить фальшивые деньги может показаться привлекательным вариантом для некоторых людей, но в реальности это действие несет серьезные последствия и подрывает основы экономической стабильности. В данной статье мы рассмотрим плохие аспекты закупки поддельной валюты и почему это является опасным шагом.
Незаконность.
Важное и самое важное, что следует отметить – это полная противозаконность создания и использования фальшивых денег. Такие манипуляции противоречат нормам большинства стран, и их штрафы может быть крайне строгим. Приобретение поддельной валюты влечет за собой опасность уголовного преследования, штрафов и даже тюремного заключения.
Экономическо-финансовые последствия.
Фальшивые деньги вредно влияют на экономику в целом. Когда в обращение поступает фальшивая валюта, это вызывает дисбаланс и ухудшает доверие к национальной валюте. Компании и граждане становятся все более подозрительными при проведении финансовых сделок, что порождает к ухудшению бизнес-климата и препятствует нормальному функционированию рынка.
Угроза финансовой стабильности.
Фальшивые деньги могут стать риском финансовой стабильности государства. Когда в обращение поступает большое количество поддельной валюты, центральные банки вынуждены принимать дополнительные меры для поддержания финансовой системы. Это может включать в себя повышение процентных ставок, что, в свою очередь, негативно сказывается на экономике и финансовых рынках.
Опасности для честных граждан и предприятий.
Люди и компании, неосознанно принимающие фальшивые деньги в качестве оплаты, становятся пострадавшими преступных схем. Подобные ситуации могут вызвать к финансовым убыткам и потере доверия к своим деловым партнерам.
Привлечение криминальных группировок.
Приобретение фальшивых денег часто связана с бандитскими группировками и группированным преступлением. Вовлечение в такие сети может повлечь за собой серьезными последствиями для личной безопасности и даже поставить под угрозу жизни.
В заключение, закупка фальшивых денег – это не только неправомерное действие, но и поступок, способное нанести ущерб экономике и обществу в целом. Рекомендуется избегать подобных действий и сосредотачиваться на легальных, ответственных способах обращения с финансами
lana rhoades pics: lana rhoades pics – lana rhoades
Greetings from California! I’m bored to tears at work so I decided to check out your site on my iphone during lunch break. I enjoy the knowledge you present here and can’t wait to take a look when I get home. I’m surprised at how quick your blog loaded on my mobile .. I’m not even using WIFI, just 3G .. Anyhow, excellent blog!
eva elfie: eva elfie full videos – eva elfie full videos
https://sweetiefox.pro/# sweetie fox full video
lana rhoades hot: lana rhoades videos – lana rhoades pics
1881hoki
Simply want to say your article is as amazing. The clearness in your post is simply cool and i could assume you’re an expert on this subject. Fine with your permission let me to grab your feed to keep up to date with forthcoming post. Thanks a million and please keep up the gratifying work.
eva elfie hot: eva elfie new video – eva elfie hd
https://lanarhoades.pro/# lana rhoades
Умение осмысливать сущности и опасностей связанных с легализацией кредитных карт способно помочь людям избегать подобных атак и обеспечивать защиту свои финансовые ресурсы. Обнал (отмывание) кредитных карт — это процедура использования украденных или незаконно полученных кредитных карт для совершения финансовых транзакций с целью замаскировать их происхождения и пресечь отслеживание.
Вот некоторые из способов, которые могут содействовать в предотвращении обнала кредитных карт:
Сохранение личной информации: Будьте осторожными в контексте предоставления личных данных, особенно онлайн. Избегайте предоставления картовых номеров, кодов безопасности и инных конфиденциальных данных на ненадежных сайтах.
Сильные пароли: Используйте надежные и уникальные пароли для своих банковских аккаунтов и кредитных карт. Регулярно изменяйте пароли.
Отслеживание транзакций: Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это поможет своевременно выявить подозрительных транзакций.
Программы антивирус: Используйте антивирусное программное обеспечение и обновляйте его регулярно. Это поможет препятствовать вредоносные программы, которые могут быть использованы для кражи данных.
Осторожное взаимодействие в социальных сетях: Будьте осторожными в сетевых платформах, избегайте публикации чувствительной информации, которая может быть использована для взлома вашего аккаунта.
Уведомление банка: Если вы заметили какие-либо подозрительные операции или утерю карты, сразу свяжитесь с вашим банком для блокировки карты.
Получение знаний: Будьте внимательными к современным приемам мошенничества и обучайтесь тому, как предупреждать их.
Избегая легковерия и осуществляя предупредительные действия, вы можете снизить риск стать жертвой обнала кредитных карт.
rikvip
где купить фальшивые деньги
Ненастоящая валюта: угроза для финансов и социума
Введение:
Фальшивомонетничество – нарушение, оставшееся актуальным на продолжительностью многих веков. Производство и распространение фальшивых денег представляют серьезную угрозу не только для финансовой системы, но и для общественной стабильности. В данной статье мы рассмотрим масштабы проблемы, способы борьбы с подделкой денег и последствия для социума.
История поддельных купюр:
Фальшивые деньги существуют с момента появления самой идеи денег. В старину подделывались металлические монеты, а в современном мире преступники активно используют передовые технологии для подделки банкнот. Развитие цифровых технологий также открыло дополнительные способы для создания электронных аналогов денег.
Масштабы проблемы:
Фальшивые деньги создают опасность для стабильности экономики. Финансовые учреждения, компании и даже простые люди могут стать пострадавшими мошенничества. Рост количества поддельных купюр может привести к инфляции и даже к экономическим кризисам.
Современные методы подделки:
С развитием технологий подделка стала более сложной и изощренной. Преступники используют высокотехнологичное оборудование, специализированные принтеры, и даже машинное обучение для создания невозможно отличить поддельные копии от настоящих денег.
Борьба с фальшивомонетничеством:
Государства и центральные банки активно внедряют современные методы для предотвращения подделки денег. Это включает в себя применение современных защитных элементов на банкнотах, просвещение населения способам определения фальшивых средств, а также сотрудничество с правоохранительными органами для выявления и предотвращения преступных сетей.
Последствия для общества:
Фальшивые деньги несут не только финансовые, но и общественные результаты. Граждане и бизнесы теряют веру к экономическому устройству, а борьба с преступностью требует значительных ресурсов, которые могли бы быть направлены на более положительные цели.
Заключение:
Поддельные средства – серьезная проблема, требующая уделяемого внимания и коллективных действий граждан, органов правопорядка и финансовых институтов. Только с помощью эффективной борьбы с нарушением можно обеспечить стабильность финансовой системы и сохранить доверие к денежной системе
lana rhoades boyfriend: lana rhoades boyfriend – lana rhoades solo
где можно купить фальшивые деньги
Опасность подпольных точек: Места продажи фальшивых купюр”
Заголовок: Опасность подпольных точек: Места продажи поддельных денег
Введение:
Разговор об опасности подпольных точек, занимающихся продажей поддельных денег, становится всё более актуальным в современном обществе. Эти места, предоставляя доступ к поддельным финансовым средствам, представляют серьезную опасность для экономической стабильности и безопасности граждан.
Легкость доступа:
Одной из негативных аспектов подпольных точек является легкость доступа к поддельным деньгам. На темных улицах или в скрытых интернет-пространствах, эти места становятся площадкой для тех, кто ищет возможность обмануть систему.
Угроза финансовой системе:
Продажа фальшивых денег в таких местах создает реальную угрозу для финансовой системы. Введение поддельных средств в обращение может привести к инфляции, понижению доверия к национальной валюте и даже к финансовым кризисам.
Мошенничество и преступность:
Подпольные точки, предлагающие фальшивые купюры, являются очагами мошенничества и преступной деятельности. Отсутствие контроля и законного регулирования в этих местах обеспечивает благоприятные условия для криминальных элементов.
Угроза для бизнеса и обычных граждан:
Как бизнесы, так и обычные граждане становятся потенциальными жертвами мошенничества, когда используют фальшивые купюры, приобретенные в подпольных точках. Это ведет к утрате доверия и серьезным финансовым потерям.
Последствия для экономики:
Вмешательство подпольных точек в экономику оказывает отрицательное воздействие. Нарушение стабильности финансовой системы и создание дополнительных трудностей для правоохранительных органов являются лишь частью последствий для общества.
Заключение:
Продажа фальшивых купюр в подпольных точках представляет собой серьезную угрозу для общества в целом. Необходимо ужесточение законодательства и усиление контроля, чтобы противостоять этому злу и обеспечить безопасность экономической среды. Развитие сотрудничества между государственными органами, бизнес-сообществом и обществом в целом является ключевым моментом в предотвращении негативных последствий деятельности подобных точек.
магазин фальшивых денег купить
Темные закоулки сети: теневой мир продажи фальшивых купюр”
Введение:
Поддельные средства стали неотъемлемой частью теневого мира, где пункты сбыта – это источники серьезных угроз для экономики и общества. В данной статье мы обратим внимание на локации, где процветает подпольная торговля поддельными денежными средствами, включая темные уголки интернета.
Теневые интернет-магазины:
С прогрессом технологий и распространением онлайн-торговли, места продаж фальшивых купюр стали активно функционировать в засекреченных местах интернета. Темные веб-сайты и форумы предоставляют возможность анонимно приобрести фальшивые деньги, создавая тем самым значительный риск для экономики.
Опасные последствия для общества:
Точки оборота поддельных средств на скрытых веб-платформах несут в себе не только потенциальную опасность для финансовой стабильности, но и для простых людей. Покупка поддельных денег влечет за собой опасности: от судебных преследований до утраты доверия со стороны окружающих.
Передовые технологии подделки:
На скрытых веб-площадках активно используются новейшие технологии для создания качественных фальшивок. От печатающих устройств, способных воспроизводить средства защиты, до использования криптовалютных платежей для обеспечения невидимости покупок – все это создает среду, в которой трудно обнаружить и остановить незаконную торговлю.
Необходимость ужесточения мер борьбы:
Борьба с темными местами продаж фальшивых купюр требует комплексного подхода. Важно ужесточить нормативные акты и разработать эффективные меры для выявления и блокировки теневых интернет-магазинов. Также критически важно поднимать готовность к информации общества относительно опасностей подобных практик.
Заключение:
Места продаж поддельных денег на скрытых местах интернета представляют собой серьезную угрозу для финансовой стабильности и общественной безопасности. В условиях расцветающего цифрового мира важно акцентировать внимание на борьбе с подобными практиками, чтобы защитить интересы общества и сохранить веру к экономическому порядку
mia malkova: mia malkova – mia malkova only fans
https://miamalkova.life/# mia malkova hd
The next time I read a blog, I hope that it doesnt disappoint me as much as this one. I mean, I know it was my choice to read, but I actually thought youd have something interesting to say. All I hear is a bunch of whining about something that you could fix if you werent too busy looking for attention.
shopanho.com
하루밖에 걸리지 않았습니다. 하루 만에 사람들이 훔친 물건을 모두 얻었습니다.
Фальшивые рубли, в большинстве случаев, фальсифицируют с целью мошенничества и незаконного получения прибыли. Преступники занимаются клонированием российских рублей, создавая поддельные банкноты различных номиналов. В основном, фальсифицируют банкноты с более высокими номиналами, например 1 000 и 5 000 рублей, поскольку это позволяет им получать большие суммы при уменьшенном числе фальшивых денег.
Процесс фальсификации рублей включает в себя применение высокотехнологичного оборудования, специализированных принтеров и особо подготовленных материалов. Преступники стремятся максимально точно воспроизвести защитные элементы, водяные знаки, металлическую защиту, микроскопический текст и другие характеристики, чтобы замедлить определение поддельных купюр.
Фальшивые рубли часто попадают в обращение через торговые площадки, банки или прочие учреждения, где они могут быть незаметно скрыты среди реальных денежных средств. Это порождает серьезные затруднения для экономической системы, так как поддельные купюры могут привести к убыткам как для банков, так и для населения.
Столь же важно подчеркнуть, что владение и использование фальшивых денег считаются уголовными преступлениями и могут быть наказаны в соответствии с законодательством Российской Федерации. Власти активно борются с такими преступлениями, предпринимая меры по обнаружению и прекращению деятельности преступных групп, занимающихся фальсификацией российской валюты
Фальшивые рубли, часто, фальсифицируют с целью обмана и незаконного получения прибыли. Преступники занимаются подделкой российских рублей, создавая поддельные банкноты различных номиналов. В основном, фальсифицируют банкноты с большими номиналами, вроде 1 000 и 5 000 рублей, поскольку это позволяет им зарабатывать крупные суммы при меньшем количестве фальшивых денег.
Процесс подделки рублей включает в себя использование технологического оборудования высокого уровня, специализированных печатающих устройств и специально подготовленных материалов. Шулеры стремятся максимально детально воспроизвести защитные элементы, водяные знаки безопасности, металлическую защиту, микроскопический текст и прочие характеристики, чтобы препятствовать определение поддельных купюр.
Поддельные денежные средства периодически попадают в обращение через торговые точки, банки или другие организации, где они могут быть легко спрятаны среди реальных денежных средств. Это возникает серьезные затруднения для финансовой системы, так как поддельные купюры могут привести к убыткам как для банков, так и для граждан.
Важно отметить, что владение и использование фальшивых денег считаются уголовными преступлениями и подпадают под наказание в соответствии с нормативными актами Российской Федерации. Власти проводят активные меры с подобными правонарушениями, предпринимая действия по выявлению и пресечению деятельности банд преступников, вовлеченных в фальсификацией российской валюты
hoki 1881
free women dating: http://lanarhoades.pro/# lana rhoades boyfriend
mia malkova girl: mia malkova photos – mia malkova
http://evaelfie.site/# eva elfie
eva elfie new videos: eva elfie full videos – eva elfie hot
fox sweetie: sweetie fox video – ph sweetie fox
bantuan hoki1881
娛樂城首儲
初次接觸線上娛樂城的玩家一定對選擇哪間娛樂城有障礙,首要條件肯定是評價良好的娛樂城,其次才是哪間娛樂城優惠最誘人,娛樂城體驗金多少、娛樂城首儲一倍可以拿多少等等…本篇文章會告訴你娛樂城優惠怎麼挑,首儲該注意什麼。
娛樂城首儲該注意什麼?
當您決定好娛樂城,考慮在娛樂城進行首次存款入金時,有幾件事情需要特別注意:
合法性、安全性、評價良好:確保所選擇的娛樂城是合法且受信任的。檢查其是否擁有有效的賭博牌照,以及是否採用加密技術來保護您的個人信息和交易。
首儲優惠與流水:許多娛樂城會為首次存款提供吸引人的獎勵,但相對的流水可能也會很高。
存款入金方式:查看可用的支付選項,是否適合自己,例如:USDT、超商儲值、銀行ATM轉帳等等。
提款出金方式:瞭解最低提款限制,綁訂多少流水才可以領出。
24小時客服:最好是有24小時客服,發生問題時馬上有人可以處理。
windowsresolution.com
류진은 눈을 가늘게 떴다. “양가 외에 또 누가 있니?”
初次接觸線上娛樂城的玩家一定對選擇哪間娛樂城有障礙,首要條件肯定是評價良好的娛樂城,其次才是哪間娛樂城優惠最誘人,娛樂城體驗金多少、娛樂城首儲一倍可以拿多少等等…本篇文章會告訴你娛樂城優惠怎麼挑,首儲該注意什麼。
娛樂城首儲該注意什麼?
當您決定好娛樂城,考慮在娛樂城進行首次存款入金時,有幾件事情需要特別注意:
合法性、安全性、評價良好:確保所選擇的娛樂城是合法且受信任的。檢查其是否擁有有效的賭博牌照,以及是否採用加密技術來保護您的個人信息和交易。
首儲優惠與流水:許多娛樂城會為首次存款提供吸引人的獎勵,但相對的流水可能也會很高。
存款入金方式:查看可用的支付選項,是否適合自己,例如:USDT、超商儲值、銀行ATM轉帳等等。
提款出金方式:瞭解最低提款限制,綁訂多少流水才可以領出。
24小時客服:最好是有24小時客服,發生問題時馬上有人可以處理。
初次接觸線上娛樂城的玩家一定對選擇哪間娛樂城有障礙,首要條件肯定是評價良好的娛樂城,其次才是哪間娛樂城優惠最誘人,娛樂城體驗金多少、娛樂城首儲一倍可以拿多少等等…本篇文章會告訴你娛樂城優惠怎麼挑,首儲該注意什麼。
娛樂城首儲該注意什麼?
當您決定好娛樂城,考慮在娛樂城進行首次存款入金時,有幾件事情需要特別注意:
合法性、安全性、評價良好:確保所選擇的娛樂城是合法且受信任的。檢查其是否擁有有效的賭博牌照,以及是否採用加密技術來保護您的個人信息和交易。
首儲優惠與流水:許多娛樂城會為首次存款提供吸引人的獎勵,但相對的流水可能也會很高。
存款入金方式:查看可用的支付選項,是否適合自己,例如:USDT、超商儲值、銀行ATM轉帳等等。
提款出金方式:瞭解最低提款限制,綁訂多少流水才可以領出。
24小時客服:最好是有24小時客服,發生問題時馬上有人可以處理。
https://lanarhoades.pro/# lana rhoades videos
DNABET
เว็บ DNABET: เข้าสู่ ประสบการณ์ การแทง ที่ไม่เหมือน ที่ทุกท่าน เคย พบ!
DNABET ยังคง เป็นต้น เลือกที่คนนิยม ใน สาวก การเดิมพัน ทางอินเทอร์เน็ต ในประเทศไทย ในปี 2024.
ไม่จำเป็นต้อง ใช้เวลา ในการเลือก เข้าร่วม DNABET เพราะที่นี่ ไม่ต้อง กังวลว่าจะ ได้ หรือไม่!
DNABET มี ราคาจ่าย ทุกราคาจ่าย หวยที่ สูงมาก ตั้งแต่เริ่มต้นที่ 900 บาท ขึ้นไป เมื่อ ท่าน ถูกรางวัล ได้รับ รางวัลมากมาย มากกว่า เว็บอื่น ๆ ที่คุณ เคย.
นอกจากนี้ DNABET ยัง มี หวย ที่คุณสามารถเลือก มากมายถึง 20 หวย ทั่วโลกนี้ ทำให้ เลือกเล่น ตามใจ ได้อย่างหลากหลายประการ.
ไม่ว่าจะเป็น หวยรัฐบาล หุ้น หวยยี่กี หวยฮานอย หวยลาว และ ลอตเตอรี่รางวัลที่ มีค่า เพียงแค่ 80 บาท.
ทาง DNABET มั่นใจ ในเรื่องการเงิน โดย ได้ เปลี่ยนชื่อ ชันเจน เป็น DNABET เพื่อ เสริมฐานลูกค้าที่มั่นใจ และ ปรับปรุงระบบให้ สะดวกสบายมาก ขึ้นไป.
นอกจากนี้ DNABET ยังมีโปรโมชั่น หวย ประจำเดือนที่สะสมยอดแทงแล้วได้รับรางวัล มากมาย เช่นเดียวกับ โปรโมชั่น สมาชิกใหม่ ท่าน วันนี้ จะได้รับ โบนัสเพิ่ม 500 บาท หรือ ไม่ต้อง เงิน.
นอกจากนี้ DNABET ยังมี ประจำเดือนที่ ท่าน และ DNABET เป็นทางเลือก การเดิมพัน หวย ของท่าน พร้อม รางวัล และ เหล่าโปรโมชั่น ที่ มาก ที่สุดในประเทศไทย ในปี 2024.
อย่า ปล่อย โอกาสดีนี้ ไป มาเป็นส่วนหนึ่งของ DNABET และ เพลิดเพลินไปกับ ประสบการณ์ หวย ทุกท่าน มีโอกาสที่จะ เป็นเศรษฐี ได้ เพียง แค่ท่าน เลือก DNABET เว็บแทงหวย ออนไลน์ ที่ และ มีสมาชิกมากที่สุด ในประเทศไทย!
mia malkova hd: mia malkova photos – mia malkova hd
I was excited to discover this great site. I wanted to thank you for ones time for this particularly
wonderful read!! I definitely enjoyed every little bit of it and i also have you saved to fav to see
new information on your site.
sm-casino1.com
Hongzhi 황제는 여전히 충격을 받았으며 마침내 천천히 회복되었습니다.
twichclip.com
그는 이 세상에 온 이후로 세상을 바꾸고 싶다는 생각을 한 적이 없습니다.당연히 그는 Fang Tangjin의 일방적 인 말을 믿을 수 없었기 때문에 얼굴을 지켰습니다.
I like the valuable information you provide in your articles. I will bookmark your weblog and check again here regularly. I’m quite sure I will learn many new stuff right here! Good luck for the next!
hoki1881
Wow, awesome blog format! How lengthy have you ever been running a blog for?
you make running a blog glance easy. The total glance of your site is fantastic, let alone the content
material! You can see similar here dobry sklep
sweetie fox full: ph sweetie fox – ph sweetie fox
https://miamalkova.life/# mia malkova photos
lana rhoades unleashed: lana rhoades pics – lana rhoades boyfriend
Thank you so much for sharing this wonderful post with us.
lana rhoades hot: lana rhoades full video – lana rhoades pics
You can certainly see your skills within the paintings you write. The sector hopes for more passionate writers like you who aren’t afraid to mention how they believe. At all times follow your heart. “He never is alone that is accompanied with noble thoughts.” by Fletcher.
https://evaelfie.site/# eva elfie photo
eva elfie full video: eva elfie new video – eva elfie photo
apksuccess.com
이 물고기들은 색깔이 모두 노란색으로 강의 붕어와 크게 다르지 않습니다.
Hi, Neat post. There’s an issue along with your site in web explorer, may test this?IE nonetheless is the marketplace leader and a big section of other folks will leave out your great writing because of this problem.
It’s actually a nice and helpful piece of info. I’m glad that you shared this helpful info with us. Please keep us up to date like this. Thanks for sharing.
http://evaelfie.site/# eva elfie hd
KANTORBOLA situs gamin online terbaik 2024 yang menyediakan beragam permainan judi online easy to win , mulai dari permainan slot online , taruhan judi bola , taruhan live casino , dan toto macau . Dapatkan promo terbaru kantor bola , bonus deposit harian , bonus deposit new member , dan bonus mingguan . Kunjungi link kantorbola untuk melakukan pendaftaran .
https://lanarhoades.pro/# lana rhoades boyfriend
eva elfie hd: eva elfie new video – eva elfie videos
Daftar Ngamenjitu
Portal Judi: Platform Lotere Daring Terbesar dan Terpercaya
Ngamenjitu telah menjadi salah satu platform judi online terluas dan terjamin di Indonesia. Dengan bervariasi pasaran yang disediakan dari Grup Semar, Situs Judi menawarkan sensasi bermain togel yang tak tertandingi kepada para penggemar judi daring.
