One of the more interesting and challenging markets that the tech industry continues to focus on is the highly touted Internet of Things, or IoT. The appeal of the market is obvious—at least in theory: the potential for billions, if not trillions, of connected devices. Despite that seemingly incredible opportunity, the reality has been much tougher. While there’s no question that we’ve seen tremendous growth in pockets of the IoT market, it’s fair to say that IoT overall hasn’t lived up to its initial hype.
A big part of the problem is that IoT is not one market. In fact, it’s not even just a few markets. As time has gone on, people are realizing that it’s hundreds of thousands of different markets, many of which only amount to unit shipments measured in thousands or tens of thousands.
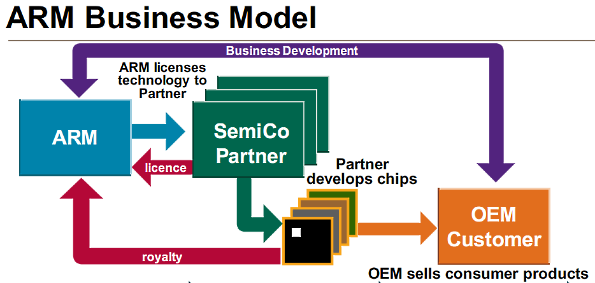
In order to succeed in IoT, therefore, you need the ability to customize on a massive scale. Few companies understand this better than Arm, the silicon IP (intellectual property) and software provider whose designs sit at the heart of an enormous percentage of the chips powering IoT devices. The company has a huge range of designs, from its high-end performance A Series through its mid-range and real-time focused R series, down to its ultra-low power M series, that are used by its hundreds of chip partners to build silicon parts that power an enormous range of different IoT applications.
Even with that diversity, however, it’s becoming clear that more levels of customization are necessary to meet the increasingly specialized needs of the millions of different IoT products. To better address some of those needs, Arm made some important, but easy to overlook, announcements at its annual Arm TechCon developer conference in San Jose this week.
First, and most importantly, Arm announced a new capability to introduce Custom Instructions into its Cortex-M33 and all future Armv8-M series processors at no additional cost, starting in 2020. One of the things that chip and product designers have recognized is that co-processors and other specialized types of silicon, such as AI accelerators, are starting to play an important role in IoT devices. The specialized computing needs that many IoT applications demand are placing strains on the performance and/or power requirements of standard CPUs. As a result, many are choosing to add secondary chips to their designs upon which they can offload specialized tasks. The result is generally higher performance and lower power, but with additional costs and complexities. Most IoT devices are relatively simple, however, and a full co-processor is overkill. Instead, many of these devices require only a few specialized capabilities—such as listening for wake words on voice-based devices—that could be handled by a few instructions. Recognizing that need, Arm’s Custom Instructions addition allows chip and device designers to get the customized benefits of a co-processor built into the main CPU, thereby avoiding the costs and complexities they normally add.
As expected, Arm is providing a software tool that makes the process of creating and embedding custom instructions into chip designs a more straightforward process for those companies who have in-house teams with those skill sets. Not all companies do, however, so Arm will also be offering a library of prebuilt custom instructions, including AI and ML-focused ones, that companies can use to modify their silicon designs.
What’s particularly clever about the new Custom Instructions implementation—and what allowed it to be brought to market so quickly and with no impact to existing software and chip development tools—is that the Custom Instructions go into an existing partition in the CPU’s design. Specifically, they’re replacing instructions that were used to manage a co-processor. However, because the custom instructions essentially allow Arm’s chip design partners to build a mini co-processor onto the Arm core itself, in most situations, there’s no loss in functionality or capability whatsoever.
Of course, there’s more to any device than hardware, and Arm’s core software IoT announcement at TechCon also highlights its desire to offer more customization opportunities for IoT devices. Specifically, Arm announced that it was further opening up the development of its Mbed OS for IoT devices by allowing core partners to help drive its direction. The new MBed OS governance program, which already includes participation from Arm customers such as Samsung, NXP, Cypress and more, will allow more direct involvement of these silicon makers into the future evolution of the OS. This allows them to do things like focus on more low-power battery optimizations for certain types of devices that specific chip vendors need to better differentiate their product offerings.
There’s little doubt that the IoT market will eventually be an enormous one, but there’s also no doubt that the path to reach that size is a lot longer and more complicated than many first imagined. Mass customization of the primary computing components and the software powering these devices is clearly an important step toward those large numbers, and Arm’s IoT announcements from TechCon are an important step in that direction. The road to success won’t be an easy one but having the right tools to succeed on many different paths should clearly help.