Pasaran Terbaik dan Terpenuhi
Dengan total 56 pasaran, Ngamenjitu menampilkan berbagai opsi terbaik dari pasaran togel di seluruh dunia. Mulai dari pasaran klasik seperti Sydney, Singapore, dan Hongkong hingga pasaran eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan market favorit mereka dengan mudah.
Cara Main yang Sederhana
Portal Judi menyediakan tutorial cara bermain yang sederhana dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di platform Portal Judi.
Hasil Terkini dan Informasi Terkini
Pemain dapat mengakses hasil terakhir dari setiap pasaran secara real-time di Ngamenjitu. Selain itu, info paling baru seperti jadwal bank online, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Bermacam-macam Macam Game
Selain togel, Ngamenjitu juga menawarkan bervariasi jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati berbagai pilihan permainan yang menarik dan menghibur.
Keamanan dan Kenyamanan Klien Dijamin
Portal Judi mengutamakan keamanan dan kenyamanan pelanggan. Dengan sistem security terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di platform ini.
Promosi dan Hadiah Menarik
Ngamenjitu juga menawarkan bervariasi promosi dan bonus istimewa bagi para pemain setia maupun yang baru bergabung. Dari bonus deposit hingga hadiah referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan hadiah yang ditawarkan.
Dengan semua fasilitas dan layanan yang ditawarkan, Ngamenjitu tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Portal Judi!
https://miamalkova.life/# mia malkova photos
sweetie fox full: sweetie fox cosplay – sweetie fox video
mia malkova full video: mia malkova only fans – mia malkova movie
https://evaelfie.site/# eva elfie full videos
crazyslot1.com
이때… 밖에 있던 사람들이 움직임을 듣고 속속 뛰어들었다.
http://aviatorghana.pro/# aviator betting game
aviator pin up: aviator jogo – aviator pin up
Daftar Ngamenjitu
Situs Judi: Situs Lotere Online Terbesar dan Terjamin
Ngamenjitu telah menjadi salah satu platform judi daring terbesar dan terjamin di Indonesia. Dengan bervariasi market yang disediakan dari Grup Semar, Situs Judi menawarkan pengalaman main togel yang tak tertandingi kepada para penggemar judi daring.
Pasaran Terbaik dan Terlengkap
Dengan total 56 market, Situs Judi menampilkan beberapa opsi terbaik dari market togel di seluruh dunia. Mulai dari market klasik seperti Sydney, Singapore, dan Hongkong hingga market eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan pasaran favorit mereka dengan mudah.
Langkah Bermain yang Praktis
Ngamenjitu menyediakan petunjuk cara main yang sederhana dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di platform Situs Judi.
Ringkasan Terkini dan Informasi Terkini
Pemain dapat mengakses hasil terakhir dari setiap market secara real-time di Ngamenjitu. Selain itu, info terkini seperti jadwal bank daring, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Berbagai Macam Permainan
Selain togel, Portal Judi juga menawarkan berbagai jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati berbagai pilihan permainan yang menarik dan menghibur.
Keamanan dan Kenyamanan Pelanggan Terjamin
Situs Judi mengutamakan security dan kepuasan pelanggan. Dengan sistem keamanan terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di platform ini.
Promosi dan Hadiah Menarik
Situs Judi juga menawarkan bervariasi promosi dan bonus istimewa bagi para pemain setia maupun yang baru bergabung. Dari hadiah deposit hingga bonus referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan bonus yang ditawarkan.
Dengan semua fasilitas dan layanan yang ditawarkan, Ngamenjitu tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Portal Judi!
raytalktech.com
30분 후 내시가 급히 다가왔고 그가 가져온 것은 전쟁성에서 온 보고서였다.
https://pinupcassino.pro/# aviator pin up casino
melhor jogo de aposta: jogos que dão dinheiro – aplicativo de aposta
laanabasis.com
Hongzhi 황제는 “이제 질문을 할 때입니다 …”라고 진정했습니다.
Great post. I was checking continuously this blog and I’m impressed! Extremely helpful information specially the last part 🙂 I care for such information much. I was looking for this particular info for a long time. Thank you and good luck.
aviator betano: aviator game – aviator jogo
https://aviatormalawi.online/# aviator
I’m impressed, I need to say. Actually hardly ever do I encounter a weblog that’s each educative and entertaining, and let me tell you, you may have hit the nail on the head. Your thought is excellent; the difficulty is one thing that not sufficient persons are speaking intelligently about. I am very completely satisfied that I stumbled throughout this in my search for something relating to this.
como jogar aviator em moçambique: aviator online – aviator online
https://aviatoroyunu.pro/# aviator
aviator betting game: aviator game – aviator
Portal Judi: Situs Lotere Online Terbesar dan Terjamin
Ngamenjitu telah menjadi salah satu portal judi daring terbesar dan terpercaya di Indonesia. Dengan bervariasi market yang disediakan dari Grup Semar, Ngamenjitu menawarkan sensasi bermain togel yang tak tertandingi kepada para penggemar judi daring.
Pasaran Terbaik dan Terlengkap
Dengan total 56 market, Situs Judi menampilkan beberapa opsi terbaik dari pasaran togel di seluruh dunia. Mulai dari pasaran klasik seperti Sydney, Singapore, dan Hongkong hingga market eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan pasaran favorit mereka dengan mudah.
Cara Main yang Sederhana
Ngamenjitu menyediakan tutorial cara main yang mudah dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di platform Ngamenjitu.
Ringkasan Terkini dan Informasi Terkini
Pemain dapat mengakses hasil terakhir dari setiap market secara real-time di Situs Judi. Selain itu, info paling baru seperti jadwal bank online, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Bermacam-macam Jenis Permainan
Selain togel, Ngamenjitu juga menawarkan berbagai jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati berbagai pilihan permainan yang menarik dan menghibur.
Security dan Kenyamanan Pelanggan Terjamin
Ngamenjitu mengutamakan keamanan dan kepuasan pelanggan. Dengan sistem keamanan terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di situs ini.
Promosi-Promosi dan Bonus Menarik
Portal Judi juga menawarkan berbagai promosi dan bonus menarik bagi para pemain setia maupun yang baru bergabung. Dari hadiah deposit hingga hadiah referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan bonus yang ditawarkan.
Dengan semua fasilitas dan pelayanan yang ditawarkan, Ngamenjitu tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Portal Judi!
aviator oyna slot: aviator bahis – aviator bahis
Situs Judi: Portal Togel Daring Terluas dan Terpercaya
Ngamenjitu telah menjadi salah satu portal judi daring terbesar dan terjamin di Indonesia. Dengan beragam market yang disediakan dari Semar Group, Portal Judi menawarkan sensasi bermain togel yang tak tertandingi kepada para penggemar judi daring.
Market Terbaik dan Terpenuhi
Dengan total 56 market, Ngamenjitu memperlihatkan berbagai opsi terunggul dari market togel di seluruh dunia. Mulai dari market klasik seperti Sydney, Singapore, dan Hongkong hingga pasaran eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan pasaran favorit mereka dengan mudah.
Metode Bermain yang Sederhana
Portal Judi menyediakan petunjuk cara bermain yang praktis dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di platform Ngamenjitu.
Hasil Terkini dan Info Paling Baru
Pemain dapat mengakses hasil terakhir dari setiap market secara real-time di Situs Judi. Selain itu, info paling baru seperti jadwal bank online, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Pelbagai Jenis Permainan
Selain togel, Situs Judi juga menawarkan berbagai jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati berbagai pilihan permainan yang menarik dan menghibur.
Keamanan dan Kepuasan Klien Dijamin
Portal Judi mengutamakan security dan kenyamanan pelanggan. Dengan sistem keamanan terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di situs ini.
Promosi dan Hadiah Istimewa
Portal Judi juga menawarkan berbagai promosi dan bonus menarik bagi para pemain setia maupun yang baru bergabung. Dari bonus deposit hingga hadiah referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan bonus yang ditawarkan.
Dengan semua fasilitas dan layanan yang ditawarkan, Situs Judi tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Portal Judi!
http://aviatorghana.pro/# aviator login
aviator betting game: aviator bet malawi – aviator bet malawi login
It is actually a great and useful piece of info. I am glad that you shared this useful information with us. Please stay us informed like this. Thanks for sharing.
aviator bahis: aviator – aviator oyna slot
обнал карт купить
Умение осмысливать сущности и рисков ассоциированных с легализацией кредитных карт способствует людям предупреждать атак и обеспечивать защиту свои финансовые средства. Обнал (отмывание) кредитных карт — это механизм использования украденных или неправомерно приобретенных кредитных карт для совершения финансовых транзакций с целью скрыть их происхождения и заблокировать отслеживание.
Вот несколько способов, которые могут содействовать в избежании обнала кредитных карт:
Защита личной информации: Будьте осторожными в отношении предоставления личных данных, особенно онлайн. Избегайте предоставления картовых номеров, кодов безопасности и инных конфиденциальных данных на сомнительных сайтах.
Надежные пароли: Используйте безопасные и уникальные пароли для своих банковских аккаунтов и кредитных карт. Регулярно изменяйте пароли.
Отслеживание транзакций: Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это способствует своевременному выявлению подозрительных транзакций.
Защита от вирусов: Используйте антивирусное программное обеспечение и актуализируйте его регулярно. Это поможет защитить от вредоносные программы, которые могут быть использованы для изъятия данных.
Осмотрительное поведение в социальных медиа: Будьте осторожными в онлайн-сетях, избегайте размещения чувствительной информации, которая может быть использована для взлома вашего аккаунта.
Своевременное уведомление банка: Если вы заметили какие-либо подозрительные операции или утерю карты, сразу свяжитесь с вашим банком для блокировки карты.
Получение знаний: Будьте внимательными к инновационным подходам мошенничества и обучайтесь тому, как предотвращать их.
Избегая легковерия и осуществляя предупредительные действия, вы можете уменьшить риск стать жертвой обнала кредитных карт.
обнал карт купить
Незаконные платформы, где осуществляют кэш-аут пластиковых карт, представляют собой онлайн-платформы, специализирующиеся на рассмотрении и проведении противозаконных транзакций с финансовыми картами. На подобных форумах пользователи делают обмен информацией, методами и опытом в области обналичивания, что влечет за собой незаконные действия по получению доступа к финансовым средствам.
Эти платформы могут предлагать разнообразные сервисы, относящиеся с мошенничеством, такие как фальсификация, считывание, вредоносное программное обеспечение и другие методы для сбора информации с финансовых пластиковых карт. Кроме того рассматриваются вопросы, касающиеся использованием украденных информации для совершения транзакций или снятия денег.
Участники незаконных платформ по обналу банковских карт могут сохраняться неизвестными и избегать привлечения правоохранительных органов. Участники могут обмениваться советами, предоставлять услуги, относящиеся к обналом, а также совершать сделки, направленные на незаконную финансовую деятельность.
Важно подчеркнуть, что содействие в подобных практиках не только является нарушение законов, но и может приводить к правовым последствиям и наказанию.
обнал карт работа
Обналичивание карт – это противозаконная деятельность, становящаяся все более популярной в нашем современном мире электронных платежей. Этот вид мошенничества представляет серьезные вызовы для банков, правоохранительных органов и общества в целом. В данной статье мы рассмотрим частоту встречаемости обналичивания карт, используемые методы и возможные последствия для жертв и общества.
Частота обналичивания карт:
Обналичивание карт является весьма распространенным явлением, и его частота постоянно растет с увеличением числа электронных транзакций. Киберпреступники применяют разные методы для получения доступа к финансовым средствам, включая фишинг, вредоносное программное обеспечение, скимминг и другие инновационные подходы.
Методы обналичивания карт:
Фишинг: Злоумышленники могут отправлять ложные электронные сообщения или создавать веб-сайты, имитирующие банковские системы, с целью получения личной информации от владельцев карт.
Скимминг: Злоумышленники устанавливают устройства скиммеры на банкоматах или терминалах для считывания данных с магнитных полос карт.
Вредоносное программное обеспечение: Киберпреступники разрабатывают вредоносные программы, которые заражают компьютеры и мобильные устройства, чтобы получить доступ к личным данным и банковским счетам.
Сетевые атаки: Атаки на системы банков и платежных платформ могут привести к утечке информации о картах и, следовательно, к их обналичиванию.
Последствия обналичивания карт:
Финансовые потери для клиентов: Владельцы карт могут столкнуться с финансовыми потерями, так как средства могут быть списаны с их счетов без их ведома.
Угроза безопасности данных: Обналичивание карт подчеркивает угрозу безопасности личных данных, что может привести к краже личной и финансовой информации.
Ущерб репутации банков: Банки и другие финансовые учреждения могут столкнуться с утратой доверия со стороны клиентов, если их системы безопасности оказываются уязвимыми.
Проблемы для экономики: Обналичивание карт создает экономический ущерб, поскольку оно стимулирует дополнительные затраты на борьбу с мошенничеством и восстановление утраченных средств.
Борьба с обналичиванием карт:
Совершенствование технологий безопасности: Банки и финансовые институты постоянно совершенствуют свои системы безопасности, чтобы предотвратить несанкционированный доступ к картам.
Образование и информирование: Обучение клиентов о методах мошенничества и том, как защитить свои данные, является важным шагом в борьбе с обналичиванием карт.
Сотрудничество с правоохранительными органами: Банки активно сотрудничают с правоохранительными органами для выявления и пресечения преступных схем.
Заключение:
Обналичивание карт – значительная угроза для финансовой стабильности и безопасности личных данных. Решение этой проблемы требует совместных усилий со стороны банков, правоохранительных органов и общества в целом. Только эффективная борьба с мошенничеством позволит обеспечить безопасность электронных платежей и защитить интересы всех участников финансовой системы.
Фальшивые 5000 купить
Опасности фальшивых 5000 рублей: Распространение фиктивных купюр и его консеквенции
В нынешнем обществе, где электронные платежи становятся все более расширенными, преступники не оставляют без внимания и стандартные методы преступной деятельности, такие как дистрибуция поддельных банкнот. В последние недели стало известно о нелегальной продаже недобросовестных 5000 рублевых купюр, что представляет важную опасность для финансовых институтов и населения в целом.
Способы передачи:
Противоправные лица активно используют неявные каналы веба для сбыта поддельных 5000 рублей. На закулисных веб-ресурсах и противозаконных форумах можно обнаружить прошения фальшивых банкнот. К неудаче, это создает хорошие условия для передачи поддельных денег среди людей.
Консеквенции для общества:
Возможность фальшивых денег в циркуляции может иметь весомые воздействия для экономики и доверия к денежной единице. Люди, не догадываясь, что получили поддельные купюры, могут использовать их в различных ситуациях, что в финале приводит к вреду доверию к банкнотам конкретного номинала.
Беды для индивидуумов:
Граждане становятся потенциальными пострадавшими мошенников, когда они непреднамеренно получают фальшивые деньги в транзакциях или при покупках. В результате, они могут столкнуться с нелестными ситуациями, такими как отказ торговцев принять контрафактные купюры или даже шанс ответной ответственности за труд расплаты фальшивыми деньгами.
Противодействие с распространением фальшивых денег:
В интересах защиты граждан от аналогичных проступков необходимо прокачать процедуры по обнаружению и пресечению производства контрафактных денег. Это включает в себя кооперацию между полицейскими и финансовыми учреждениями, а также усиление уровня просвещения общества относительно признаков контрафактных банкнот и техник их разгадывания.
Итог:
Прокладывание поддельных 5000 рублей – это важная риск для устойчивости финансовой системы и безопасности сообщества. Поддерживание кредитоспособности к денежной единице требует согласованных действий со стороны властей, денежных учреждений и каждого человека. Важно быть внимательным и осведомленным, чтобы предотвратить раскрутку контрафактных денег и гарантировать финансовые средства сообщества.
Покупка фальшивых купюр считается неправомерным или потенциально опасным делом, что имеет возможность повлечь за собой важным юридическими воздействиям или постраданию личной финансовой стабильности. Вот несколько других последствий, по какой причине приобретение поддельных банкнот является опасительной иначе неприемлемой:
Нарушение законов:
Покупка иначе применение поддельных денег считаются нарушением закона, нарушающим положения государства. Вас могут подвергнуть юридическим последствиям, что может повлечь за собой задержанию, взысканиям либо тюремному заключению.
Ущерб доверию:
Фальшивые купюры ослабляют уверенность по отношению к финансовой системе. Их использование порождает угрозу для благоприятных граждан и предприятий, которые могут столкнуться с неожиданными перебоями.
Экономический ущерб:
Разведение лживых банкнот оказывает воздействие на финансовую систему, приводя к рост цен и подрывая всеобщую денежную стабильность. Это может послать в потере доверия к денежной системе.
Риск обмана:
Те, кто, задействованы в производством поддельных банкнот, не обязаны соблюдать какие угодно параметры качества. Поддельные купюры могут быть легко обнаружены, что, в итоге послать в убыткам для тех, кто собирается воспользоваться ими.
Юридические последствия:
При случае задержания за использование контрафактных банкнот, вас в состоянии взыскать штраф, и вы столкнетесь с законными сложностями. Это может сказаться на вашем будущем, включая сложности с трудоустройством и кредитной историей.
Благосостояние общества и личное благополучие основываются на честности и доверии в финансовых отношениях. Закупка фальшивых банкнот идет вразрез с этими принципами и может порождать серьезные последствия. Рекомендуется придерживаться норм и осуществлять только законными финансовыми транзакциями.
aviator betano: aviator game – pin up aviator
aviator game: estrela bet aviator – aviator game
aviator bahis: aviator oyunu – aviator sinyal hilesi
crazyslot1.com
그 소식을 들은 Fang Jifan은 갑자기 번개를 맞은 것 같은 느낌을 받았습니다.
pin up aviator: aviator betano – aviator game
kdslot88
ganhar dinheiro jogando: jogos que dão dinheiro – melhor jogo de aposta
Login Ngamenjitu
Portal Judi: Portal Togel Online Terluas dan Terpercaya
Portal Judi telah menjadi salah satu portal judi online terbesar dan terpercaya di Indonesia. Dengan beragam pasaran yang disediakan dari Grup Semar, Ngamenjitu menawarkan sensasi main togel yang tak tertandingi kepada para penggemar judi daring.
Pasaran Terunggul dan Terpenuhi
Dengan total 56 market, Ngamenjitu memperlihatkan beberapa opsi terunggul dari pasaran togel di seluruh dunia. Mulai dari pasaran klasik seperti Sydney, Singapore, dan Hongkong hingga market eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan market favorit mereka dengan mudah.
Cara Main yang Praktis
Situs Judi menyediakan panduan cara bermain yang praktis dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di platform Portal Judi.
Ringkasan Terakhir dan Informasi Paling Baru
Pemain dapat mengakses hasil terakhir dari setiap market secara real-time di Portal Judi. Selain itu, informasi paling baru seperti jadwal bank online, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Pelbagai Macam Permainan
Selain togel, Situs Judi juga menawarkan berbagai jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati bervariasi pilihan permainan yang menarik dan menghibur.
Keamanan dan Kenyamanan Pelanggan Dijamin
Portal Judi mengutamakan keamanan dan kenyamanan pelanggan. Dengan sistem keamanan terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di situs ini.
Promosi-Promosi dan Bonus Menarik
Situs Judi juga menawarkan bervariasi promosi dan hadiah istimewa bagi para pemain setia maupun yang baru bergabung. Dari bonus deposit hingga hadiah referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan bonus yang ditawarkan.
Dengan semua fasilitas dan layanan yang ditawarkan, Ngamenjitu tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Ngamenjitu!
pin up casino: pin up casino – aviator oficial pin up
aplicativo de aposta: ganhar dinheiro jogando – aviator jogo de aposta
zithromax antibiotic: zithromax dosing for pediatrics can you buy zithromax over the counter in mexico
Покупка контрафактных банкнот считается недозволенным и рискованным делом, что в состоянии закончиться серьезным юридическими последствиям иначе ущербу вашей финансовой стабильности. Вот несколько причин, по какой причине закупка фальшивых денег считается опасной либо неприемлемой:
Нарушение законов:
Получение или применение лживых банкнот приравниваются к преступлением, подрывающим нормы страны. Вас могут поддать судебному преследованию, которое может повлечь за собой тюремному заключению, денежным наказаниям либо приводу в тюрьму.
Ущерб доверию:
Контрафактные деньги подрывают доверие по отношению к финансовой системе. Их поступление в оборот возникает опасность для благоприятных гражданских лиц и бизнесов, которые могут столкнуться с неожиданными расходами.
Экономический ущерб:
Разнос поддельных банкнот осуществляет воздействие на экономику, приводя к денежное расширение и ухудшающая общую финансовую равновесие. Это способно послать в утрате уважения к валютной единице.
Риск обмана:
Те, которые, задействованы в изготовлением поддельных купюр, не обязаны сохранять какие-то параметры характеристики. Лживые бумажные деньги могут быть легко обнаружены, что, в итоге повлечь за собой потерям для тех, кто попытается использовать их.
Юридические последствия:
При событии попадания под арест при воспользовании лживых денег, вас в состоянии наказать штрафом, и вы столкнетесь с юридическими проблемами. Это может сказаться на вашем будущем, с учетом возможные проблемы с трудоустройством и кредитной историей.
Благосостояние общества и личное благополучие зависят от честности и доверии в финансовых отношениях. Приобретение лживых денег не соответствует этим принципам и может обладать важные последствия. Рекомендуем держаться законов и заниматься исключительно законными финансовыми действиями.
Купить фальшивые рубли
Покупка лживых купюр считается незаконным либо рискованным поступком, что в состоянии привести к серьезным юридическими последствиям или постраданию индивидуальной денежной надежности. Вот некоторые другие приводов, по какой причине покупка фальшивых денег представляет собой потенциально опасной или неприемлемой:
Нарушение законов:
Покупка или эксплуатация поддельных купюр являются правонарушением, нарушающим нормы страны. Вас имеют возможность подвергнуть судебному преследованию, что может повлечь за собой лишению свободы, штрафам иначе тюремному заключению.
Ущерб доверию:
Контрафактные деньги ослабляют уверенность по отношению к финансовой структуре. Их поступление в оборот создает риск для благоприятных личностей и предприятий, которые в состоянии попасть в неожиданными убытками.
Экономический ущерб:
Распространение контрафактных купюр причиняет воздействие на финансовую систему, инициируя инфляцию и ухудшающая всеобщую денежную устойчивость. Это в состоянии послать в потере уважения к денежной системе.
Риск обмана:
Люди, кто, занимается производством поддельных денег, не обязаны сохранять какие-то нормы степени. Контрафактные купюры могут оказаться легко выявлены, что в итоге послать в расходам для тех, кто попытается использовать их.
Юридические последствия:
При событии захвата за использование фальшивых купюр, вас могут наказать штрафом, и вы столкнетесь с юридическими трудностями. Это может сказаться на вашем будущем, в том числе проблемы с трудоустройством с кредитной историей.
Благосостояние общества и личное благополучие зависят от правдивости и уважении в финансовой сфере. Приобретение контрафактных купюр нарушает эти принципы и может иметь серьезные последствия. Рекомендуем соблюдать правил и вести только законными финансовыми транзакциями.
jbustinphoto.com
그러나 Fang Jifan은 6월 9일 생일 축하 행사에 상당히 긴장했습니다.
aviator sinyal hilesi: aviator bahis – aviator oyna slot
pin-up casino: pin-up cassino – cassino pin up
Mагазин фальшивых денег купить
Покупка фальшивых банкнот является противозаконным или опасным делом, что имеет возможность повлечь за собой тяжелым правовым последствиям иначе вреду личной финансовой устойчивости. Вот несколько других причин, из-за чего получение фальшивых банкнот представляет собой потенциально опасной иначе неприемлемой:
Нарушение законов:
Получение либо эксплуатация контрафактных купюр приравниваются к правонарушением, нарушающим правила общества. Вас способны подвергнуться уголовной ответственности, что потенциально повлечь за собой аресту, финансовым санкциям иначе постановлению под стражу.
Ущерб доверию:
Контрафактные купюры ослабляют доверенность по отношению к денежной структуре. Их обращение формирует опасность для честных гражданских лиц и организаций, которые в состоянии претерпеть неожиданными расходами.
Экономический ущерб:
Расширение лживых банкнот осуществляет воздействие на финансовую систему, провоцируя инфляцию и ухудшающая всеобщую финансовую равновесие. Это имеет возможность закончиться потере доверия в денежной единице.
Риск обмана:
Люди, кто, вовлечены в изготовлением лживых денег, не обязаны соблюдать какие-нибудь уровни уровня. Поддельные купюры могут стать легко обнаружены, что в конечном счете приведет к ущербу для тех, кто стремится воспользоваться ими.
Юридические последствия:
При случае захвата при воспользовании фальшивых денег, вас могут взыскать штраф, и вы столкнетесь с юридическими трудностями. Это может отразиться на вашем будущем, в том числе возможные проблемы с получением работы и кредитной историей.
Общественное и индивидуальное благосостояние зависят от правдивости и доверии в финансовой сфере. Покупка лживых банкнот противоречит этим принципам и может представлять важные последствия. Советуем соблюдать норм и вести только законными финансовыми операциями.
Покупка поддельных банкнот считается незаконным иначе рискованным актом, которое способно повлечь за собой тяжелым юридическим санкциям иначе вреду вашей финансовой благосостояния. Вот несколько приводов, почему приобретение лживых банкнот представляет собой потенциально опасной иначе неуместной:
Нарушение законов:
Закупка иначе использование поддельных денег приравниваются к нарушением закона, нарушающим нормы общества. Вас способны поддать наказанию, что может закончиться задержанию, взысканиям или постановлению под стражу.
Ущерб доверию:
Поддельные банкноты нарушают доверие по отношению к денежной системе. Их применение формирует угрозу для надежных личностей и коммерческих структур, которые имеют возможность попасть в неожиданными потерями.
Экономический ущерб:
Расширение фальшивых денег оказывает воздействие на хозяйство, приводя к инфляцию и подрывая общую финансовую стабильность. Это имеет возможность послать в потере доверия в денежной системе.
Риск обмана:
Люди, какие, осуществляют изготовлением лживых банкнот, не обязаны поддерживать какие угодно нормы качества. Контрафактные деньги могут стать легко распознаны, что, в итоге послать в расходам для тех, кто стремится воспользоваться ими.
Юридические последствия:
В случае лишения свободы при использовании фальшивых банкнот, вас имеют возможность наказать штрафом, и вы столкнетесь с юридическими трудностями. Это может отразиться на вашем будущем, включая возможные проблемы с трудоустройством и кредитной историей.
Общественное и личное благополучие основываются на честности и доверии в финансовой сфере. Закупка фальшивых денег противоречит этим принципам и может обладать серьезные последствия. Советуем придерживаться законов и заниматься только законными финансовыми действиями.
zithromax 1000 mg pills: zithromax 250 price – zithromax
jogo de aposta: deposito minimo 1 real – jogo de aposta online
I consider something really interesting about your blog so I saved to fav.
Hello there, I discovered your blog by means of Google whilst looking for a comparable matter, your site came up, it appears great.
I’ve bookmarked it in my google bookmarks.
Hello there, just changed into aware of your weblog thru Google, and located that it’s truly informative.
I am going to be careful for brussels. I’ll appreciate if you happen to proceed this in future.
Numerous other folks will likely be benefited out of
your writing. Cheers!
canadian pharmacy prices Certified Canadian pharmacies canadian family pharmacy canadianpharm.store
It’s actually a great and useful piece of information. I am happy that you just shared this helpful info with us. Please keep us up to date like this. Thanks for sharing.
online canadian pharmacy: Pharmacies in Canada that ship to the US – pet meds without vet prescription canada canadianpharm.store
Обналичивание карт – это неправомерная деятельность, становящаяся все более широко распространенной в нашем современном мире электронных платежей. Этот вид мошенничества представляет тяжелые вызовы для банков, правоохранительных органов и общества в целом. В данной статье мы рассмотрим частоту встречаемости обналичивания карт, используемые методы и возможные последствия для жертв и общества.
Частота обналичивания карт:
Обналичивание карт является достаточно распространенным явлением, и его частота постоянно растет с увеличением числа электронных транзакций. Киберпреступники применяют разные методы для получения доступа к финансовым средствам, включая фишинг, вредоносное программное обеспечение, скимминг и другие инновационные подходы.
Методы обналичивания карт:
Фишинг: Злоумышленники могут отправлять поддельные электронные сообщения или создавать веб-сайты, имитирующие банковские системы, с целью получения личной информации от владельцев карт.
Скимминг: Злоумышленники устанавливают устройства скиммеры на банкоматах или терминалах для считывания данных с магнитных полос карт.
Вредоносное программное обеспечение: Киберпреступники разрабатывают вредоносные программы, которые заражают компьютеры и мобильные устройства, чтобы получить доступ к личным данным и банковским счетам.
Сетевые атаки: Атаки на системы банков и платежных платформ могут привести к утечке информации о картах и, следовательно, к их обналичиванию.
Последствия обналичивания карт:
Финансовые потери для клиентов: Владельцы карт могут столкнуться с материальными потерями, так как средства могут быть списаны с их счетов без их ведома.
Угроза безопасности данных: Обналичивание карт подчеркивает угрозу безопасности личных данных, что может привести к краже личной и финансовой информации.
Ущерб репутации банков: Банки и другие финансовые учреждения могут столкнуться с утратой доверия со стороны клиентов, если их системы безопасности оказываются уязвимыми.
Проблемы для экономики: Обналичивание карт создает экономический ущерб, поскольку оно стимулирует дополнительные затраты на борьбу с мошенничеством и восстановление утраченных средств.
Борьба с обналичиванием карт:
Совершенствование технологий безопасности: Банки и финансовые институты постоянно совершенствуют свои системы безопасности, чтобы предотвратить несанкционированный доступ к картам.
Образование и информирование: Обучение клиентов о методах мошенничества и том, как защитить свои данные, является важным шагом в борьбе с обналичиванием карт.
Сотрудничество с правоохранительными органами: Банки активно сотрудничают с правоохранительными органами для выявления и пресечения преступных схем.
Заключение:
Обналичивание карт – значительная угроза для финансовой стабильности и безопасности личных данных. Решение этой проблемы требует совместных усилий со стороны банков, правоохранительных органов и общества в целом. Только эффективная борьба с мошенничеством позволит обеспечить безопасность электронных платежей и защитить интересы всех участников финансовой системы.
Опасности поддельных 5000 рублей: Распространение контрафактных купюр и его воздействия
В сегодняшнем обществе, где виртуальные платежи становятся все более широко используемыми, преступники не оставляют без внимания и традиционные методы преступной деятельности, такие как дистрибуция контрафактных банкнот. В последние недели стало известно о нелегальной продаже поддельных 5000 рублевых купюр, что представляет серьезную потенциальную опасность для финансовых институтов и сообщества в итоге.
Подходы торговли:
Преступники активно используют тайные сети сетевого пространства для торговли контрафактных 5000 рублей. На подпольных веб-ресурсах и противозаконных форумах можно обнаружить предложения фальшивых банкнот. К сожалению, это создает положительные условия для распространения фальшивых денег среди населения.
Последствия для сообщества:
Присутствие недостоверных денег в хождении может иметь весомые результаты для хозяйства и доверия к денежной единице. Люди, не подозревая, что получили недостоверные купюры, могут использовать их в разнообразных ситуациях, что в конечном итоге приводит к вреду авторитету к банкнотам конкретного номинала.
Опасности для населения:
Население становятся предполагаемыми потерпевшими оскорбителей, когда они ненамеренно получают поддельные деньги в переговорах или при покупках. В результате, они могут столкнуться с нелестными ситуациями, такими как отказ от приема коммерсантов принять поддельные купюры или даже вероятность привлечения к ответственности за усилие расплаты фальшивыми деньгами.
Противостояние с дистрибуцией поддельных денег:
С с целью предотвращения сообщества от таких же правонарушений необходимо укрепить процедуры по выяснению и пресечению производственной деятельности контрафактных денег. Это включает в себя кооперацию между полицией и финансовыми учреждениями, а также усиление градуса образования населения относительно характеристик поддельных банкнот и техник их определения.
Итог:
Диффузия поддельных 5000 рублей – это значительная опасность для финансовой стабильности и надежности сообщества. Поддержание кредитоспособности к рублю требует коллективных усилий со со стороны государственных органов, финансовых организаций и каждого гражданина. Важно быть настороженным и осведомленным, чтобы предотвратить диффузию недостоверных денег и защитить финансовые активы общества.
Покупка фальшивых банкнот считается неправомерным иначе рискованным действием, что имеет возможность привести к серьезным законным санкциям либо повреждению вашей финансовой устойчивости. Вот некоторые приводов, из-за чего закупка поддельных купюр представляет собой потенциально опасной либо неприемлемой:
Нарушение законов:
Приобретение либо эксплуатация лживых банкнот считаются противоправным деянием, нарушающим законы территории. Вас в состоянии поддать юридическим последствиям, что потенциально закончиться лишению свободы, штрафам иначе лишению свободы.
Ущерб доверию:
Фальшивые купюры подрывают доверенность в финансовой системе. Их использование формирует риск для честных личностей и организаций, которые могут завязать непредвиденными потерями.
Экономический ущерб:
Разнос поддельных купюр оказывает воздействие на экономику, вызывая денежное расширение и ухудшающая всеобщую денежную устойчивость. Это способно повлечь за собой потере доверия в национальной валюте.
Риск обмана:
Личности, которые, осуществляют изготовлением фальшивых денег, не обязаны соблюдать какие-нибудь параметры качества. Фальшивые деньги могут выйти легко выявлены, что, в конечном итоге закончится расходам для тех попытается использовать их.
Юридические последствия:
При случае лишения свободы за использование лживых банкнот, вас в состоянии оштрафовать, и вы столкнетесь с юридическими трудностями. Это может отразиться на вашем будущем, в том числе проблемы с трудоустройством и историей кредита.
Общественное и личное благополучие зависят от честности и доверии в финансовых отношениях. Приобретение контрафактных денег не соответствует этим принципам и может обладать серьезные последствия. Советуем соблюдать правил и осуществлять только правомерными финансовыми транзакциями.
top 10 online pharmacy in india: cheapest online pharmacy – world pharmacy india indianpharm.store
canada drug pharmacy Canada pharmacy canadian pharmacy meds canadianpharm.store
Покупка контрафактных банкнот представляет собой незаконным и потенциально опасным действием, которое в состоянии закончиться серьезным правовым последствиям либо повреждению индивидуальной финансовой стабильности. Вот несколько последствий, почему закупка фальшивых купюр является потенциально опасной или неприемлемой:
Нарушение законов:
Закупка или применение фальшивых банкнот приравниваются к нарушением закона, противоречащим нормы страны. Вас способны поддать судебному преследованию, что потенциально закончиться задержанию, штрафам или приводу в тюрьму.
Ущерб доверию:
Лживые банкноты подрывают доверенность по отношению к финансовой структуре. Их поступление в оборот порождает возможность для надежных личностей и организаций, которые в состоянии столкнуться с неожиданными убытками.
Экономический ущерб:
Разведение контрафактных купюр оказывает воздействие на финансовую систему, вызывая рост цен что ухудшает всеобщую экономическую равновесие. Это может привести к потере доверия к денежной системе.
Риск обмана:
Личности, кто, задействованы в созданием контрафактных купюр, не обязаны сохранять какие-либо нормы степени. Фальшивые деньги могут оказаться легко обнаружены, что, в итоге послать в ущербу для тех, кто пытается их использовать.
Юридические последствия:
При случае попадания под арест при применении фальшивых банкнот, вас способны взыскать штраф, и вы столкнетесь с юридическими трудностями. Это может оказать воздействие на вашем будущем, в том числе возможные проблемы с трудоустройством и кредитной историей.
Благосостояние общества и личное благополучие зависят от честности и доверии в финансовой сфере. Получение поддельных купюр нарушает эти принципы и может иметь важные последствия. Советуем придерживаться законов и заниматься только легальными финансовыми транзакциями.
купил фальшивые рубли
Покупка фальшивых купюр приравнивается к противозаконным или потенциально опасным делом, что может повлечь за собой тяжелым законным санкциям иначе постраданию своей денежной надежности. Вот некоторые причин, из-за чего приобретение лживых банкнот является опасной или недопустимой:
Нарушение законов:
Приобретение и использование фальшивых денег приравниваются к нарушением закона, нарушающим законы государства. Вас могут подвергнуть себя судебному преследованию, что потенциально привести к задержанию, денежным наказаниям иначе приводу в тюрьму.
Ущерб доверию:
Поддельные банкноты ослабляют доверие по отношению к финансовой системе. Их использование возникает угрозу для честных гражданских лиц и предприятий, которые в состоянии столкнуться с внезапными убытками.
Экономический ущерб:
Разведение лживых денег причиняет воздействие на экономическую сферу, приводя к распределение денег что ухудшает общественную финансовую устойчивость. Это способно повлечь за собой утрате уважения к национальной валюте.
Риск обмана:
Лица, какие, занимается производством контрафактных банкнот, не обязаны сохранять какие угодно уровни качества. Контрафактные купюры могут быть легко выявлены, что, в итоге приведет к убыткам для тех, кто попытается использовать их.
Юридические последствия:
В ситуации попадания под арест при применении контрафактных банкнот, вас в состоянии взыскать штраф, и вы столкнетесь с законными сложностями. Это может отразиться на вашем будущем, включая сложности с трудоустройством с кредитной историей.
Общественное и индивидуальное благосостояние основываются на правдивости и доверии в денежной области. Получение лживых денег нарушает эти принципы и может обладать серьезные последствия. Советуем держаться законов и заниматься только легальными финансовыми операциями.
Having read this I thought it was very informative. I appreciate you taking the time and effort to put this article together. I once again find myself spending way to much time both reading and commenting. But so what, it was still worth it!
Hey! This is my first visit to your blog! We are a team of volunteers and starting a new project in a community in the same niche. Your blog provided us beneficial information to work on. You have done a outstanding job!
https://canadianpharmlk.com/# cheap canadian pharmacy canadianpharm.store
thecanadianpharmacy: Cheapest drug prices Canada – drugs from canada canadianpharm.store
http://indianpharm24.com/# buy prescription drugs from india indianpharm.store
Обналичивание карт – это неправомерная деятельность, становящаяся все более распространенной в нашем современном мире электронных платежей. Этот вид мошенничества представляет тяжелые вызовы для банков, правоохранительных органов и общества в целом. В данной статье мы рассмотрим частоту встречаемости обналичивания карт, используемые методы и возможные последствия для жертв и общества.
Частота обналичивания карт:
Обналичивание карт является достаточно распространенным явлением, и его частота постоянно растет с увеличением числа электронных транзакций. Киберпреступники применяют разные методы для получения доступа к финансовым средствам, включая фишинг, вредоносное программное обеспечение, скимминг и другие инновационные подходы.
Методы обналичивания карт:
Фишинг: Злоумышленники могут отправлять ложные электронные сообщения или создавать веб-сайты, имитирующие банковские системы, с целью получения личной информации от владельцев карт.
Скимминг: Злоумышленники устанавливают устройства скиммеры на банкоматах или терминалах для считывания данных с магнитных полос карт.
Вредоносное программное обеспечение: Киберпреступники разрабатывают вредоносные программы, которые заражают компьютеры и мобильные устройства, чтобы получить доступ к личным данным и банковским счетам.
Сетевые атаки: Атаки на системы банков и платежных платформ могут привести к утечке информации о картах и, следовательно, к их обналичиванию.
Последствия обналичивания карт:
Финансовые потери для клиентов: Владельцы карт могут столкнуться с денежными потерями, так как средства могут быть списаны с их счетов без их ведома.
Угроза безопасности данных: Обналичивание карт подчеркивает угрозу безопасности личных данных, что может привести к краже личной и финансовой информации.
Ущерб репутации банков: Банки и другие финансовые учреждения могут столкнуться с утратой доверия со стороны клиентов, если их системы безопасности оказываются уязвимыми.
Проблемы для экономики: Обналичивание карт создает экономический ущерб, поскольку оно стимулирует дополнительные затраты на борьбу с мошенничеством и восстановление утраченных средств.
Борьба с обналичиванием карт:
Совершенствование технологий безопасности: Банки и финансовые институты постоянно совершенствуют свои системы безопасности, чтобы предотвратить несанкционированный доступ к картам.
Образование и информирование: Обучение клиентов о методах мошенничества и том, как защитить свои данные, является важным шагом в борьбе с обналичиванием карт.
Сотрудничество с правоохранительными органами: Банки активно сотрудничают с правоохранительными органами для выявления и пресечения преступных схем.
Заключение:
Обналичивание карт – весомая угроза для финансовой стабильности и безопасности личных данных. Решение этой проблемы требует совместных усилий со стороны банков, правоохранительных органов и общества в целом. Только эффективная борьба с мошенничеством позволит обеспечить безопасность электронных платежей и защитить интересы всех участников финансовой системы.
https://indianpharm24.shop/# top online pharmacy india indianpharm.store
Excellent post. I was checking constantly this blog and I’m inspired! Very helpful information specifically the closing section 🙂 I take care of such info much. I used to be looking for this certain information for a long time. Thanks and good luck.
my canadian pharmacy rx: Cheapest drug prices Canada – cheap canadian pharmacy canadianpharm.store
https://canadianpharmlk.com/# canadian drug prices canadianpharm.store
https://canadianpharmlk.shop/# canadian pharmacies compare canadianpharm.store
I just like the valuable information you supply for your articles. I?ll bookmark your blog and check once more here frequently. I am reasonably sure I will be informed plenty of new stuff right here! Good luck for the next!
You have mentioned very interesting details! ps nice web site.
https://indianpharm24.com/# legitimate online pharmacies india indianpharm.store
india online pharmacy: Top online pharmacy in India – online pharmacy india indianpharm.store
smcasino7.com
Li Chaowen은 “내 조카, 신사 사제와 청 관리들에게 경고하겠습니다.”
india pharmacy Online medicine home delivery buy prescription drugs from india indianpharm.store
http://indianpharm24.shop/# indian pharmacy online indianpharm.store
https://mexicanpharm24.shop/# mexican pharmacy mexicanpharm.shop
http://canadianpharmlk.shop/# pet meds without vet prescription canada canadianpharm.store
fantastic post, very informative. I wonder why the other experts of this sector don’t notice this. You must continue your writing. I’m sure, you’ve a great readers’ base already!
mexico drug stores pharmacies: mexican pharmacy – mexican online pharmacies prescription drugs mexicanpharm.shop
http://indianpharm24.com/# reputable indian pharmacies indianpharm.store
http://canadianpharmlk.com/# cross border pharmacy canada canadianpharm.store
http://indianpharm24.shop/# cheapest online pharmacy india indianpharm.store
I went over this web site and I believe you have a lot of great information, bookmarked (:.
http://mexicanpharm24.com/# mexican pharmaceuticals online mexicanpharm.shop
Great beat ! I would like to apprentice while you amend your website, how can i subscribe for a blog web site? The account aided me a acceptable deal. I had been tiny bit acquainted of this your broadcast provided bright clear concept
where to buy amoxicillin 500mg: how to get amoxicillin over the counter – can you buy amoxicillin uk
It’s hard to find knowledgeable people on this topic, but you sound like you know what you’re talking about! Thanks
madridnortehoy.com
이 가족의 편지를 읽은 Fang Jifan은 우울함을 느끼지 않을 수 없었고 매우 불편했습니다.
amoxicillin 500 mg where to buy: where to buy amoxicillin 500mg without prescription – buy amoxicillin 500mg uk
where to get generic clomid pill: best days to take clomid for twins forum – can i get clomid without insurance
https://prednisonest.pro/# prednisone 54899
where can i get cheap clomid without dr prescription: taking clomid and testosterone together – generic clomid without prescription
buy amoxicillin: amoxicillin dosage for sinus infection – generic amoxicillin over the counter
generic prednisone cost: prednisone without prescription.net – can you buy prednisone over the counter
https://clomidst.pro/# can i order generic clomid without rx
купить фальшивые рубли
Сознание сущности и угроз связанных с отмыванием кредитных карт может помочь людям предотвращать атак и обеспечивать защиту свои финансовые состояния. Обнал (отмывание) кредитных карт — это процесс использования украденных или неправомерно приобретенных кредитных карт для проведения финансовых транзакций с целью сокрыть их происхождения и предотвратить отслеживание.
Вот некоторые из способов, которые могут содействовать в уклонении от обнала кредитных карт:
Сохранение личной информации: Будьте осторожными в контексте предоставления личной информации, особенно онлайн. Избегайте предоставления банковских карт, кодов безопасности и инных конфиденциальных данных на непроверенных сайтах.
Мощные коды доступа: Используйте надежные и уникальные пароли для своих банковских аккаунтов и кредитных карт. Регулярно изменяйте пароли.
Мониторинг транзакций: Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это способствует своевременному выявлению подозрительных транзакций.
Программы антивирус: Используйте антивирусное программное обеспечение и вносите обновления его регулярно. Это поможет защитить от вредоносные программы, которые могут быть использованы для кражи данных.
Осторожное взаимодействие в социальных сетях: Будьте осторожными в онлайн-сетях, избегайте опубликования чувствительной информации, которая может быть использована для взлома вашего аккаунта.
Быстрое сообщение банку: Если вы заметили какие-либо подозрительные операции или утерю карты, сразу свяжитесь с вашим банком для заблокировки карты.
Обучение: Будьте внимательными к новым методам мошенничества и обучайтесь тому, как противостоять их.
Избегая легковерия и принимая меры предосторожности, вы можете снизить риск стать жертвой обнала кредитных карт.
cost of prednisone 10mg tablets: 20mg prednisone – prednisone daily use
https://clomidst.pro/# can you get clomid online
hoki1881
can you buy clomid without prescription: clomid and twins – can i order generic clomid online
kantor bola
Kantorbola adalah situs slot gacor terbaik di indonesia , kunjungi situs RTP kantor bola untuk mendapatkan informasi akurat slot dengan rtp diatas 95% . Kunjungi juga link alternatif kami di kantorbola77 dan kantorbola99 .
buy prednisone canada: prednisone drug class – prednisone buy cheap
where to buy prednisone in canada: prednisone pack – prednisone 20 mg without prescription
http://prednisonest.pro/# generic prednisone cost
Glad to be one of many visitors on this awe inspiring site : D.
amoxicillin 875 125 mg tab: amoxil pharmacy – amoxicillin 500 mg online
where can i get cheap clomid price: get clomid prescription – how can i get generic clomid price
https://clomidst.pro/# how to buy clomid
twichclip.com
더 이상 고민하지 않고 Fang Jifan은 먼저 Zhu Houzhao를 예방 접종했습니다.
where to buy clomid without dr prescription: taking clomid – where to get cheap clomid for sale
https://clomidst.pro/# buy generic clomid
where buy clomid price: clomid multiples – can i order generic clomid
amoxicillin over the counter in canada: can you take amoxicillin on an empty stomach – purchase amoxicillin online without prescription
ttbslot.com
도시 외곽의 중국군 진영에서 Fang Jifan에게 편지가 배달되었습니다.
manga online
hoki 1881
best no prescription online pharmacy: online pharmacy no prescription needed – online medication no prescription
cheapest pharmacy to get prescriptions filled: Online pharmacy USA – cheapest pharmacy for prescriptions
I was looking through some of your blog posts on this internet site and I believe this internet site is real instructive! Continue posting.
buy medication online no prescription: how to order prescription drugs from canada – canadian mail order prescriptions
http://pharmnoprescription.pro/# cheap drugs no prescription
erectile dysfunction pills online cheap ed pills ed online prescription
canadian pharmacy world coupons: mexican pharmacy online – canadian online pharmacy no prescription
no prescription needed canadian pharmacy: Online pharmacy USA – best online pharmacy no prescription
certainly like your website but you need to check the spelling on quite a few of your posts. Many of them are rife with spelling problems and I find it very troublesome to tell the truth nevertheless I will certainly come back again.
https://pharmnoprescription.pro/# no prescription
low cost ed meds: ed drugs online – pills for ed online
Only a smiling visitant here to share the love (:, btw great style.
best online pharmacy without prescriptions: online drugs without prescription – buy drugs online without a prescription
canada online prescription: buy prescription drugs online without doctor – buying online prescription drugs
pharmacies without prescriptions buying prescription drugs in canada no prescription pharmacy
https://edpills.guru/# where to buy ed pills
ed meds on line: ed pills – online prescription for ed
ed doctor online: where can i buy ed pills – cheap boner pills
apksuccess.com
Hongzhi 황제는 “그럼 Fang Qing의 가족에게 전화하여 물어보십시오. “라고 솔직하게 말했습니다.
buy ed medication: ed meds on line – erectile dysfunction medication online
מרכזי המַרכֵּז לְמַעֲנֵה טלגראס כיוונים (Telegrass), הידוע גם בשמות “גַּרְגִּירֵים” או “רִיחֲמִים כיוונים”, הוא אתר מזִין מידע, לינקים, קישורים, מדריכים והסברים בנושאי קנאביס בתוך הארץ. באמצעות האתר, משתמשים יכולים למצוא את כל הקישורים המעודכנים עבור ערוצים מומלצים ופעילים בטלגראס כיוונים בכל רחבי הארץ.
טלגראס כיוונים הוא אתר ובוט בתוך פלטפורמת טלגראס, מזכירות דרכי תקשורת ושירותים שונים בתחום רכישת קנאביס וקשורים. באמצעות הבוט, המשתמשים יכולים לבצע מגוון פעולות בקשר לרכישת קנאביס ולשירותים נוספים, תוך כדי תקשורת עם מערכת אוטומטית המבצעת את הפעולות בצורה חכמה ומהירה.
בוט הטלגראס (Telegrass Bot) מציע מגוון פעולות שימושיות למשתמשים: רכישה קנאביס: בצע הזמנות דרך הבוט על ידי בחירת סוגי הקנאביס, כמות וכתובת למשלוח.
שאלה ותמיכה: קבל מידע על המוצרים והשירותים, תמיכה טכנית ותשובות לשאלות שונות.
בחינה מלאי: בדוק את המלאי הזמין של קנאביס ובצע הזמנה תוך כדי הקשת הבדיקה.
הצבת ביקורות: הוסף ביקורות ודירוגים למוצרים שרכשת, כדי לעזור למשתמשים אחרים.
הוספת מוצרים חדשים: הוסף מוצרים חדשים לפלטפורמה והצג אותם למשתמשים.
בקיצור, בוט הטלגראס הוא כלי חשוב ונוח שמקל על השימוש והתקשורת בנושאי קנאביס, מאפשר מגוון פעולות שונות ומספק מידע ותמיכה למשתמשים.
http://pharmnoprescription.pro/# online doctor prescription canada
cheap erectile dysfunction pills: best online ed medication – erectile dysfunction online
ed prescriptions online: ed medication online – where to buy ed pills
http://mexicanpharm.online/# buying prescription drugs in mexico online
https://pharmacynoprescription.pro/# mail order prescriptions from canada
http://canadianpharm.guru/# canadian pharmacy scam
qiyezp.com
돌고 있어도 Hongzhi 황제는 거의 아무것도 느끼지 못했습니다.
best website to buy prescription drugs: online pharmacy no prescriptions – online pharmacy not requiring prescription
http://pharmacynoprescription.pro/# canadian mail order prescriptions
http://indianpharm.shop/# buy prescription drugs from india
best online pharmacy india: top online pharmacy india – best india pharmacy
mexican rx online: mexico pharmacies prescription drugs – best online pharmacies in mexico
buying prescription drugs in mexico online: mexico pharmacies prescription drugs – mexican drugstore online
http://mexicanpharm.online/# mexican drugstore online
buying prescription drugs in india: buy prescription online – buy medication online with prescription
best online pharmacy india: online shopping pharmacy india – indian pharmacy paypal
mexican border pharmacies shipping to usa: mexican border pharmacies shipping to usa – mexico drug stores pharmacies
https://mexicanpharm.online/# reputable mexican pharmacies online
http://mexicanpharm.online/# mexican rx online
buying prescription drugs in mexico: reputable mexican pharmacies online – buying prescription drugs in mexico online
https://indianpharm.shop/# pharmacy website india
pharmacy canadian superstore: online canadian pharmacy review – canadian online drugs
canadian pharmacy tampa buying drugs from canada canadian pharmacy meds
mexican pharmaceuticals online: pharmacies in mexico that ship to usa – mexican pharmacy
https://indianpharm.shop/# п»їlegitimate online pharmacies india
buy medicines online in india: cheapest online pharmacy india – india online pharmacy
http://pharmacynoprescription.pro/# buy medications without a prescription
http://indianpharm.shop/# india pharmacy
pharmacy no prescription: canadian drugs no prescription – order prescription from canada
online shopping pharmacy india: reputable indian online pharmacy – top 10 online pharmacy in india
mexican border pharmacies shipping to usa: mexico drug stores pharmacies – mexican drugstore online
http://pharmacynoprescription.pro/# how to buy prescriptions from canada safely
cheap drugs no prescription: best online pharmacy without prescription – cheap prescription medication online
top 10 pharmacies in india online shopping pharmacy india top 10 online pharmacy in india
https://indianpharm.shop/# buy medicines online in india
canada ed drugs: canadian family pharmacy – buy canadian drugs
http://pharmacynoprescription.pro/# canadian prescription
buying prescription drugs in mexico: mexico drug stores pharmacies – mexican mail order pharmacies
https://canadianpharm.guru/# best canadian online pharmacy reviews
ttbslot.com
Liu Jin은 갑자기 환호했습니다. 이것은 사실 왕세자 전하의 명령이었습니다.
qiyezp.com
Hongzhi 황제는 “Houzhao는 뜨개질을 할 줄 모르나요? “라고 말했습니다.
top online pharmacy india: top online pharmacy india – top 10 pharmacies in india
no prescription needed: buy drugs online without prescription – prescription canada
meds online no prescription: online pharmacies no prescription – buy prescription drugs online without
http://pharmacynoprescription.pro/# no prescription medicine
indian pharmacy: indianpharmacy com – india pharmacy
Даркнет маркет
Наличие даркнет-маркетов – это процесс, что сопровождается великий любопытство а споры в современном окружении. Подпольная часть веба, или глубокая зона всемирной сети, есть тайную сеть, доступную тольково при помощи определенные программные продукты а конфигурации, гарантирующие скрытность пользовательских аккаунтов. На этой приватной инфраструктуре лежат подпольные рынки – интернет-ресурсы, где-нибудь продажи разные продукты или послуги, обычно противозаконного специфики.
На подпольных рынках можно отыскать различные товары: психоактивные препараты, военные средства, похищенная информация, взломанные аккаунты, подделки и и другое. Подобные же площадки иногда привлекают восторг также уголовников, так и рядовых субъектов, хотящих обойти законодательство или доступить к продуктам или услугам, какие на нормальном всемирной сети могли быть не доступны.
Однако следует помнить, что работа по даркнет-маркетах представляет собой неправомерный специфику и в состоянии создать важные юридические последствия. Органы правопорядка активно борются за противодействуют подобными базарами, однако из-за скрытности даркнета это не перманентно просто так.
Поэтому, присутствие даркнет-маркетов представляет собой реальностью, но эти площадки останавливаются местом крупных потенциальных угроз как и для таковых пользовательских аккаунтов, и для подобных общественности в целом.
Тор веб-навигатор – это особый интернет-браузер, который задуман для обеспечения тайности и надежности в интернете. Он построен на инфраструктуре Тор (The Onion Router), которая позволяет пользователям передавать данными с использованием распределенную сеть серверов, что создает сложным отслеживание их действий и установление их локации.
Главная функция Тор браузера заключается в его способности перенаправлять интернет-трафик через несколько пунктов сети Тор, каждый из них кодирует информацию перед передачей следующему узлу. Это создает массу слоев (поэтому и название “луковая маршрутизация” – “The Onion Router”), что создает практически невероятным подслушивание и определение пользователей.
Тор браузер регулярно применяется для преодоления цензуры в территориях, где ограничен доступ к определенным веб-сайтам и сервисам. Он также позволяет пользователям обеспечить приватность своих онлайн-действий, например просмотр веб-сайтов, общение в чатах и отправка электронной почты, избегая отслеживания и мониторинга со стороны интернет-провайдеров, правительственных агентств и киберпреступников.
Однако стоит запоминать, что Тор браузер не обеспечивает полной конфиденциальности и устойчивости, и его применение может быть ассоциировано с опасностью доступа к неправомерным контенту или деятельности. Также вероятно замедление скорости интернет-соединения из-за
даркнет площадки
Даркнет-площадки, или подпольные рынки, есть веб-платформы, доступные только путем скрытую часть интернета – часть интернета, скрытая для обыкновенных поисковых машин. Таковые торговые площадки разрешают клиентам осуществлять торговлю разнообразными товарными единицами а сервисами, в большинстве случаев противозаконного степени, например наркотические вещества, военные средства, украденные данные, фальшивые документы и иные запретные или даже незаконные товары а послуги.
Темные площадки гарантируют инкогнито их субъектов в результате использования особенных софта и параметров, как The Onion Router, какие скрывают IP-адреса и распределяют интернет-трафик путем разнообразные узловые узлы, что делает непростым отслеживание деятельности правоохранительными органами.
Такие торговые площадки иногда становятся целью интереса правоохранительных органов, какие именно борются за противостоят ними в пределах борьбы противостояния компьютерной преступностью а неправомерной продажей.
Тор теневая часть интернета – это компонент интернета, которая, которая работает над обычнои? сети, однако неприступна для прямого допуска через стандартные браузеры, как Google Chrome или Mozilla Firefox. Для выхода к даннои? сети нуждается специальное програмное обеспечение, например, Tor Browser, которыи? обеспечивает секретность и сафети пользователеи?.
Основнои? принцип работы Тор даркнета основан на использовании маршрутов через разные точки, которые криптуют и двигают трафик, вызывая сложным отслеживание его источника. Это формирует секретность для пользователеи?, укрывая их реальные IP-адреса и местоположение.
Тор даркнет вмещает разнообразные плеи?сы, включая веб-саи?ты, форумы, рынки, блоги и остальные онлаи?н-ресурсы. Некоторые из подобных ресурсов могут быть недоступны или пресечены в обыкновеннои? сети, что вызывает Тор даркнет полем для трейдинга информациеи? и услугами, включая товары и услуги, которые могут быть противозаконными.
Хотя Тор даркнет используется некоторыми людьми для пересечения цензуры или защиты личности, он так же становится платформои? для различных противозаконных деи?ствии?, таких как торговля наркотиками, оружием, кража личных данных, поставка услуг хакеров и прочие преступные действия.
Важно сознавать, что использование Тор даркнета не всегда законно и может в себя серьезные опасности для сафети и законности.
https://canadianpharm.guru/# www canadianonlinepharmacy
best online pharmacy india: buy medicines online in india – top 10 online pharmacy in india
http://pharmacynoprescription.pro/# online medicine without prescription
hoki 1881
online pharmacy india: Online medicine order – buy medicines online in india
https://canadianpharm.guru/# canadian pharmacy uk delivery
onair2tv.com
이… 첩… 아 안돼, 장관은 할 수 없어.
стране, как и в других территориях, теневая сеть представляет собой участок интернета, недоступную для регулярного поискавания и пересмотра через регулярные поисковики. В отличие от публичной поверхностной сети, даркнет является скрытым фрагментом интернета, выход к какому обычно проводится через эксклюзивные программы, наподобие Tor Browser, и неизвестные сети, наподобные Tor.
В теневой сети собраны различные ресурсы, включая форумы, рынки, логи и остальные интернет-ресурсы, которые могут быть неприступны или пресечены в стандартной сети. Здесь возможно найти различные вещи и послуги, включая незаконные, такие как наркотики, оружие, компрометированные сведения, а также сервисы компьютерных взломщиков и прочие.
В государстве теневая сеть так же применяется для преодоления цензуры и мониторинга со стороны сторонних. Некоторые пользователи могут использовать его для трансфера информацией в обстоятельствах, когда воля слова заблокирована или информационные материалы подвергаются цензуре. Однако, также следует отметить, что в даркнете имеется много законодательной процесса и рискованных ситуаций, включая обман и компьютерные преступления
drugs from canada: canadian pharmacy sarasota – the canadian pharmacy
reputable indian pharmacies india online pharmacy top 10 pharmacies in india
https://canadianpharm.guru/# canadian drug pharmacy
canadian pharmacy ratings: my canadian pharmacy review – safe canadian pharmacy
https://slotsiteleri.guru/# canli slot siteleri
http://pinupgiris.fun/# pin up casino guncel giris
sweet bonanza yasal site: sweet bonanza siteleri – sweet bonanza demo turkce
http://gatesofolympus.auction/# gates of olympus guncel
Наличие подпольных онлайн-рынков – это процесс, что вызывает значительный любопытство или разговоры в современном сообществе. Даркнет, или темная часть всемирной сети, представляет собой тайную инфраструктуру, доступных исключительно с помощью специальные программы и конфигурации, обеспечивающие инкогнито пользователей. В этой данной подпольной сети расположены даркнет-маркеты – интернет-ресурсы, где-нибудь торговля разные продукты а услуговые предложения, в большинстве случаев противозаконного степени.
По подпольных рынках можно обнаружить различные продуктовые товары: наркотические препараты, военные средства, данные, похищенные из систем, взломанные учетные записи, подделки или и другое. Такие маркеты часто магнетизирузивают заинтересованность также правонарушителей, а также рядовых пользователей, намеревающихся обойти закон либо доступить к товарам и услуговым предложениям, какие на стандартном сети могли бы быть не доступны.
Впрочем нужно помнить, как активность на даркнет-маркетах имеет противозаконный тип и может спровоцировать важные правовые нормы последствия по закону. Полицейские органы энергично борются противодействуют такими рынками, но все же из-за скрытности даркнета это условие далеко не постоянно без проблем.
В результате, присутствие скрытых интернет-площадок является сущностью, но все же такие рынки пребывают сферой значительных угроз как для таких, так и для субъектов, а также для сообщества в в целом и целом.
http://gatesofolympus.auction/# gates of olympus oyna demo
aviator oyna: aviator oyna 100 tl – aviator sinyal hilesi ucretsiz
https://aviatoroyna.bid/# aviator casino oyunu
https://aviatoroyna.bid/# aviator oyna
aviator: aviator sinyal hilesi ucretsiz – aviator oyna 20 tl
https://pinupgiris.fun/# pin up
даркнет покупки
Покупки в подпольной сети: Заблуждения и Факты
Подпольная сеть, загадочная часть сети, заинтересовывает интерес пользователей своим анонимностью и возможностью купить различные продукты и сервисы без излишних действий. Однако, путешествие в этот мир непрозрачных рынков связано с комплексом рисков и нюансов, о чем следует знать перед совершением транзакций.
Что представляет собой Даркнет и как он работает?
Для того, кому не знакомо с этим термином, темный интернет – это часть веба, скрытая от стандартных поисков. В скрытой части веба существуют уникальные онлайн-рынки, где можно найти почти все, что угодно : от препаратов и стрелкового оружия до взломанных аккаунтов и фальшивых документов.
Иллюзии о приобретении товаров в темном интернете
Анонимность обеспечена: Хотя, использование технологий анонимности, например Tor, может помочь скрыть от глаз свою активность в сети, анонимность в Даркнете не является абсолютной. Имеется возможность, что ваша информацию о вас могут раскрыть мошенники или даже сотрудники правоохранительных органов.
Все товары – высокого качества: В темном интернете можно наткнуться на множество торговцев, предлагающих товары и услуги. Однако, нельзя гарантировать качество или оригинальность продукции, поскольку нет возможности провести проверку до того, как вы сделаете заказ.
Легальные покупки без ответственности: Многие пользователи ошибочно считают, что заказывая товары в темном интернете, они подвергают себя риску меньшему риску, чем в обычной жизни. Однако, заказывая противоправные товары или сервисы, вы рискуете наказания.
Реальность покупок в темном интернете
Негативные стороны мошенничества и афер: В Даркнете множество мошенников, предрасположены к мошенничеству пользователей, которые недостаточно бдительны. Они могут предложить фальшивые товары или просто исчезнуть с вашими деньгами.
Опасность государственных органов: Пользователи подпольной сети рискуют к ответственности перед законом за приобретение и заказ незаконных товаров и услуг.
Неопределённость выходов: Не каждый заказ в Даркнете завершаются благополучно. Качество продукции может оказаться низким, а процесс покупки может привести к неприятным последствиям.
Советы для безопасных покупок в подпольной сети
Проводите детальный анализ поставщика и услуги перед осуществлением заказа.
Используйте безопасные программы и сервисы для обеспечения анонимности и безопасности.
Платите только безопасными методами, например, криптовалютами, и не раскрывайте личные данные.
Будьте бдительны и очень внимательны во всех ваших действиях и решениях.
Заключение
Покупки в подпольной сети могут быть как интересным, так и рискованным опытом. Понимание рисков и применение соответствующих мер предосторожности помогут уменьшить риск негативных последствий и гарантировать безопасные покупки в этом непознанном уголке сети.
http://gatesofolympus.auction/# gates of olympus demo
https://aviatoroyna.bid/# aviator hilesi ücretsiz
הימורים בפלטפורמת האינטרנט – הימורי ספורטיביים, קזינו אונליין, משחקי קלפים.
מימורים ברשת הופכים לקטגוריה מבוקש במיוחד בעידן הדיגיטלי.
מיליוני משתתפים ממנסות את המזל במגוון מימורים המגוונים.
התהליכים הזה משנה את הרגע הניסיון והתרגשות.
גם עוסק בשאלות אתיות וחברתיות העומדות ממאחורי ההימורים המקוונים.
בעידן הדיגיטלי, מימורים באינטרנט הם חלק מתרבות הספורטיבי, הבידור והחברה העכשווית.
המימורים בפלטפורמת האינטרנט כוללים אפשרויות רחב של פעילויות, כולל מימונים על תוצאות ספורטיביות, פוליטיים, וגם מזג האוויר.
ההימורים הם מתבצעים באמצע
gates of olympus s?rlar?: gates of olympus giris – gates of olympus max win
exprimegranada.com
この記事は実に実用的で、大変役に立ちました!
sweet bonanza kazanc: sweet bonanza taktik – sweet bonanza free spin demo
https://gatesofolympus.auction/# gates of olympus hilesi
https://slotsiteleri.guru/# slot casino siteleri
https://sweetbonanza.bid/# sweet bonanza free spin demo
Темный интернет: запрещённое пространство компьютерной сети
Темный интернет, тайная зона интернета продолжает привлекать внимание внимание как общественности, и также правоохранительных структур. Этот скрытый уровень сети известен своей анонимностью и способностью совершения преступных деяний под маской анонимности.
Суть теневого уровня интернета сводится к тому, что этот слой не доступен для обычных браузеров. Для доступа к этому уровню требуются специальные инструменты и программы, которые обеспечивают анонимность пользователей. Это создает отличную площадку для разнообразных нелегальных действий, в том числе торговлю наркотическими веществами, оружием, хищение персональной информации и другие незаконные манипуляции.
В ответ на растущую угрозу, некоторые государства приняли законодательные инициативы, направленные на запрещение доступа к подпольной части сети и преследование лиц осуществляющих незаконную деятельность в этом скрытом мире. Впрочем, несмотря на предпринятые шаги, борьба с теневым уровнем интернета представляет собой трудную задачу.
Важно подчеркнуть, что полное прекращение доступа к темному интернету практически невыполнимо. Даже при строгих мерах регулирования, доступ к этому уровню интернета всё ещё возможен через различные технологии и инструменты, применяемые для обхода запретов.
Помимо законодательных мер, имеются также проекты сотрудничества между правоохранительными структурами и технологическими компаниями для противодействия незаконным действиям в подпольной части сети. Впрочем, эта борьба требует не только технических решений, но и совершенствования методов выявления и предотвращения незаконных действий в этой области.
В итоге, несмотря на введенные запреты и предпринятые усилия в борьбе с преступностью, теневой уровень интернета остается серьезной проблемой, которая требует комплексного подхода и совместных усилий как со стороны правоохранительных органов, а также технологических организаций.
даркнет открыт
В последнее время скрытый уровень интернета, вызывает все больше интереса и становится объектом различных дискуссий. Многие считают его темной зоной, где процветают преступные поступки и нелегальные операции. Однако, мало кто осведомлен о том, что даркнет не является закрытой сферой, и доступ к нему возможен для каждого пользователь.
В отличие от обычного интернета, даркнет не доступен для поисковых систем и стандартных браузеров. Для того чтобы войти в него, необходимо использовать специализированные приложения, такие как Tor или I2P, которые обеспечивают скрытность и криптографическую защиту. Однако, это не означает, что даркнет недоступен для широкой публики.
Действительно, даркнет открыт для всех, кто имеет интерес и возможность его исследовать. В нем можно найти разнообразные материалы, начиная от обсуждения тем, которые запрещены в обычных сетях, и заканчивая возможностью посещения специализированным рынкам и услугам. Например, множество информационных сайтов и форумов на даркнете посвящены темам, которые считаются табу в стандартных окружениях, таким как политика, вероисповедание или цифровые валюты.
Кроме того, даркнет часто используется активистами и журналистами, которые ищут способы обхода цензуры и средства для сохранения анонимности. Он также служит платформой для свободного обмена информацией и концепциями, которые могут быть подавлены в странах с авторитарными режимами.
Важно понимать, что хотя даркнет предоставляет свободу доступа к информации и возможность анонимного общения, он также может быть использован для незаконных целей. Тем не менее, это не делает его закрытым и недоступным для всех.
Таким образом, даркнет – это не только скрытая сторона сети, но и место, где любой может найти что-то увлекательное или пригодное для себя. Важно помнить о его двуединстве и использовать его с умом и с учетом рисков, которые он несет.
aviator oyunu 100 tl: aviator oyunu giris – aviator hilesi
https://sweetbonanza.bid/# sweet bonanza slot
https://sweetbonanza.bid/# sweet bonanza siteleri
sweet bonanza taktik: sweet bonanza 90 tl – sweet bonanza indir
https://aviatoroyna.bid/# aviator mostbet
gates of olympus guncel: pragmatic play gates of olympus – gate of olympus hile
elementor
http://gatesofolympus.auction/# gates of olympus demo
2024 en iyi slot siteleri: casino slot siteleri – en guvenilir slot siteleri
https://gatesofolympus.auction/# gate of olympus hile
Ремонт квартир Дубай
gates of olympus oyna demo: gates of olympus demo – gates of olympus taktik
http://pinupgiris.fun/# pin-up giris
http://aviatoroyna.bid/# aviator sinyal hilesi ucretsiz
http://aviatoroyna.bid/# aviator sinyal hilesi ücretsiz
canadian pharmacy: canadian pharmacy uk delivery – online canadian pharmacy
buying from online mexican pharmacy: mexican pharmacy – reputable mexican pharmacies online
Online medicine home delivery top 10 online pharmacy in india indian pharmacy online
mexico drug stores pharmacies: cheapest mexico drugs – mexico drug stores pharmacies
mexican mail order pharmacies: cheapest mexico drugs – mexico drug stores pharmacies
reputable mexican pharmacies online: Online Pharmacies in Mexico – best mexican online pharmacies
canadian pharmacy ratings: Licensed Canadian Pharmacy – real canadian pharmacy
top 10 pharmacies in india: Cheapest online pharmacy – cheapest online pharmacy india
mexican pharmacy: mexico pharmacy – buying from online mexican pharmacy
mexico drug stores pharmacies: Mexican Pharmacy Online – mexico pharmacy
mexican mail order pharmacies: Mexican Pharmacy Online – buying from online mexican pharmacy
Online medicine home delivery: indian pharmacies safe – top online pharmacy india
indian pharmacy: indian pharmacy – reputable indian online pharmacy
сеть даркнет
Теневой уровень интернета: запрещённое пространство виртуальной сети
Темный интернет, тайная зона интернета продолжает привлекать внимание и граждан, а также служб безопасности. Данный засекреченный уровень интернета примечателен своей анонимностью и способностью совершения противоправных действий под маской анонимности.
Сущность темного интернета заключается в том, что этот слой не доступен обычным браузеров. Для доступа к данному слою требуются специальные инструменты и программы, предоставляющие анонимность пользователям. Это создает идеальную среду для разнообразных нелегальных действий, включая сбыт наркотиков, продажу оружия, кражу личных данных и другие противоправные действия.
В свете растущую угрозу, ряд стран приняли законы, направленные на запрещение доступа к подпольной части сети и привлечение к ответственности тех, кто совершающих противозаконные действия в этом скрытом мире. Тем не менее, несмотря на предпринятые шаги, борьба с темным интернетом остается сложной задачей.
Следует отметить, что запретить темный интернет полностью практически невыполнимо. Даже при строгих мерах регулирования, доступ к этому уровню интернета все еще осуществим с использованием разнообразных технических средств и инструментов, используемые для обхода блокировок.
Кроме законодательных мер, имеются также совместные инициативы между правоохранительными органами и технологическими компаниями для борьбы с преступностью в темном интернете. Впрочем, эта борьба требует не только технических решений, но также улучшения методов выявления и предотвращения противозаконных манипуляций в данной среде.
Таким образом, несмотря на запреты и усилия в борьбе с незаконными деяниями, подпольная часть сети остается серьезной проблемой, нуждающейся в комплексных подходах и коллективных усилиях со стороны правоохранительных структур, и технологических корпораций.
world pharmacy india: Online medicine home delivery – online shopping pharmacy india
exprimegranada.com
この記事が大好きです。とても参考になります。
п»їbest mexican online pharmacies cheapest mexico drugs purple pharmacy mexico price list
my canadian pharmacy: canadian pharmacy meds – canadian online drugs
buy canadian drugs: Prescription Drugs from Canada – escrow pharmacy canada
https://prednisoneall.shop/# purchase prednisone from india
https://prednisoneall.com/# order prednisone on line
prednisone buy online nz: prednisone 60 mg tablet – prednisone 250 mg
https://clomidall.shop/# how to buy clomid
http://amoxilall.shop/# amoxicillin capsules 250mg
zithromax 500 without prescription zithromax z-pak price without insurance zithromax 500 mg lowest price pharmacy online
http://prednisoneall.shop/# prednisone 20mg for sale
amoxicillin 30 capsules price: amoxicillin 500mg – amoxil pharmacy
I wanted to thank you for this very good read!! I certainly loved every bit of
it. I have got you saved as a favorite to check out new things you
post…
http://prednisoneall.com/# where can i buy prednisone online without a prescription
https://zithromaxall.com/# generic zithromax medicine
where can i get amoxicillin 500 mg: generic amoxicillin – amoxil generic
https://zithromaxall.shop/# zithromax antibiotic without prescription
donmhomes.com
この記事から学んだことは、非常に価値があります。感謝しています。
sildenafil online: sildenafil iq – viagra canada
thephotoretouch.com
하지만… 홍지황제는 그냥… 화를 낼 수 없었다.
cheap viagra: sildenafil over the counter – buy viagra here
https://elementor.com/
Cheap generic Viagra online: buy viagra online – Generic Viagra online
http://sildenafiliq.xyz/# viagra canada
Kamagra tablets Kamagra gel Kamagra tablets
Cheap generic Viagra online: sildenafil iq – Viagra online price
Elevate Your Performance to New Heights with Meldonium
Dear Peoples,
In the relentless pursuit of excellence, whether it’s on the athletic track, in the realm of academics, or within the high-pressure world of professional pursuits,
the margin between success and second place can be
razor-thin. We understand the unyielding desire
to push beyond your limits, to transform good into great, and great into
extraordinary. That’s why we are reaching out to you about Meldonium, also known as Mildronate, a cutting-edge solution designed to amplify your performance, ensuring that “Whatever you do, you do better and more successfully.”
shop.toxylact.com/product/meldonium-low-price/
Meldonium stands as a beacon for those striving for peak performance.
As a synthetic analog of gamma-butyrobetaine, this potent compound is more than just a supplement;
it is a gateway to unlocking your untapped potential.
Its unique pharmacodynamics offer cytoprotective and cardioprotective
benefits, meticulously engineered to optimize your body’s energy use.
By shifting the cellular metabolism from fatty acid oxidation to glycolysis, Meldonium ensures a more efficient
energy use under stress, propelling you towards achieving your goals with unparalleled vigor.
The swift absorption and prompt action of Meldonium, reaching peak plasma
concentrations within 1-2 hours of administration, make it an ideal ally in your quest for excellence.
With indications for the treatment of various cardiac and cerebrovascular disorders,
it also stands as a testament to our commitment to
not only enhancing your performance but also safeguarding your health.
However, greatness requires precision. Meldonium is recommended for individuals beyond
the constraints of severe hepatic impairment, hypersensitivity,
pregnancy, lactation, and those under 18.
Adhering to the recommended dosage of 500-1000 mg per day for
cardiac conditions and 500 mg per day for cerebrovascular disorders, underlines our dedication to your health and well-being.
Side effects, although rare, can include tachycardia, changes in blood pressure,
and more, emphasizing the importance of adherence to
prescribed guidelines and consultations with healthcare
professionals.
Imagine a life where your mental and physical faculties are heightened, where your
achievements are not just celebrated but marveled at.
Meldonium is your stepping stone to this reality. Embrace the chance to redefine
the limits of what’s possible. Because with Meldonium, whatever you do,
you do it better and more successfully.
Elevate your performance. Elevate your life. With Meldonium.
Yours in pursuit of excellence,
Dimitar Kehayov MD, PhD
P.S. Please kindly note that we receive and orders
at WhatsApp or Viber at: 00359884777799
Kamagra Oral Jelly: Kamagra gel – buy Kamagra
Kamagra Oral Jelly: Kamagra Oral Jelly Price – cheap kamagra
Tadalafil Tablet cialis best price п»їcialis generic
Good day! Do you know if they make any plugins to assist
with SEO? I’m trying to get my website to rank for some targeted keywords
but I’m not seeing very good success. If you know of any please
share. Thanks! I saw similar article here: Scrapebox AA List
http://sildenafiliq.com/# best price for viagra 100mg
Kamagra 100mg price: Sildenafil Oral Jelly – buy kamagra online usa
https://tadalafiliq.shop/# Generic Cialis price
Generic Viagra for sale: buy viagra online – Sildenafil 100mg price
https://sildenafiliq.xyz/# Cheapest Sildenafil online
sandyterrace.com
이른 아침, 불안한 Shen Wen은 누군가에게 세단 의자를 Xishan으로 옮기라고 명령했습니다.
Generic Tadalafil 20mg price: Buy Cialis online – Tadalafil Tablet
Buy Tadalafil 10mg tadalafil iq Buy Tadalafil 10mg
sildenafil 50 mg price: Cheapest Sildenafil online – viagra without prescription
https://sildenafiliq.com/# Generic Viagra for sale
https://kamagraiq.com/# Kamagra tablets
Viagra tablet online: cheap viagra – Cheap Viagra 100mg
super kamagra Kamagra Oral Jelly Price buy kamagra online usa
sandyterrace.com
Fang Jifan은 식량 재배 방법에 관심이 없습니다.
Viagra generic over the counter: cheapest viagra – Cheap Viagra 100mg
cheap kamagra: Sildenafil Oral Jelly – kamagra
https://tadalafiliq.shop/# п»їcialis generic
Currently it seems like Drupal is the top blogging platform out there right now.
(from what I’ve read) Is that what you’re using on your blog?
werankcities.com
Xiao Jing은 Hongzhi 황제가 그를 부르는 것을 듣고 서둘러 앞으로 나아갔습니다. “당신의 하녀가 여기 있습니다.”
Buy Cialis online: cheapest cialis – cheapest cialis
https://tadalafiliq.shop/# Cialis 20mg price in USA
buy Viagra over the counter: generic ed pills – Cheap generic Viagra online
Buy Tadalafil 10mg Generic Tadalafil 20mg price cialis for sale
https://kamagraiq.shop/# п»їkamagra
https://sildenafiliq.com/# Viagra without a doctor prescription Canada
kamagra: Sildenafil Oral Jelly – Kamagra 100mg price
Kamagra Oral Jelly Kamagra Oral Jelly Price Kamagra 100mg price
buy kamagra online usa: Kamagra Iq – Kamagra Oral Jelly
https://indianpharmgrx.com/# india pharmacy
buying prescription drugs in mexico online online pharmacy in Mexico mexican mail order pharmacies
canadian 24 hour pharmacy: Pharmacies in Canada that ship to the US – buy prescription drugs from canada cheap
https://canadianpharmgrx.com/# canada online pharmacy
http://canadianpharmgrx.xyz/# canadian drugs online
WOW just what I was looking for. Came here by
searching for vpn special coupon coupon code 2024
etsyweddingteam.com
このトピックについて詳しく知ることができて良かったです。感謝です。
http://indianpharmgrx.com/# indian pharmacy
Informasi RTP Live Hari Ini Dari Situs RTPKANTORBOLA
Situs RTPKANTORBOLA merupakan salah satu situs yang menyediakan informasi lengkap mengenai RTP (Return to Player) live hari ini. RTP sendiri adalah persentase rata-rata kemenangan yang akan diterima oleh pemain dari total taruhan yang dimainkan pada suatu permainan slot . Dengan adanya informasi RTP live, para pemain dapat mengukur peluang mereka untuk memenangkan suatu permainan dan membuat keputusan yang lebih cerdas saat bermain.
Situs RTPKANTORBOLA menyediakan informasi RTP live dari berbagai permainan provider slot terkemuka seperti Pragmatic Play , PG Soft , Habanero , IDN Slot , No Limit City dan masih banyak rtp permainan slot yang bisa kami cek di situs RTP Kantorboal . Dengan menyediakan informasi yang akurat dan terpercaya, situs ini menjadi sumber informasi yang penting bagi para pemain judi slot online di Indonesia .
Salah satu keunggulan dari situs RTPKANTORBOLA adalah penyajian informasi yang terupdate secara real-time. Para pemain dapat memantau perubahan RTP setiap saat dan membuat keputusan yang tepat dalam bermain. Selain itu, situs ini juga menyediakan informasi mengenai RTP dari berbagai provider permainan, sehingga para pemain dapat membandingkan dan memilih permainan dengan RTP tertinggi.
Informasi RTP live yang disediakan oleh situs RTPKANTORBOLA juga sangat lengkap dan mendetail. Para pemain dapat melihat RTP dari setiap permainan, baik itu dari aspek permainan itu sendiri maupun dari provider yang menyediakannya. Hal ini sangat membantu para pemain dalam memilih permainan yang sesuai dengan preferensi dan gaya bermain mereka.
Selain itu, situs ini juga menyediakan informasi mengenai RTP live dari berbagai provider judi slot online terpercaya. Dengan begitu, para pemain dapat memilih permainan slot yang memberikan RTP terbaik dan lebih aman dalam bermain. Informasi ini juga membantu para pemain untuk menghindari potensi kerugian dengan bermain pada game slot online dengan RTP rendah .
Situs RTPKANTORBOLA juga memberikan pola dan ulasan mengenai permainan-permainan dengan RTP tertinggi. Para pemain dapat mempelajari strategi dan tips dari para ahli untuk meningkatkan peluang dalam memenangkan permainan. Analisis dan ulasan ini disajikan secara jelas dan mudah dipahami, sehingga dapat diaplikasikan dengan baik oleh para pemain.
Informasi RTP live yang disediakan oleh situs RTPKANTORBOLA juga dapat membantu para pemain dalam mengelola keuangan mereka. Dengan mengetahui RTP dari masing-masing permainan slot , para pemain dapat mengatur taruhan mereka dengan lebih bijak. Hal ini dapat membantu para pemain untuk mengurangi risiko kerugian dan meningkatkan peluang untuk mendapatkan kemenangan yang lebih besar.
Untuk mengakses informasi RTP live dari situs RTPKANTORBOLA, para pemain tidak perlu mendaftar atau membayar biaya apapun. Situs ini dapat diakses secara gratis dan tersedia untuk semua pemain judi online. Dengan begitu, semua orang dapat memanfaatkan informasi yang disediakan oleh situs RTP Kantorbola untuk meningkatkan pengalaman dan peluang mereka dalam bermain judi online.
Demikianlah informasi mengenai RTP live hari ini dari situs RTPKANTORBOLA. Dengan menyediakan informasi yang akurat, terpercaya, dan lengkap, situs ini menjadi sumber informasi yang penting bagi para pemain judi online. Dengan memanfaatkan informasi yang disediakan, para pemain dapat membuat keputusan yang lebih cerdas dan meningkatkan peluang mereka untuk memenangkan permainan. Selamat bermain dan semoga sukses!
https://mexicanpharmgrx.com/# best online pharmacies in mexico
werankcities.com
아주 잘생겼어, 의미는… 그냥 뽐내는 거 아니야?
http://canadianpharmgrx.xyz/# reliable canadian pharmacy
pharmacy com canada: Canadian pharmacy prices – vipps canadian pharmacy
sandyterrace.com
그것은 단지 … 이번 베이징 시찰도 Fang Jifan이 대중의 불만을 불러 일으켰습니다.
https://canadianpharmgrx.xyz/# best canadian pharmacy online
mexican rx online mexican pharmacy п»їbest mexican online pharmacies
kantor bola
Mengenal Situs Gaming Online Terbaik Kantorbola
Kantorbola merupakan situs gaming online terbaik yang menawarkan pengalaman bermain yang seru dan mengasyikkan bagi para pecinta game. Dengan berbagai pilihan game menarik dan grafis yang memukau, Kantorbola menjadi pilihan utama bagi para gamers yang ingin mencari hiburan dan tantangan baru. Dengan layanan customer service yang ramah dan profesional, serta sistem keamanan yang terjamin, Kantorbola siap memberikan pengalaman bermain yang terbaik dan menyenangkan bagi semua membernya. Jadi, tunggu apalagi? Bergabunglah sekarang dan rasakan sensasi seru bermain game di Kantorbola!
Situs kantor bola menyediakan beberapa link alternatif terbaru
Situs kantor bola merupakan salah satu situs gaming online terbaik yang menyediakan berbagai link alternatif terbaru untuk memudahkan para pengguna dalam mengakses situs tersebut. Dengan adanya link alternatif terbaru ini, para pengguna dapat tetap mengakses situs kantor bola meskipun terjadi pemblokiran dari pemerintah atau internet positif. Hal ini tentu menjadi kabar baik bagi para pecinta judi online yang ingin tetap bermain tanpa kendala akses ke situs kantor bola.
Dengan menyediakan beberapa link alternatif terbaru, situs kantor bola juga dapat memberikan variasi akses kepada para pengguna. Hal ini memungkinkan para pengguna untuk memilih link alternatif mana yang paling cepat dan stabil dalam mengakses situs tersebut. Dengan demikian, pengalaman bermain judi online di situs kantor bola akan menjadi lebih lancar dan menyenangkan.
Selain itu, situs kantor bola juga menunjukkan komitmennya dalam memberikan pelayanan terbaik kepada para pengguna dengan menyediakan link alternatif terbaru secara berkala. Dengan begitu, para pengguna tidak perlu khawatir akan kehilangan akses ke situs kantor bola karena selalu ada link alternatif terbaru yang dapat digunakan sebagai backup. Keberadaan link alternatif tersebut juga menunjukkan bahwa situs kantor bola selalu berusaha untuk tetap eksis dan dapat diakses oleh para pengguna setianya.
Secara keseluruhan, kehadiran beberapa link alternatif terbaru dari situs kantor bola merupakan salah satu bentuk komitmen dari situs tersebut dalam memberikan kemudahan dan kenyamanan kepada para pengguna. Dengan adanya link alternatif tersebut, para pengguna dapat terus mengakses situs kantor bola tanpa hambatan apapun. Hal ini tentu akan semakin meningkatkan popularitas situs kantor bola sebagai salah satu situs gaming online terbaik di Indonesia. Berikut beberapa link alternatif dari situs kantorbola , diantaranya .
1. Link Kantorbola77
Link Kantorbola77 merupakan salah satu situs gaming online terbaik yang saat ini banyak diminati oleh para pecinta judi online. Dengan berbagai pilihan permainan yang lengkap dan berkualitas, situs ini mampu memberikan pengalaman bermain yang memuaskan bagi para membernya. Selain itu, Kantorbola77 juga menawarkan berbagai bonus dan promo menarik yang dapat meningkatkan peluang kemenangan para pemain.
Salah satu keunggulan dari Link Kantorbola77 adalah sistem keamanan yang sangat terjamin. Dengan teknologi enkripsi yang canggih, situs ini menjaga data pribadi dan transaksi keuangan para membernya dengan sangat baik. Hal ini membuat para pemain merasa aman dan nyaman saat bermain di Kantorbola77 tanpa perlu khawatir akan adanya kebocoran data atau tindakan kecurangan yang merugikan.
Selain itu, Link Kantorbola77 juga menyediakan layanan pelanggan yang siap membantu para pemain 24 jam non-stop. Tim customer service yang profesional dan responsif siap membantu para member dalam menyelesaikan berbagai kendala atau pertanyaan yang mereka hadapi saat bermain. Dengan layanan yang ramah dan efisien, Kantorbola77 menempatkan kepuasan para pemain sebagai prioritas utama mereka.
Dengan reputasi yang baik dan pengalaman yang telah teruji, Link Kantorbola77 layak untuk menjadi pilihan utama bagi para pecinta judi online. Dengan berbagai keunggulan yang dimilikinya, situs ini memberikan pengalaman bermain yang memuaskan dan menguntungkan bagi para membernya. Jadi, jangan ragu untuk bergabung dan mencoba keberuntungan Anda di Kantorbola77.
2. Link Kantorbola88
Link kantorbola88 adalah salah satu situs gaming online terbaik yang harus dikenal oleh para pecinta judi online. Dengan menyediakan berbagai jenis permainan seperti judi bola, casino, slot online, poker, dan banyak lagi, kantorbola88 menjadi pilihan utama bagi para pemain yang ingin mencoba keberuntungan mereka. Link ini memberikan akses mudah dan cepat untuk para pemain yang ingin bermain tanpa harus repot mencari situs judi online yang terpercaya.
Selain itu, kantorbola88 juga dikenal sebagai situs yang memiliki reputasi baik dalam hal pelayanan dan keamanan. Dengan sistem keamanan yang canggih dan profesional, para pemain dapat bermain tanpa perlu khawatir akan kebocoran data pribadi atau transaksi keuangan mereka. Selain itu, layanan pelanggan yang ramah dan responsif juga membuat pengalaman bermain di kantorbola88 menjadi lebih menyenangkan dan nyaman.
Selain itu, link kantorbola88 juga menawarkan berbagai bonus dan promosi menarik yang dapat dinikmati oleh para pemain. Mulai dari bonus deposit, cashback, hingga bonus referral, semua memberikan kesempatan bagi pemain untuk mendapatkan keuntungan lebih saat bermain di situs ini. Dengan adanya bonus-bonus tersebut, kantorbola88 terus berusaha memberikan yang terbaik bagi para pemainnya agar selalu merasa puas dan senang bermain di situs ini.
Dengan reputasi yang baik, pelayanan yang prima, keamanan yang terjamin, dan bonus yang menggiurkan, link kantorbola88 adalah pilihan yang tepat bagi para pemain judi online yang ingin merasakan pengalaman bermain yang seru dan menguntungkan. Dengan bergabung di situs ini, para pemain dapat merasakan sensasi bermain judi online yang berkualitas dan terpercaya, serta memiliki peluang untuk mendapatkan keuntungan besar. Jadi, jangan ragu untuk mencoba keberuntungan Anda di kantorbola88 dan nikmati pengalaman bermain yang tak terlupakan.
3. Link Kantorbola88
Kantorbola99 merupakan salah satu situs gaming online terbaik yang dapat menjadi pilihan bagi para pecinta judi online. Situs ini menawarkan berbagai permainan menarik seperti judi bola, casino online, slot online, poker, dan masih banyak lagi. Dengan berbagai pilihan permainan yang disediakan, para pemain dapat menikmati pengalaman berjudi yang seru dan mengasyikkan.
Salah satu keunggulan dari Kantorbola99 adalah sistem keamanan yang sangat terjamin. Situs ini menggunakan teknologi enkripsi terbaru untuk melindungi data pribadi dan transaksi keuangan para pemain. Dengan demikian, para pemain bisa bermain dengan tenang tanpa perlu khawatir tentang kebocoran data pribadi atau kecurangan dalam permainan.
Selain itu, Kantorbola99 juga menawarkan berbagai bonus dan promo menarik bagi para pemain setianya. Mulai dari bonus deposit, bonus cashback, hingga bonus referral yang dapat meningkatkan peluang para pemain untuk meraih kemenangan. Dengan adanya bonus dan promo ini, para pemain dapat merasa lebih diuntungkan dan semakin termotivasi untuk bermain di situs ini.
Dengan reputasi yang baik dan pengalaman yang telah terbukti, Kantorbola99 menjadi pilihan yang tepat bagi para pecinta judi online. Dengan pelayanan yang ramah dan responsif, para pemain juga dapat mendapatkan bantuan dan dukungan kapan pun dibutuhkan. Jadi, tidak heran jika Kantorbola99 menjadi salah satu situs gaming online terbaik yang banyak direkomendasikan oleh para pemain judi online.
Promo Terbaik Dari Situs kantorbola
Kantorbola merupakan salah satu situs gaming online terbaik yang menyediakan berbagai jenis permainan menarik seperti judi bola, casino, poker, slots, dan masih banyak lagi. Situs ini telah menjadi pilihan utama bagi para pecinta judi online karena reputasinya yang terpercaya dan kualitas layanannya yang prima. Selain itu, Kantorbola juga seringkali memberikan promo-promo menarik kepada para membernya, salah satunya adalah promo terbaik yang dapat meningkatkan peluang kemenangan para pemain.
Promo terbaik dari situs Kantorbola biasanya berupa bonus deposit, cashback, maupun event-event menarik yang diadakan secara berkala. Dengan adanya promo-promo ini, para pemain memiliki kesempatan untuk mendapatkan keuntungan lebih besar dan juga kesempatan untuk memenangkan hadiah-hadiah menarik. Selain itu, promo-promo ini juga menjadi daya tarik bagi para pemain baru yang ingin mencoba bermain di situs Kantorbola.
Salah satu promo terbaik dari situs Kantorbola yang paling diminati adalah bonus deposit new member sebesar 100%. Dengan bonus ini, para pemain baru bisa mendapatkan tambahan saldo sebesar 100% dari jumlah deposit yang mereka lakukan. Hal ini tentu saja menjadi kesempatan emas bagi para pemain untuk bisa bermain lebih lama dan meningkatkan peluang kemenangan mereka. Selain itu, Kantorbola juga selalu memberikan promo-promo menarik lainnya yang dapat dinikmati oleh semua membernya.
Dengan berbagai promo terbaik yang ditawarkan oleh situs Kantorbola, para pemain memiliki banyak kesempatan untuk meraih kemenangan besar dan mendapatkan pengalaman bermain judi online yang lebih menyenangkan. Jadi, jangan ragu untuk bergabung dan mencoba keberuntungan Anda di situs gaming online terbaik ini. Dapatkan promo-promo menarik dan nikmati berbagai jenis permainan seru hanya di Kantorbola.
Deposit Kilat Di Kantorbola Melalui QRIS
Deposit kilat di Kantorbola melalui QRIS merupakan salah satu fitur yang mempermudah para pemain judi online untuk melakukan transaksi secara cepat dan aman. Dengan menggunakan QRIS, para pemain dapat melakukan deposit dengan mudah tanpa perlu repot mencari nomor rekening atau melakukan transfer manual.
QRIS sendiri merupakan sistem pembayaran digital yang memanfaatkan kode QR untuk memfasilitasi transaksi pembayaran. Dengan menggunakan QRIS, para pemain judi online dapat melakukan deposit hanya dengan melakukan pemindaian kode QR yang tersedia di situs Kantorbola. Proses deposit pun dapat dilakukan dalam waktu yang sangat singkat, sehingga para pemain tidak perlu menunggu lama untuk bisa mulai bermain.
Keunggulan deposit kilat di Kantorbola melalui QRIS adalah kemudahan dan kecepatan transaksi yang ditawarkan. Para pemain judi online tidak perlu lagi repot mencari nomor rekening atau melakukan transfer manual yang memakan waktu. Cukup dengan melakukan pemindaian kode QR, deposit dapat langsung terproses dan saldo akun pemain pun akan langsung bertambah.
Dengan adanya fitur deposit kilat di Kantorbola melalui QRIS, para pemain judi online dapat lebih fokus pada permainan tanpa harus terganggu dengan urusan transaksi. QRIS memungkinkan para pemain untuk melakukan deposit kapan pun dan di mana pun dengan mudah, sehingga pengalaman bermain judi online di Kantorbola menjadi lebih menyenangkan dan praktis.
Dari ulasan mengenai mengenal situs gaming online terbaik Kantorbola, dapat disimpulkan bahwa situs tersebut menawarkan berbagai jenis permainan yang menarik dan populer di kalangan para penggemar game. Dengan tampilan yang menarik dan user-friendly, Kantorbola memberikan pengalaman bermain yang menyenangkan dan memuaskan bagi para pemain. Selain itu, keamanan dan keamanan privasi pengguna juga menjadi prioritas utama dalam situs tersebut sehingga para pemain dapat bermain dengan tenang tanpa perlu khawatir akan data pribadi mereka.
Selain itu, Kantorbola juga memberikan berbagai bonus dan promo menarik bagi para pemain, seperti bonus deposit dan cashback yang dapat meningkatkan keuntungan bermain. Dengan pelayanan customer service yang responsif dan profesional, para pemain juga dapat mendapatkan bantuan yang dibutuhkan dengan cepat dan mudah. Dengan reputasi yang baik dan banyaknya testimonial positif dari para pemain, Kantorbola menjadi pilihan situs gaming online terbaik bagi para pecinta game di Indonesia.
Frequently Asked Question ( FAQ )
A : Apa yang dimaksud dengan Situs Gaming Online Terbaik Kantorbola?
Q : Situs Gaming Online Terbaik Kantorbola adalah platform online yang menyediakan berbagai jenis permainan game yang berkualitas dan menarik untuk dimainkan.
A : Apa saja jenis permainan yang tersedia di Situs Gaming Online Terbaik Kantorbola?
Q : Di Situs Gaming Online Terbaik Kantorbola, anda dapat menemukan berbagai jenis permainan seperti game slot, poker, roulette, blackjack, dan masih banyak lagi.
A : Bagaimana cara mendaftar di Situs Gaming Online Terbaik Kantorbola?
Q : Untuk mendaftar di Situs Gaming Online Terbaik Kantorbola, anda hanya perlu mengakses situs resmi mereka, mengklik tombol “Daftar” dan mengisi formulir pendaftaran yang disediakan.
A : Apakah Situs Gaming Online Terbaik Kantorbola aman digunakan untuk bermain game?
Q : Ya, Situs Gaming Online Terbaik Kantorbola telah memastikan keamanan dan kerahasiaan data para penggunanya dengan menggunakan sistem keamanan terkini.
A : Apakah ada bonus atau promo menarik yang ditawarkan oleh Situs Gaming Online Terbaik Kantorbola?
Q : Tentu saja, Situs Gaming Online Terbaik Kantorbola seringkali menawarkan berbagai bonus dan promo menarik seperti bonus deposit, cashback, dan bonus referral untuk para membernya. Jadi pastikan untuk selalu memeriksa promosi yang sedang berlangsung di situs mereka.
http://canadianpharmgrx.com/# canada pharmacy
https://indianpharmgrx.com/# top 10 online pharmacy in india
Online medicine order Generic Medicine India to USA indianpharmacy com
Итак почему наши сигналы – твой лучший вариант:
Мы утром и вечером, днём и ночью в курсе последних трендов и событий, которые оказывают влияние на криптовалюты. Это позволяет команде оперативно реагировать и давать новые сигналы.
Наш состав имеет глубоким знанием технического анализа и способен выделить крепкие и уязвимые факторы для вступления в сделку. Это содействует минимизации рисков и максимизации прибыли.
Мы же внедряем личные боты для анализа данных для просмотра графиков на все временных промежутках. Это помогает нам получить полноценную картину рынка.
Перед приведением сигнал в нашем канале Telegram мы осуществляем педантичную ревизию всех фасадов и подтверждаем возможный период долгой торговли или короткий. Это подтверждает надежность и качество наших подач.
Присоединяйтесь к нашему каналу к нашему прямо сейчас и получите доступ к проверенным торговым сигналам, которые помогут вам добиться финансового успеха на рынке криптовалют!
https://t.me/Investsany_bot
kantor bola
Kantorbola Situs slot Terbaik, Modal 10 Ribu Menang Puluhan Juta
Kantorbola merupakan salah satu situs judi online terbaik yang saat ini sedang populer di kalangan pecinta taruhan bola , judi live casino dan judi slot online . Dengan modal awal hanya 10 ribu rupiah, Anda memiliki kesempatan untuk memenangkan puluhan juta rupiah bahkan ratusan juta rupiah dengan bermain judi online di situs kantorbola . Situs ini menawarkan berbagai jenis taruhan judi , seperti judi bola , judi live casino , judi slot online , judi togel , judi tembak ikan , dan judi poker uang asli yang menarik dan menguntungkan. Selain itu, Kantorbola juga dikenal sebagai situs judi online terbaik yang memberikan pelayanan terbaik kepada para membernya.
Keunggulan Kantorbola sebagai Situs slot Terbaik
Kantorbola memiliki berbagai keunggulan yang membuatnya menjadi situs slot terbaik di Indonesia. Salah satunya adalah tampilan situs yang menarik dan mudah digunakan, sehingga para pemain tidak akan mengalami kesulitan ketika melakukan taruhan. Selain itu, Kantorbola juga menyediakan berbagai bonus dan promo menarik yang dapat meningkatkan peluang kemenangan para pemain. Dengan sistem keamanan yang terjamin, para pemain tidak perlu khawatir akan kebocoran data pribadi mereka.
Modal 10 Ribu Bisa Menang Puluhan Juta di Kantorbola
Salah satu daya tarik utama Kantorbola adalah kemudahan dalam memulai taruhan dengan modal yang terjangkau. Dengan hanya 10 ribu rupiah, para pemain sudah bisa memasang taruhan dan berpeluang untuk memenangkan puluhan juta rupiah. Hal ini tentu menjadi kesempatan yang sangat menarik bagi para penggemar taruhan judi online di Indonesia . Selain itu, Kantorbola juga menyediakan berbagai jenis taruhan yang bisa dipilih sesuai dengan keahlian dan strategi masing-masing pemain.
Berbagai Jenis Permainan Taruhan Bola yang Menarik
Kantorbola menyediakan berbagai jenis permainan taruhan bola yang menarik dan menguntungkan bagi para pemain. Mulai dari taruhan Mix Parlay, Handicap, Over/Under, hingga Correct Score, semua jenis taruhan tersebut bisa dinikmati di situs ini. Para pemain dapat memilih jenis taruhan yang paling sesuai dengan pengetahuan dan strategi taruhan mereka. Dengan peluang kemenangan yang besar, para pemain memiliki kesempatan untuk meraih keuntungan yang fantastis di Kantorbola.
Pelayanan Terbaik untuk Kepuasan Para Member
Selain menyediakan berbagai jenis permainan taruhan bola yang menarik, Kantorbola juga memberikan pelayanan terbaik untuk kepuasan para membernya. Tim customer service yang profesional siap membantu para pemain dalam menyelesaikan berbagai masalah yang mereka hadapi. Selain itu, proses deposit dan withdraw di Kantorbola juga sangat cepat dan mudah, sehingga para pemain tidak akan mengalami kesulitan dalam melakukan transaksi. Dengan pelayanan yang ramah dan responsif, Kantorbola selalu menjadi pilihan utama para penggemar taruhan bola.
Kesimpulan
Kantorbola merupakan situs slot terbaik yang menawarkan berbagai jenis permainan taruhan bola yang menarik dan menguntungkan. Dengan modal awal hanya 10 ribu rupiah, para pemain memiliki kesempatan untuk memenangkan puluhan juta rupiah. Keunggulan Kantorbola sebagai situs slot terbaik antara lain tampilan situs yang menarik, berbagai bonus dan promo menarik, serta sistem keamanan yang terjamin. Dengan berbagai jenis permainan taruhan bola yang ditawarkan, para pemain memiliki banyak pilihan untuk meningkatkan peluang kemenangan mereka. Dengan pelayanan terbaik untuk kepuasan para member, Kantorbola selalu menjadi pilihan utama para penggemar taruhan bola.
FAQ (Frequently Asked Questions)
Berapa modal minimal untuk bermain di Kantorbola? Modal minimal untuk bermain di Kantorbola adalah 10 ribu rupiah.
Bagaimana cara melakukan deposit di Kantorbola? Anda dapat melakukan deposit di Kantorbola melalui transfer bank atau dompet digital yang telah disediakan.
Apakah Kantorbola menyediakan bonus untuk new member? Ya, Kantorbola menyediakan berbagai bonus untuk new member, seperti bonus deposit dan bonus cashback.
Apakah Kantorbola aman digunakan untuk bermain taruhan bola online? Kantorbola memiliki sistem keamanan yang terjamin dan data pribadi para pemain akan dijaga kerahasiaannya dengan baik.
http://canadianpharmgrx.xyz/# canadian pharmacy near me
Итак почему наши сигналы на вход – твой лучший путь:
Мы утром и вечером, днём и ночью в тренде современных направлений и ситуаций, которые влияют на криптовалюты. Это способствует группе незамедлительно отвечать и предоставлять текущие подачи.
Наш коллектив обладает профундным знание технического анализа и умеет выявлять устойчивые и слабые стороны для включения в сделку. Это содействует уменьшению угроз и способствует для растущей прибыли.
Мы используем личные боты-анализаторы для анализа графиков на все временных промежутках. Это помогает нашим специалистам завоевать понятную картину рынка.
Перед приведением сигнал в нашем Telegram мы делаем детальную проверку все сторон и подтверждаем возможный период долгой торговли или краткий. Это обеспечивает надежность и качественные показатели наших подач.
Присоединяйтесь к нашему каналу прямо сейчас и получите доступ к подтвержденным торговым подачам, которые содействуют вам достигнуть финансовых результатов на рынке криптовалют!
https://t.me/Investsany_bot
mexico drug stores pharmacies: online pharmacy in Mexico – pharmacies in mexico that ship to usa
canadian pharmacy world CIPA approved pharmacies canadian pharmacy in canada
http://indianpharmgrx.com/# buy prescription drugs from india
mexico pharmacies prescription drugs: mexican pharmacy – mexican border pharmacies shipping to usa
https://indianpharmgrx.com/# cheapest online pharmacy india
Итак почему наши тоговые сигналы – ваш лучший путь:
Наша команда утром и вечером, днём и ночью в тренде текущих трендов и ситуаций, которые влияют на криптовалюты. Это позволяет коллективу быстро отвечать и подавать свежие трейды.
Наш состав имеет глубинным пониманием анализа и способен обнаруживать мощные и незащищенные факторы для включения в сделку. Это способствует уменьшению угроз и увеличению прибыли.
Вместе с командой мы применяем собственные боты для анализа данных для просмотра графиков на всех интервалах. Это помогает нашим специалистам завоевать полноценную картину рынка.
Перед публикацией сигнал в нашем Telegram команда осуществляем педантичную ревизию все аспектов и подтверждаем возможный период долгой торговли или период короткой торговли. Это обеспечивает верность и качественные показатели наших подач.
Присоединяйтесь к нашей команде к нашему Telegram каналу прямо сейчас и получите доступ к подтвержденным торговым подачам, которые содействуют вам получить успеха в финансах на рынке криптовалют!
https://t.me/Investsany_bot
buy cytotec over the counter: order cytotec online – buy cytotec over the counter
Итак почему наши сигналы на вход – твой идеальный вариант:
Наша команда все время в курсе последних трендов и моментов, которые воздействуют на криптовалюты. Это дает возможность группе мгновенно реагировать и давать свежие сигналы.
Наш коллектив обладает глубинным понимание технического анализа и способен обнаруживать мощные и слабые факторы для включения в сделку. Это способствует для снижения опасностей и способствует для растущей прибыли.
Мы используем личные боты для анализа данных для анализа графиков на все периодах времени. Это помогает нашим специалистам достать полноценную картину рынка.
Перед опубликованием подача в нашем канале Telegram мы осуществляем педантичную проверку все аспектов и подтверждаем возможный длинный или шорт. Это гарантирует верность и качественные характеристики наших сигналов.
Присоединяйтесь к нашему прямо сейчас и достаньте доступ к подтвержденным торговым сигналам, которые содействуют вам достигнуть успеха в финансах на рынке криптовалют!
https://t.me/Investsany_bot
Почему наши сигналы – всегда лучший путь:
Мы все время в курсе актуальных курсов и моментов, которые влияют на криптовалюты. Это позволяет нашему коллективу оперативно действовать и предоставлять новые сообщения.
Наш состав владеет глубоким пониманием анализа и может обнаруживать устойчивые и слабые аспекты для включения в сделку. Это способствует минимизации потерь и увеличению прибыли.
Вместе с командой мы применяем личные боты для анализа для анализа графиков на все интервалах. Это помогает нам получить полноценную картину рынка.
Прежде опубликованием подачи в нашем Telegram мы проводим детальную проверку все фасадов и подтверждаем возможное лонг или шорт. Это гарантирует предсказуемость и качественные показатели наших подач.
Присоединяйтесь к нашему Telegram каналу прямо сейчас и получите доступ к подтвержденным торговым подачам, которые помогут вам вам получить успеха в финансах на рынке криптовалют!
https://t.me/Investsany_bot
alternatives to tamoxifen: tamoxifen benefits – tamoxifen blood clots
buy doxycycline 100mg: buy doxycycline without prescription uk – doxycycline 500mg
antibiotics cipro: cipro generic – ciprofloxacin generic
doxycycline online buy doxycycline monohydrate order doxycycline online
tamoxifen citrate: tamoxifen citrate – where to buy nolvadex
order diflucan: diflucan 200mg tab – diflucan no prescription
Intro
betvisa vietnam
Betvisa vietnam | Grand Prize Breakout!
Betway Highlights | 499,000 Extra Bonus on betvisa com!
Cockfight to win up to 3,888,000 on betvisa game
Daily Deposit, Sunday Bonus on betvisa app 888,000!
#betvisavietnam
200% Bonus on instant deposits—start your win streak!
200% welcome bonus! Slots and Fishing Games
https://www.betvisa.com/
#betvisavietnam #betvisagame #betvisaapp
#betvisacom #betvisacasinoapp
Birthday bash? Up to 1,800,000 in prizes! Enjoy!
Friday Shopping Frenzy betvisa vietnam 100,000 VND!
Betvisa Casino App Daily Login 12% Bonus Up to 1,500,000VND!
Khám phá Thế Giới Cá Cược Trực Tuyến với BetVisa!
Hệ thống BetVisa, một trong những nền tảng hàng đầu tại châu Á, được thành lập vào năm 2017 và thao tác dưới bằng của Curacao, đã có hơn 2 triệu người dùng trên toàn thế giới. Với lời hứa đem đến trải nghiệm cá cược đảm bảo và tin cậy nhất, BetVisa sớm trở thành lựa chọn hàng đầu của người chơi trực tuyến.
BetVisa không chỉ cung cấp các trò chơi phong phú như xổ số, sòng bạc trực tiếp, thể thao trực tiếp và thể thao điện tử, mà còn mang đến cho người chơi những ưu đãi hấp dẫn. Thành viên mới đăng ký sẽ được tặng ngay 5 cơ hội miễn phí và có cơ hội giành giải thưởng lớn.
Đặc biệt, BetVisa hỗ trợ nhiều hình thức thanh toán linh hoạt như Betvisa Vietnam, cùng với các ưu đãi độc quyền như thưởng chào mừng lên đến 200%. Bên cạnh đó, hàng tuần còn có các chương trình khuyến mãi độc đáo như chương trình giải thưởng Sinh Nhật và Chủ Nhật Mua Sắm Điên Cuồng, mang đến cho người chơi cơ hội thắng lớn.
Do sự cam kết về trải nghiệm thú vị cá cược tốt nhất và dịch vụ khách hàng chuyên nghiệp, BetVisa hoàn toàn tự hào là điểm đến lý tưởng cho những ai nhiệt huyết trò chơi trực tuyến. Hãy đăng ký ngay hôm nay và bắt đầu cuộc hành trình của bạn tại BetVisa – nơi niềm vui và may mắn chính là điều tất yếu.
cytotec online: Misoprostol 200 mg buy online – buy cytotec pills online cheap
cytotec abortion pill: buy cytotec – buy cytotec online fast delivery
etsyweddingteam.com
このブログは本当に役立つ情報が満載で、大好きです。
ciprofloxacin mail online buy cipro cheap п»їcipro generic
doxy: doxycycline hydrochloride 100mg – doxycycline hyc 100mg
Intro
betvisa philippines
Betvisa philippines | The Filipino Carnival, Spinning for Treasures!
Betvisa Philippines Surprises | Spin daily and win ₱8,888 Grand Prize!
Register for a chance to win ₱8,888 Bonus Tickets! Explore Betvisa.com!
Wild All Over Grab 58% YB Bonus at Betvisa Casino! Take the challenge!
#betvisaphilippines
Get 88 on your first 50 Experience Betvisa Online’s Bonus Gift!
Weekend Instant Daily Recharge at betvisa.com
https://www.88betvisa.com/
#betvisaphilippines #betvisaonline #betvisacasino
#betvisacom #betvisa.com
BetVisa – Điểm Đến Tuyệt Vời Cho Người Chơi Trực Tuyến
Khám Phá Thế Giới Cá Cược Trực Tuyến với BetVisa!
Dịch vụ được sáng lập vào năm 2017 và hoạt động theo chứng chỉ trò chơi Curacao với hơn 2 triệu người dùng. Với tính cam kết đem đến trải nghiệm cá cược an toàn và tin cậy nhất, BetVisa nhanh chóng trở thành lựa chọn hàng đầu của người chơi trực tuyến.
Nền tảng cá cược không chỉ cung cấp các trò chơi phong phú như xổ số, sòng bạc trực tiếp, thể thao trực tiếp và thể thao điện tử, mà còn mang lại cho người chơi những ưu đãi hấp dẫn. Thành viên mới đăng ký sẽ nhận tặng ngay 5 vòng quay miễn phí và có cơ hội giành giải thưởng lớn.
Dịch vụ hỗ trợ nhiều phương thức thanh toán linh hoạt như Betvisa Vietnam, kết hợp với các ưu đãi độc quyền như thưởng chào mừng lên đến 200%. Bên cạnh đó, hàng tuần còn có chương trình ưu đãi độc đáo như chương trình giải thưởng Sinh Nhật và Chủ Nhật Mua Sắm Điên Cuồng, mang lại cho người chơi thời cơ thắng lớn.
Với sự cam kết về trải nghiệm cá cược tốt nhất và dịch vụ khách hàng chất lượng, BetVisa tự tin là điểm đến lý tưởng cho những ai đam mê trò chơi trực tuyến. Hãy đăng ký ngay hôm nay và bắt đầu hành trình của bạn tại BetVisa – nơi niềm vui và may mắn chính là điều tất yếu!
buy cytotec pills online cheap: Abortion pills online – Abortion pills online
cipro cipro online no prescription in the usa cipro
https://ciprofloxacin.guru/# buy cipro cheap
lexapro and tamoxifen: nolvadex 10mg – buy tamoxifen
rg777
App cá độ:Hướng dẫn tải app cá cược uy tín RG777 đúng cách
Bạn có biết? Tải app cá độ đúng cách sẽ giúp tiết kiệm thời gian đăng nhập, tăng tính an toàn và bảo mật cho tài khoản của bạn! Vậy đâu là cách để tải một app cá cược uy tín dễ dàng và chính xác? Xem ngay bài viết này nếu bạn muốn chơi cá cược trực tuyến an toàn!
tải về ngay lập tức
RG777 – Nhà Cái Uy Tín Hàng Đầu Việt Nam
Link tải app cá độ nét nhất 2023:RG777
Để đảm bảo việc tải ứng dụng cá cược của bạn an toàn và nhanh chóng, người chơi có thể sử dụng đường link sau.
tải về ngay lập tức
App cá độ:Hướng dẫn tải app cá cược uy tín RG777 đúng cách
Bạn có biết? Tải app cá độ đúng cách sẽ giúp tiết kiệm thời gian đăng nhập, tăng tính an toàn và bảo mật cho tài khoản của bạn! Vậy đâu là cách để tải một app cá cược uy tín dễ dàng và chính xác? Xem ngay bài viết này nếu bạn muốn chơi cá cược trực tuyến an toàn!
tải về ngay lập tức
RG777 – Nhà Cái Uy Tín Hàng Đầu Việt Nam
Link tải app cá độ nét nhất 2023:RG777
Để đảm bảo việc tải ứng dụng cá cược của bạn an toàn và nhanh chóng, người chơi có thể sử dụng đường link sau.
tải về ngay lập tức
ciprofloxacin 500mg buy online: buy ciprofloxacin – ciprofloxacin generic
高雄外送茶
現代社會,快遞已成為大眾化的服務業,吸引了許多人的注意和參與。 與傳統夜店、酒吧不同,外帶提供了更私密、便捷的服務方式,讓人們有機會在家中或特定地點與美女共度美好時光。
多樣化選擇
從台灣到日本,馬來西亞到越南,外送業提供了多樣化的女孩選擇,以滿足不同人群的需求和喜好。 無論你喜歡什麼類型的女孩,你都可以在外賣行業找到合適的女孩。
不同的價格水平
價格範圍從實惠到豪華。 無論您的預算如何,您都可以找到適合您需求的女孩,享受優質的服務並度過愉快的時光。
快遞業高度重視安全和隱私保護,提供多種安全措施和保障,讓客戶放心使用服務,無需擔心個人資訊外洩或安全問題。
如果你想成為一名經驗豐富的外包司機,外包產業也將為你提供廣泛的選擇和專屬服務。 只需按照步驟操作,您就可以輕鬆享受快遞行業帶來的樂趣和便利。
蓬勃發展的快遞產業為人們提供了一種新的娛樂休閒方式,讓人們在忙碌的生活中得到放鬆,享受美好時光。
robot88
RG777 Casino
App cá độ:Hướng dẫn tải app cá cược uy tín RG777 đúng cách
Bạn có biết? Tải app cá độ đúng cách sẽ giúp tiết kiệm thời gian đăng nhập, tăng tính an toàn và bảo mật cho tài khoản của bạn! Vậy đâu là cách để tải một app cá cược uy tín dễ dàng và chính xác? Xem ngay bài viết này nếu bạn muốn chơi cá cược trực tuyến an toàn!
tải về ngay lập tức
RG777 – Nhà Cái Uy Tín Hàng Đầu Việt Nam
Link tải app cá độ nét nhất 2023:RG777
Để đảm bảo việc tải ứng dụng cá cược của bạn an toàn và nhanh chóng, người chơi có thể sử dụng đường link sau.
tải về ngay lập tức
Intro
betvisa india
Betvisa india | IPL 2024 Heat Wave
IPL 2024 Big bets, big prizes With Betvisa India
Exclusive for Sports Fans Betvisa Online Casino 50% Welcome Bonus
Crash Game Supreme Compete for 1,00,00,000 pot Betvisa.com
#betvisaindia
Accurate Predictions IPL T20 Tournament, Winner Takes All!
More than just a game | Betvisa dreams invites you to fly to malta
https://www.b3tvisapro.com/
#betvisaindia #betvisalogin #betvisaonlinecasino
#betvisa.com #betvisaapp
D?ch v? – Di?m D?n Tuy?t V?i Cho Ngu?i Choi Tr?c Tuy?n
Kham Pha Th? Gi?i Ca Cu?c Tr?c Tuy?n v?i BetVisa!
N?n t?ng ca cu?c du?c thanh l?p vao nam 2017 va ti?n hanh theo b?ng tro choi Curacao v?i hon 2 tri?u ngu?i dung. V?i tinh cam k?t dem d?n tr?i nghi?m ca cu?c ch?c ch?n va tin c?y nh?t, BetVisa nhanh chong tr? thanh l?a ch?n hang d?u c?a ngu?i choi tr?c tuy?n.
BetVisa khong ch? dua ra cac tro choi phong phu nhu x? s?, song b?c tr?c ti?p, th? thao tr?c ti?p va th? thao di?n t?, ma con mang l?i cho ngu?i choi nh?ng uu dai h?p d?n. Thanh vien m?i dang ky s? nh?n t?ng ngay 5 vong quay mi?n phi va co co h?i gianh gi?i thu?ng l?n.
BetVisa h? tr? nhi?u phuong th?c thanh toan linh ho?t nhu Betvisa Vietnam, ben c?nh cac uu dai d?c quy?n nhu thu?ng chao m?ng len d?n 200%. Ben c?nh do, hang tu?n con co cac chuong trinh khuy?n mai d?c dao nhu chuong trinh gi?i thu?ng Sinh Nh?t va Ch? Nh?t Mua S?m Dien Cu?ng, mang l?i cho ngu?i choi th?i co th?ng l?n.
V?i l?i h?a v? tr?i nghi?m ca cu?c t?t nh?t va d?ch v? khach hang ch?t lu?ng, BetVisa t? tin la di?m d?n ly tu?ng cho nh?ng ai dam me tro choi tr?c tuy?n. Hay dang ky ngay hom nay va b?t d?u hanh trinh c?a b?n t?i BetVisa – noi ni?m vui va may m?n chinh la di?u t?t y?u!
doxycycline hyc 100mg: where can i get doxycycline – doxycycline 100mg dogs
ciprofloxacin generic cipro 500mg best prices п»їcipro generic
cipro for sale: buy generic ciprofloxacin – cipro for sale
JDBslot
JDB slot | The first bonus to rock the slot world
Exclusive event to earn real money and slot game points
JDB demo slot games for free = ?? Lucky Spin Lucky Draw!
How to earn reels free 2000? follow jdb slot games for free
#jdbslot
Demo making money : https://jdb777.com
#jdbslot #slotgamesforfree #howtoearnreels #cashreels
#slotgamepoint #demomakingmoney
Cash reels only at slot games for free
More professional jdb game bonus knowledge
Ways to Earn Spins Points Complimentary 2000: Your Ultimate Handbook to Victorious Big with JDB One-armed bandits
Are you ready to embark on an thrilling adventure into the world of internet slot games? Look no additional, only turn to JDB777 FreeGames, where excitement and significant wins expect you at each turn of the reel. In this all-encompassing handbook, we’ll show you methods to earn reels points complimentary 2000 and release the stimulating world of JDB slots.
Live through the Adrenaline rush of Gaming Games for Free
At JDB777 FreeGames, we supply a broad variety of captivating slot games that are certain to keep you entertained for hours on end. From vintage fruit machines to immersive themed slots, there’s something for each kind of player to enjoy. And the best part? You can play all of our slot games for free and win real cash prizes!
Open Free Cash Reels and Achieve Big
One of the most exciting features of JDB777 FreeGames is the chance to earn reels points complimentary 2000, which can be exchanged for real cash. Easily sign up for an account, and you’ll obtain your free bonus to initiate spinning and winning. With our plentiful promotions and bonuses, the sky’s the restriction when it comes to your winnings!
Direct Strategies and Scores System
To enhance your winnings and open the entire potential of our slot games, it’s crucial to grasp the strategies and points system. Our professional guides will take you through everything you need to know, from choosing out the right games to understanding how to secure bonus points and cash prizes.
Special Promotions and Specific Offers
As a member of JDB777 FreeGames, you’ll have access to exclusive promotions and special offers that are sure to improve your gaming experience. From welcome bonuses to daily rebates, there are lots of chances to enhance your winnings and take your gameplay to the subsequent level.
Join Us Today and Initiate Winning
Don’t miss out on your possibility to win big with JDB777 FreeGames. Sign up now to declare your gratis bonus of 2000 credits and start spinning the reels for your opportunity to win real cash prizes. With our thrilling selection of slot games and generous promotions, the possibilities are endless. Join us today and start winning!
Abortion pills online: cytotec pills online – buy cytotec pills online cheap
diflucan pill price: diflucan over the counter usa – diflucan medication prescription
cipro 500mg best prices buy cipro buy generic ciprofloxacin
doxycycline without prescription: doxycycline generic – doxycycline medication
cipro: cipro for sale – buy ciprofloxacin over the counter
odering doxycycline: doxycycline 100mg price – doxycycline tablets
robot 88
ivermectin lotion cost: ivermectin 4000 – ivermectin where to buy
zithromax 250 mg pill: buy zithromax 500mg online – zithromax cost canada
bestmanualpolesaw.com
Xiao Jing은 잠시 생각에 잠겼고 마침내 “명령을 준수하십시오. “라고 말할 수밖에 없었습니다.
https://clomida.pro/# can i order generic clomid tablets
buy cheap zithromax online zithromax canadian pharmacy zithromax 250mg
zithromax 250 price: where to get zithromax over the counter – generic zithromax online paypal
stromectol medication stromectol buy ivermectin medicine
ivermectin 3mg dosage: stromectol south africa – stromectol 15 mg
Intro
betvisa bangladesh
Betvisa bangladesh | Super Cricket Carnival with Betvisa!
IPL Cricket Mania | Kick off Super Cricket Carnival with bet visa.com
IPL Season | Exclusive 1,50,00,000 only at Betvisa Bangladesh!
Crash Games Heroes | Climb to the top of the 1,00,00,000 bonus pool!
#betvisabangladesh
Preview IPL T20 | Follow Betvisa BD on Facebook, Instagram for awards!
betvisa affiliate Dream Maltese Tour | Sign up now to win the ultimate prize!
https://www.bvthethao.com/
#betvisabangladesh #betvisabd #betvisaaffiliate
#betvisaaffiliatesignup #betvisa.com
Nhờ vào sự cam kết về kinh nghiệm cá cược tinh vi nhất và dịch vụ khách hàng kỹ năng chuyên môn, BetVisa tự tin là điểm đến lý tưởng cho những ai nhiệt huyết trò chơi trực tuyến. Hãy đăng ký ngay hôm nay và bắt đầu chuyến đi của bạn tại BetVisa – nơi niềm vui và may mắn chính là điều không thể thiếu được.
Khám phá Thế Giới Cá Cược Trực Tuyến với BetVisa!
BetVisa Vietnam, một trong những công ty trò chơi hàng đầu tại châu Á, ra đời vào năm 2017 và thao tác dưới bằng của Curacao, đã có hơn 2 triệu người dùng trên toàn thế giới. Với lời hứa đem đến trải nghiệm cá cược an toàn và tin cậy nhất, BetVisa nhanh chóng trở thành lựa chọn hàng đầu của người chơi trực tuyến.
BetVisa không chỉ cung cấp các trò chơi phong phú như xổ số, sòng bạc trực tiếp, thể thao trực tiếp và thể thao điện tử, mà còn mang đến cho người chơi những ưu đãi hấp dẫn. Thành viên mới đăng ký sẽ được tặng ngay 5 phần quà miễn phí và có cơ hội giành giải thưởng lớn.
Đặc biệt, BetVisa hỗ trợ nhiều cách thức thanh toán linh hoạt như Betvisa Vietnam, cùng với các ưu đãi độc quyền như thưởng chào mừng lên đến 200%. Bên cạnh đó, hàng tuần còn có các chương trình khuyến mãi độc đáo như chương trình giải thưởng Sinh Nhật và Chủ Nhật Mua Sắm Điên Cuồng, mang đến cho người chơi cơ hội thắng lớn.
Intro
betvisa vietnam
Betvisa vietnam | Grand Prize Breakout!
Betway Highlights | 499,000 Extra Bonus on betvisa com!
Cockfight to win up to 3,888,000 on betvisa game
Daily Deposit, Sunday Bonus on betvisa app 888,000!
#betvisavietnam
200% Bonus on instant deposits—start your win streak!
200% welcome bonus! Slots and Fishing Games
https://www.betvisa.com/
#betvisavietnam #betvisagame #betvisaapp
#betvisacom #betvisacasinoapp
Birthday bash? Up to 1,800,000 in prizes! Enjoy!
Friday Shopping Frenzy betvisa vietnam 100,000 VND!
Betvisa Casino App Daily Login 12% Bonus Up to 1,500,000VND!
Tìm hiểu Thế Giới Cá Cược Trực Tuyến với BetVisa!
BetVisa, một trong những công ty hàng đầu tại châu Á, được thành lập vào năm 2017 và hoạt động dưới bằng của Curacao, đã đưa vào hơn 2 triệu người dùng trên toàn thế giới. Với cam kết đem đến trải nghiệm cá cược đảm bảo và tin cậy nhất, BetVisa nhanh chóng trở thành lựa chọn hàng đầu của người chơi trực tuyến.
BetVisa không chỉ cung cấp các trò chơi phong phú như xổ số, sòng bạc trực tiếp, thể thao trực tiếp và thể thao điện tử, mà còn mang đến cho người chơi những ưu đãi hấp dẫn. Thành viên mới đăng ký sẽ được tặng ngay 5 phần quà miễn phí và có cơ hội giành giải thưởng lớn.
Đặc biệt, BetVisa hỗ trợ nhiều hình thức thanh toán linh hoạt như Betvisa Vietnam, cùng với các ưu đãi độc quyền như thưởng chào mừng lên đến 200%. Bên cạnh đó, hàng tuần còn có các chương trình khuyến mãi độc đáo như chương trình giải thưởng Sinh Nhật và Chủ Nhật Mua Sắm Điên Cuồng, mang đến cho người chơi cơ hội thắng lớn.
Vì lời hứa về kinh nghiệm cá cược tốt nhất và dịch vụ khách hàng chuyên nghiệp, BetVisa hoàn toàn tự tin là điểm đến lý tưởng cho những ai nhiệt huyết trò chơi trực tuyến. Hãy gắn bó ngay hôm nay và bắt đầu dấu mốc của bạn tại BetVisa – nơi niềm vui và may mắn chính là điều không thể thiếu được.
prednisone 5443: prednisone without prescription medication – average cost of prednisone
JDBslot
JDB slot | The first bonus to rock the slot world
Exclusive event to earn real money and slot game points
JDB demo slot games for free = ?? Lucky Spin Lucky Draw!
How to earn reels free 2000? follow jdb slot games for free
#jdbslot
Demo making money : https://jdb777.com
#jdbslot #slotgamesforfree #howtoearnreels #cashreels
#slotgamepoint #demomakingmoney
Cash reels only at slot games for free
More professional jdb game bonus knowledge
Ways to Acquire Reels Credits Free 2000: Your Final Guide to Winning Substantial with JDB Gaming machines
Are you you prepared to embark on an electrifying expedition into the world of online slot games? Seek no farther, only spin to JDB777 FreeGames, where thrills and big wins expect you at every spin of the reel. In this all-encompassing guide, we’ll reveal you methods to gain reels points gratis 2000 and open the exciting world of JDB slots.
Feel the Thrill of Slot Games for Free
At JDB777 FreeGames, we present a vast range of captivating slot games that are certain to keep you entertained for hours on end. From vintage fruit machines to immersive themed slots, there’s something for each type of player to enjoy. And the greatest part? You can play all of our slot games for free and earn real cash prizes!
Uncover Free Cash Reels and Attain Big
One of the most thrilling features of JDB777 FreeGames is the possibility to secure reels credits gratis 2000, which can be exchanged for real cash. Plainly sign up for an account, and you’ll receive your costless bonus to start spinning and winning. With our liberal promotions and bonuses, the sky’s the limit when it comes to your winnings!
Guide Tactics and Scores System
To enhance your winnings and open the complete potential of our slot games, it’s important to understand the approaches and points system. Our expert guides will take you through everything you require to know, from choosing out the right games to understanding how to secure bonus points and cash prizes.
Exclusive Promotions and Special Offers
As a member of JDB777 FreeGames, you’ll have access to exclusive promotions and special offers that are sure to improve your gaming experience. From welcome bonuses to daily rebates, there are a great deal of chances to improve your winnings and take your gameplay to the upcoming level.
Join Us Today and Start Winning
Don’t miss out on your opportunity to win big with JDB777 FreeGames. Sign up now to claim your gratis bonus of 2000 credits and begin spinning the reels for your possibility to win real cash prizes. With our stimulating range of slot games and generous promotions, the potentialities are endless. Join us today and commence winning!
ivermectin cream 1%: stromectol where to buy – stromectol for head lice
Medications and prescription drug information for consumers and medical health professionals. Online database of the most popular drugs and their side effects, interactions, and use.
SPSW provides news and analysis for leaders in higher education. We cover topics like online learning, policy
http://azithromycina.pro/# where can i get zithromax over the counter
Intro
betvisa india
Betvisa india | IPL 2024 Heat Wave
IPL 2024 Big bets, big prizes With Betvisa India
Exclusive for Sports Fans Betvisa Online Casino 50% Welcome Bonus
Crash Game Supreme Compete for 1,00,00,000 pot Betvisa.com
#betvisaindia
Accurate Predictions IPL T20 Tournament, Winner Takes All!
More than just a game | Betvisa dreams invites you to fly to malta
https://www.b3tvisapro.com/
#betvisaindia #betvisalogin #betvisaonlinecasino
#betvisa.com #betvisaapp
Tìm hiểu Thế Giới Cá Cược Trực Tuyến với BetVisa!
BetVisa, một trong những nền tảng hàng đầu tại châu Á, được thành lập vào năm 2017 và hoạt động dưới bằng của Curacao, đã thu hút hơn 2 triệu người dùng trên toàn thế giới. Với cam kết đem đến trải nghiệm cá cược đảm bảo và tin cậy nhất, BetVisa nhanh chóng trở thành lựa chọn hàng đầu của người chơi trực tuyến.
BetVisa không chỉ cung cấp các trò chơi phong phú như xổ số, sòng bạc trực tiếp, thể thao trực tiếp và thể thao điện tử, mà còn mang đến cho người chơi những ưu đãi hấp dẫn. Thành viên mới đăng ký sẽ được tặng ngay 5 vòng quay miễn phí và có cơ hội giành giải thưởng lớn.
Đặc biệt, BetVisa hỗ trợ nhiều cách thức thanh toán linh hoạt như Betvisa Vietnam, cùng với các ưu đãi độc quyền như thưởng chào mừng lên đến 200%. Bên cạnh đó, hàng tuần còn có các chương trình khuyến mãi độc đáo như chương trình giải thưởng Sinh Nhật và Chủ Nhật Mua Sắm Điên Cuồng, mang đến cho người chơi cơ hội thắng lớn.
Nhờ vào lời hứa về trải nghiệm cá cược hoàn hảo nhất và dịch vụ khách hàng chuyên trách, BetVisa hoàn toàn tự tin là điểm đến lý tưởng cho những ai nhiệt huyết trò chơi trực tuyến. Hãy tham gia ngay hôm nay và bắt đầu chuyến đi của bạn tại BetVisa – nơi niềm vui và may mắn chính là điều không thể thiếu.
etsyweddingteam.com
日々の生活で役立つ実用的な知識を得ることができ、非常に感謝しています。
can i purchase generic clomid without prescription: where can i get generic clomid now – cost of clomid without insurance
Sugar Defender is a dietary supplement that makes claims that it can improve and maintain normal blood sugar levels.
FitSpresso™ is a nutritional supplement that uses probiotics to help you lose weight.
Boostaro is a natural dietary supplement for male health, enhancing circulation and overall bodily functions. Supports wellness with natural ingredients.
Sight Care is a natural formula that can support healthy eyesight by focusing the root of the problem. Sight Care can be useful to make better your vision.
The latest news and reviews in the world of tech, automotive, gaming, science, and entertainment.
clomid without prescription can you buy clomid without dr prescription how to get generic clomid for sale
SFNews is San Francisco
zithromax 250: zithromax antibiotic – buy zithromax online australia
http://onlinepharmacyworld.shop/# canadian pharmacy world coupons
Jeetwin Affiliate
Jeetwin Affiliate
Join Jeetwin now! | Jeetwin sign up for a ?500 free bonus
Spin & fish with Jeetwin club! | 200% welcome bonus
Bet on horse racing, get a 50% bonus! | Deposit at Jeetwin live for rewards
#JeetwinAffiliate
Casino table fun at Jeetwin casino login | 50% deposit bonus on table games
Earn Jeetwin points and credits, enhance your play!
https://www.jeetwin-affiliate.com/hi
#JeetwinAffiliate #jeetwinclub #jeetwinsignup #jeetwinresult
#jeetwinlive #jeetwinbangladesh #jeetwincasinologin
Daily recharge bonuses at Jeetwin Bangladesh!
25% recharge bonus on casino games at jeetwin result
15% bonus on Crash Games with Jeetwin affiliate!
Spin to Gain Genuine Currency and Voucher Codes with JeetWin’s Partner Program
Do you a enthusiast of online gaming? Do you really appreciate the excitement of twisting the roulette wheel and winning huge? If so, subsequently the JeetWin Affiliate Program is great for you! With JeetWin Gaming, you not simply get to partake in thrilling games but as well have the chance to make genuine currency and gift cards simply by endorsing the platform to your friends, family, or digital audience.
How Does Perform?
Signing up for the JeetWin’s Referral Program is quick and effortless. Once you turn into an member, you’ll obtain a special referral link that you can share with others. Every time someone joins or makes a deposit using your referral link, you’ll earn a commission for their activity.
Fantastic Bonuses Await!
As a member of JeetWin’s affiliate program, you’ll have access to a range of captivating bonuses:
Sign Up Bonus 500: Receive a bountiful sign-up bonus of INR 500 just for joining the program.
Deposit Match Bonus: Receive a massive 200% bonus when you deposit and play slot machine and fish games on the platform.
Endless Referral Bonus: Get unlimited INR 200 bonuses and rebates for every friend you invite to play on JeetWin.
Exciting Games to Play
JeetWin offers a diverse range of the most played and most popular games, including Baccarat, Dice, Liveshow, Slot, Fishing, and Sabong. Whether you’re a fan of classic casino games or prefer something more modern and interactive, JeetWin has something for everyone.
Join the Ultimate Gaming Experience
With JeetWin Live, you can enhance your gaming experience to the next level. Participate in thrilling live games such as Lightning Roulette, Lightning Dice, Crazytime, and more. Sign up today and embark on an unforgettable gaming adventure filled with excitement and limitless opportunities to win.
Convenient Payment Methods
Depositing funds and withdrawing your winnings on JeetWin is speedy and hassle-free. Choose from a assortment of payment methods, including E-Wallets, Net Banking, AstroPay, and RupeeO, for seamless transactions.
Don’t Lose on Exclusive Promotions
As a JeetWin affiliate, you’ll receive access to exclusive promotions and special offers designed to maximize your earnings. From cash rebates to lucrative bonuses, there’s always something exciting happening at JeetWin.
Download the App
Take the fun with you wherever you go by downloading the JeetWin Mobile Casino App. Available for both iOS and Android devices, the app features a wide range of entertaining games that you can enjoy anytime, anywhere.
Sign up for the JeetWin Affiliate Program Today!
Don’t wait any longer to start earning real cash and exciting rewards with the JeetWin Affiliate Program. Sign up now and be a member of the thriving online gaming community at JeetWin.
Кухни по индивидуальным размерам от Вита Кухни: идеальное сочетание стиля и функциональности
https://onlinepharmacyworld.shop/# legit non prescription pharmacies
http://medicationnoprescription.pro/# best non prescription online pharmacy
canada prescription: no prescription medicine – prescription online canada
http://medicationnoprescription.pro/# canadian pharmacy without prescription
erection pills online: online erectile dysfunction – erectile dysfunction drugs online
http://edpill.top/# cheapest online ed treatment
cheap ed medicine ed medicine online cheapest online ed meds
buy medications online no prescription: prescription meds from canada – no prescription medicines
http://edpill.top/# order ed pills online
cheap ed drugs: ed prescriptions online – buying erectile dysfunction pills online
Jeetwin Affiliate
Jeetwin Affiliate
Join Jeetwin now! | Jeetwin sign up for a ?500 free bonus
Spin & fish with Jeetwin club! | 200% welcome bonus
Bet on horse racing, get a 50% bonus! | Deposit at Jeetwin live for rewards
#JeetwinAffiliate
Casino table fun at Jeetwin casino login | 50% deposit bonus on table games
Earn Jeetwin points and credits, enhance your play!
https://www.jeetwin-affiliate.com/hi
#JeetwinAffiliate #jeetwinclub #jeetwinsignup #jeetwinresult
#jeetwinlive #jeetwinbangladesh #jeetwincasinologin
Daily recharge bonuses at Jeetwin Bangladesh!
25% recharge bonus on casino games at jeetwin result
15% bonus on Crash Games with Jeetwin affiliate!
Twist to Gain Real Cash and Gift Cards with JeetWin’s Partner Program
Do you a supporter of online gaming? Are you love the adrenaline rush of turning the spinner and succeeding huge? If so, then the JeetWin’s Partner Program is great for you! With JeetWin, you not simply get to experience enthralling games but also have the possibility to generate real cash and gift cards easily by publicizing the platform to your friends, family, or virtual audience.
How Does Operate?
Enrolling for the JeetWin Affiliate Program is speedy and effortless. Once you turn into an partner, you’ll obtain a special referral link that you can share with others. Every time someone signs up or makes a deposit using your referral link, you’ll get a commission for their activity.
Amazing Bonuses Await!
As a member of JeetWin’s affiliate program, you’ll have access to a range of appealing bonuses:
Sign Up Bonus 500: Obtain a liberal sign-up bonus of INR 500 just for joining the program.
Welcome Deposit Bonus: Receive a massive 200% bonus when you deposit and play slot and fishing games on the platform.
Endless Referral Bonus: Earn unlimited INR 200 bonuses and rebates for every friend you invite to play on JeetWin.
Entertaining Games to Play
JeetWin offers a diverse range of the most played and most popular games, including Baccarat, Dice, Liveshow, Slot, Fishing, and Sabong. Whether you’re a fan of classic casino games or prefer something more modern and interactive, JeetWin has something for everyone.
Engage in the Supreme Gaming Experience
With JeetWin Live, you can take your gaming experience to the next level. Participate in thrilling live games such as Lightning Roulette, Lightning Dice, Crazytime, and more. Sign up today and start an unforgettable gaming adventure filled with excitement and limitless opportunities to win.
Convenient Payment Methods
Depositing funds and withdrawing your winnings on JeetWin is speedy and hassle-free. Choose from a assortment of payment methods, including E-Wallets, Net Banking, AstroPay, and RupeeO, for seamless transactions.
Don’t Pass Up on Special Promotions
As a JeetWin affiliate, you’ll obtain access to exclusive promotions and special offers designed to maximize your earnings. From cash rebates to lucrative bonuses, there’s always something exciting happening at JeetWin.
Install the App
Take the fun with you wherever you go by downloading the JeetWin Mobile Casino App. Available for both iOS and Android devices, the app features a wide range of entertaining games that you can enjoy anytime, anywhere.
Sign up for the JeetWin’s Affiliate Scheme Today!
Don’t wait any longer to start earning real cash and exciting rewards with the JeetWin Affiliate Program. Sign up now and be a member of the thriving online gaming community at JeetWin.
Все о современных технологиях
http://medicationnoprescription.pro/# buy pain meds online without prescription
http://onlinepharmacyworld.shop/# canadian pharmacy no prescription needed
Преимущества песка и щебня по ГОСТу: качество и надежность материалов для строительства
ZenCortex Research’s contains only the natural ingredients that are effective in supporting incredible hearing naturally.A unique team of health and industry professionals dedicated to unlocking the secrets of happier living through a healthier body.
FlowForce Max is an innovative, natural and effective way to address your prostate problems, while addressing your energy, libido, and vitality.
canada pharmacy online no prescription: mexico prescription drugs online – mexican pharmacy no prescription
http://onlinepharmacyworld.shop/# canadian pharmacy without prescription
best no prescription pharmacy canadian pharmacy no prescription international pharmacy no prescription
The latest news and reviews in the world of tech, automotive, gaming, science, and entertainment
The Voice of Alaska’s Capital Since 1912 juneau news
PBN sites
We shall build a system of privately-owned blog network sites!
Pros of our private blog network:
We carry out everything so Google doesn’t understand that this is A PBN network!!!
1- We acquire domains from various registrars
2- The main site is hosted on a virtual private server (Virtual Private Server is rapid hosting)
3- Other sites are on distinct hostings
4- We allocate a unique Google profile to each site with confirmation in Search Console.
5- We develop websites on WordPress, we do not use plugins with aided by which malware penetrate and through which pages on your websites are created.
6- We don’t reproduce templates and employ only individual text and pictures
We don’t work with website design; the client, if desired, can then edit the websites to suit his wishes
ZenCortex Research’s contains only the natural ingredients that are effective in supporting incredible hearing naturally.
casino tr?c tuy?n: casino tr?c tuy?n – web c? b?c online uy tín
game c? b?c online uy tín: game c? b?c online uy tín – choi casino tr?c tuy?n trên di?n tho?i
Hi, i believe that i noticed you visited my web site so i got here to go back the prefer?.I am attempting to to find things to improve my
site!I assume its good enough to use a few of your concepts!!
VSDC Free Video Editor: Your Ultimate Tool for Creating Stunning Videos
http://casinvietnam.shop/# casino tr?c tuy?n
Find the latest technology news and expert tech product reviews. Learn about the latest gadgets and consumer tech products for entertainment, gaming, lifestyle and more.
Ландшафтный дизайн: создание гармоничного и уникального окружения
https://casinvietnam.shop/# game c? b?c online uy tin
Market Analyst specializes in must-know news highlights, in-depth analysis, and overviews of companies as well as industries. https://marketanalyst.us/
Green Lovers is dedicated to making news and topics across sustainability and innovation accessible to all. We help bring awareness to global issues and solutions, and hope to inspire you to make simple changes to your daily habits and lifestyle. https://greenlovers.us/
DreamDive specializes in content that sparks conversations around news, entertainment and pop culture. https://dreamdive.us/
Известняковый щебень: применение и разнообразие сортов
casino tr?c tuy?n vi?t nam casino tr?c tuy?n casino online uy tin
bmipas.com
このブログは本当に目から鱗の内容でした。また訪れます。
http://canadaph24.pro/# my canadian pharmacy rx
Благоустройство территории: создание комфортного окружения для жизни и отдыха
http://canadaph24.pro/# canadian pharmacy price checker
Закажите SEO продвижение сайта https://seo116.ru/ в Яндекс и Google под ключ в Москве и по всей России от экспертов. Увеличение трафика, рост клиентов, онлайн поддержка. Комплексное продвижение сайтов с гарантией!
https://canadaph24.pro/# canadian pharmacy online
sandyterrace.com
장황후는 놀라서 말했다: “황제가 어떻게 아십니까…”
https://indiaph24.store/# cheapest online pharmacy india
http://mexicoph24.life/# mexican rx online
thewiin.com
그는 웃음을 참지 못하고 앞으로 걸어나갔다. “이건…먹을 수 있는 건가요?”
http://mexicoph24.life/# purple pharmacy mexico price list
Arctic blast is a powerful formula packed with natural ingredients and can treat pain effectively if you’re struggling with chronic pain. https://arcticblast-us.us/
Bazopril is an advanced blood pressure support formula intended to help regulate blood flow and blood vessel health. https://bazoprilbuynow.us/
https://mexicoph24.life/# buying prescription drugs in mexico online
https://indiaph24.store/# buy medicines online in india
https://canadaph24.pro/# canada online pharmacy
http://indiaph24.store/# online shopping pharmacy india
Rolex watches
Understanding COSC Validation and Its Importance in Watchmaking
COSC Certification and its Strict Standards
COSC, or the Official Swiss Chronometer Testing Agency, is the official Switzerland testing agency that verifies the accuracy and accuracy of wristwatches. COSC accreditation is a symbol of excellent craftsmanship and trustworthiness in timekeeping. Not all timepiece brands pursue COSC certification, such as Hublot, which instead adheres to its own stringent standards with mechanisms like the UNICO calibre, attaining equivalent precision.
The Art of Precision Timekeeping
The core system of a mechanical watch involves the spring, which provides energy as it loosens. This system, however, can be vulnerable to environmental factors that may influence its precision. COSC-validated mechanisms undergo rigorous testing—over fifteen days in various conditions (5 positions, 3 temperatures)—to ensure their durability and reliability. The tests evaluate:
Typical daily rate accuracy between -4 and +6 secs.
Mean variation, peak variation rates, and impacts of temperature changes.
Why COSC Certification Matters
For watch enthusiasts and connoisseurs, a COSC-validated watch isn’t just a item of technology but a proof to enduring excellence and precision. It symbolizes a timepiece that:
Offers exceptional dependability and accuracy.
Offers confidence of quality across the complete construction of the watch.
Is apt to maintain its worth better, making it a sound choice.
Well-known Chronometer Manufacturers
Several famous brands prioritize COSC validation for their watches, including Rolex, Omega, Breitling, and Longines, among others. Longines, for instance, presents collections like the Archive and Spirit, which highlight COSC-accredited movements equipped with innovative substances like silicon equilibrium suspensions to improve resilience and efficiency.
Historical Context and the Evolution of Timepieces
The idea of the chronometer dates back to the need for precise timekeeping for navigation at sea, highlighted by John Harrison’s work in the eighteenth cent. Since the formal establishment of Controle Officiel Suisse des Chronometres in 1973, the certification has become a standard for evaluating the precision of luxury watches, maintaining a tradition of superiority in horology.
Conclusion
Owning a COSC-validated timepiece is more than an aesthetic selection; it’s a commitment to excellence and precision. For those appreciating precision above all, the COSC validation provides peace of thoughts, guaranteeing that each certified watch will perform reliably under various conditions. Whether for individual satisfaction or as an investment decision, COSC-certified timepieces stand out in the world of watchmaking, carrying on a legacy of precise timekeeping.
http://canadaph24.pro/# precription drugs from canada
Nihai Dönemin En Gözde Casino Platformu: Casibom
Casino oyunlarını sevenlerin artık duymuş olduğu Casibom, son dönemde adından genellikle söz ettiren bir bahis ve kumarhane sitesi haline geldi. Ülkemizdeki en başarılı casino platformlardan biri olarak tanınan Casibom’un haftalık göre değişen açılış adresi, sektörde oldukça yenilikçi olmasına rağmen itimat edilir ve kazanç sağlayan bir platform olarak ön plana çıkıyor.
Casibom, yakın rekabeti olanları geride bırakıp eski bahis sitelerinin önüne geçmeyi başarmayı sürdürüyor. Bu alanda uzun soluklu olmak önemlidir olsa da, oyunculardan etkileşimde olmak ve onlara temasa geçmek da eş miktar önemli. Bu aşamada, Casibom’un gece gündüz hizmet veren canlı olarak destek ekibi ile kolayca iletişime geçilebilir olması önemli bir artı getiriyor.
Hızlıca büyüyen oyuncu kitlesi ile dikkat çekici olan Casibom’un arkasındaki başarı faktörleri arasında, sadece ve yalnızca casino ve canlı olarak casino oyunlarına sınırlı olmayan geniş bir servis yelpazesi bulunuyor. Atletizm bahislerinde sunduğu geniş seçenekler ve yüksek oranlar, oyuncuları ilgisini çekmeyi başarmayı sürdürüyor.
Ayrıca, hem sporcular bahisleri hem de kumarhane oyunlar katılımcılara yönlendirilen sunulan yüksek yüzdeli avantajlı ödüller da dikkat çekici. Bu nedenle, Casibom kısa sürede sektörde iyi bir tanıtım başarısı elde ediyor ve büyük bir oyuncuların kitlesi kazanıyor.
Casibom’un kar getiren promosyonları ve ünlülüğü ile birlikte, siteye üyelik nasıl sağlanır sorusuna da bahsetmek gerekir. Casibom’a mobil cihazlarınızdan, PC’lerinizden veya tabletlerinizden web tarayıcı üzerinden kolayca erişilebilir. Ayrıca, sitenin mobil uyumlu olması da büyük önem taşıyan bir fayda sunuyor, çünkü artık pratikte herkesin bir akıllı telefonu var ve bu akıllı telefonlar üzerinden hızlıca giriş sağlanabiliyor.
Hareketli tabletlerinizle bile yolda canlı tahminler alabilir ve yarışmaları canlı olarak izleyebilirsiniz. Ayrıca, Casibom’un mobil cihazlarla uyumlu olması, memleketimizde kumarhane ve kumarhane gibi yerlerin yasal olarak kapatılmasıyla birlikte bu tür platformlara erişimin büyük bir yolunu oluşturuyor.
Casibom’un güvenilir bir casino platformu olması da önemlidir bir avantaj sağlıyor. Belgeli bir platform olan Casibom, duraksız bir şekilde eğlence ve kazanç sağlama imkanı getirir.
Casibom’a üye olmak da oldukça kolaydır. Herhangi bir belge koşulu olmadan ve bedel ödemeden web sitesine kolaylıkla kullanıcı olabilirsiniz. Ayrıca, web sitesi üzerinde para yatırma ve çekme işlemleri için de birçok farklı yöntem bulunmaktadır ve herhangi bir kesim ücreti talep edilmemektedir.
Ancak, Casibom’un güncel giriş adresini izlemek de önemlidir. Çünkü gerçek zamanlı bahis ve kumarhane siteleri popüler olduğu için yalancı web siteleri ve dolandırıcılar da ortaya çıkmaktadır. Bu nedenle, Casibom’un sosyal medya hesaplarını ve güncel giriş adresini periyodik olarak kontrol etmek elzemdir.
Sonuç olarak, Casibom hem emin hem de kazandıran bir kumarhane platformu olarak dikkat çekiyor. Yüksek ödülleri, geniş oyun alternatifleri ve kullanıcı dostu taşınabilir uygulaması ile Casibom, kumarhane hayranları için ideal bir platform sağlar.
https://canadaph24.pro/# safe canadian pharmacies
https://mexicoph24.life/# pharmacies in mexico that ship to usa
Окна для дачи: идеальное решение для комфорта и уюта
http://canadaph24.pro/# canadian pharmacy checker
https://indiaph24.store/# indian pharmacy online
網上賭場
http://mexicoph24.life/# mexican pharmacy
https://indiaph24.store/# legitimate online pharmacies india
http://mexicoph24.life/# mexican pharmacy
https://indiaph24.store/# best india pharmacy
http://indiaph24.store/# indian pharmacy paypal
fpparisshop.com
この記事は私の見方を変えるのに役立ちました。ありがとうございます。
http://indiaph24.store/# indian pharmacies safe
https://mexicoph24.life/# mexico drug stores pharmacies
https://indiaph24.store/# indianpharmacy com
En Son Zamanın En Büyük Popüler Kumarhane Sitesi: Casibom
Bahis oyunlarını sevenlerin artık duymuş olduğu Casibom, nihai dönemde adından çoğunlukla söz ettiren bir şans ve oyun sitesi haline geldi. Ülkemizdeki en iyi kumarhane platformlardan biri olarak tanınan Casibom’un haftalık olarak olarak değişen erişim adresi, sektörde oldukça yenilikçi olmasına rağmen itimat edilir ve kar getiren bir platform olarak öne çıkıyor.
Casibom, muadillerini geride kalarak uzun soluklu casino web sitelerinin üstünlük sağlamayı başarılı oluyor. Bu alanda köklü olmak gereklidir olsa da, oyuncularla iletişimde bulunmak ve onlara temasa geçmek da aynı derecede değerli. Bu noktada, Casibom’un gece gündüz hizmet veren canlı olarak destek ekibi ile kolayca iletişime geçilebilir olması büyük önem taşıyan bir artı sağlıyor.
Hızlıca büyüyen oyuncuların kitlesi ile dikkat çeken Casibom’un arkasındaki başarı faktörleri arasında, sadece ve yalnızca casino ve gerçek zamanlı casino oyunlarına sınırlı olmayan kapsamlı bir hizmetler yelpazesi bulunuyor. Atletizm bahislerinde sunduğu geniş seçenekler ve yüksek oranlar, katılımcıları cezbetmeyi başarmayı sürdürüyor.
Ayrıca, hem atletizm bahisleri hem de kumarhane oyunları oyuncularına yönlendirilen sunulan yüksek yüzdeli avantajlı promosyonlar da dikkat çekiyor. Bu nedenle, Casibom çabucak sektörde iyi bir tanıtım başarısı elde ediyor ve büyük bir katılımcı kitlesi kazanıyor.
Casibom’un kazanç sağlayan ödülleri ve ünlülüğü ile birlikte, siteye abonelik nasıl sağlanır sorusuna da atıfta bulunmak gerekir. Casibom’a mobil cihazlarınızdan, bilgisayarlarınızdan veya tabletlerinizden internet tarayıcı üzerinden kolayca ulaşılabilir. Ayrıca, platformun mobil uyumlu olması da büyük bir artı getiriyor, çünkü şimdi neredeyse herkesin bir cep telefonu var ve bu telefonlar üzerinden kolayca erişim sağlanabiliyor.
Taşınabilir tabletlerinizle bile yolda canlı iddialar alabilir ve yarışmaları gerçek zamanlı olarak izleyebilirsiniz. Ayrıca, Casibom’un mobil uyumlu olması, memleketimizde casino ve oyun gibi yerlerin yasal olarak kapatılmasıyla birlikte bu tür platformlara erişimin büyük bir yolunu oluşturuyor.
Casibom’un emin bir bahis web sitesi olması da önemlidir bir fayda sunuyor. Belgeli bir platform olan Casibom, sürekli bir şekilde eğlence ve kar elde etme imkanı sunar.
Casibom’a kullanıcı olmak da oldukça kolaydır. Herhangi bir belge gereksinimi olmadan ve bedel ödemeden web sitesine rahatça abone olabilirsiniz. Ayrıca, platform üzerinde para yatırma ve çekme işlemleri için de birçok farklı yöntem bulunmaktadır ve herhangi bir kesim ücreti talep edilmemektedir.
Ancak, Casibom’un güncel giriş adresini izlemek de önemlidir. Çünkü gerçek zamanlı iddia ve oyun siteleri moda olduğu için sahte siteler ve dolandırıcılar da görünmektedir. Bu nedenle, Casibom’un sosyal medya hesaplarını ve güncel giriş adresini düzenli aralıklarla kontrol etmek önemlidir.
Sonuç, Casibom hem güvenilir hem de kazanç sağlayan bir kumarhane sitesi olarak dikkat çekiyor. Yüksek promosyonları, geniş oyun seçenekleri ve kullanıcı dostu mobil uygulaması ile Casibom, kumarhane hayranları için ideal bir platform sağlar.
http://mexicoph24.life/# mexico drug stores pharmacies
Как выбрать дренажную помпу: руководство по выбору оптимального решения
https://indiaph24.store/# indian pharmacy online